
8、对随机森林算法的说法正确的有A.训练可以高度并行化,对于大数据时代的大样本训练速度有优势B.由于采用了随机采样,训练出的模型的方差小,泛化能力强C.对部分特征缺失很敏感D.在某些噪音比较大的样本集上,容易陷入过拟合
题目
8、对随机森林算法的说法正确的有
A.训练可以高度并行化,对于大数据时代的大样本训练速度有优势
B.由于采用了随机采样,训练出的模型的方差小,泛化能力强
C.对部分特征缺失很敏感
D.在某些噪音比较大的样本集上,容易陷入过拟合
相似考题
更多“8、对随机森林算法的说法正确的有A.训练可以高度并行化,对于大数据时代的大样本训练速度有优势B.由于采用了随机采样,训练出的模型的方差小,泛化能力强C.对部分特征缺失很敏感D.在某些噪音比较大的样本集上,容易陷入过拟合”相关问题
-
第1题:
对于随机森林和GradientBoostingTrees,下面说法正确的是()
1.在随机森林的单个树中,树和树之间是有依赖的,而GradientBoostingTrees中的单个树之间是没有依赖的.
2.这两个模型都使用随机特征子集,来生成许多单个的树
3.我们可以并行地生成GradientBoostingTrees单个树,因为它们之间是没有依赖的,GradientBoostingTrees训练模型的表现总是比随机森林好
A.2
B.1and2
C.1,3and4
D.2and4
正确答案:A
-
第2题:
下列说法正确的是( )。
A.样本均值和样本方差是样本统计量
B.样本均值和样本方差是参数
C.样本统计量是随机变量
D.总体参数是一个未知的常数
正确答案:ACD
-
第3题:
若随机变量,从中随机抽取样本,则为( )。A.样本的方差
B. 样本均值
C. 样本均值的方差
D. 样本均值的均值
参考答案:C
-
第4题:
下列属于朴素贝叶斯缺点的是()。A.对缺失数据不太敏感
B.分类效果不稳定
C.先验模型可能导致结果不佳
D.不适合增量式训练
正确答案:AC
-
第5题:
对于随机森林和GradientBoostingTrees,下面说法正确的是:( )A在随机森林的单个树中,树和树之间是有依赖的,而GradientBoostingTrees中的单个树之间是没有依赖的.
B这两个模型都使用随机特征子集,来生成许多单个的树.
C我们可以并行地生成GradientBoostingTrees单个树,因为它们之间是没有依赖的,GradientBoostingTrees训练模型的表现总是比随机森林好
答案:B
-
第6题:
用机械化采样器在静止煤采样,子样在火车车厢的布置可按 ( )
A.三点斜线法
B.五点斜线循环法
C.随机采样法
D.连续采样法和随机采样法
正确答案:C
-
第7题:
从同一正态总体中随机抽取多个样本,用样本均数来估计总体均数的可信敬意,下列哪一样本得到的估计精度高:A.标准差小的样本
B.标准误大的样本
C.均数小的样本
D.均数大的样本
E.标准误小的样本答案:E解析: -
第8题:
下列关于截面数据的说法错误的是( )。A.截面数据是一批发生在同一时间截面上的调查数据
B.截面数据要求样本与母体一致
C.用截面数据作样本,容易使模型随机干扰项产生异方差
D.用截面数据作样本,可以与母体不一致答案:D解析:截面数据是一批发生在同一时间截面上的调查数据。用截面数据作为计量经济学模型的样本数据,应注意以下问题:①样本与母体的一致性问题。计量经济学模型的参数估计,从数学上讲,是用从母体中随机抽取的个体样本估计母体的参数,要求母体与个体必须是一致的。例如,估计煤炭企业的生产函数模型,只能用煤炭企业的数据作为样本,不能用煤炭行业的数据。那么,截面数据就很难用于一些总量模型的估计,例如,建立煤炭行业的生产函数模型,就无法得到合适的截面数据。②模型随机误差项的异方差问题。用截面数据作样本,容易引起模型随机误差项产生异方差。 -
第9题:
随机样本:3,4,2计算的样本方差等于1,则随机样本:12,16,8的样本方差等于( )。
A. 1 B. 2
C. 4 D. 16答案:D解析:。随机样本:12,16,8的每一个值是随机样本:3,4,2的4倍,因此其方差为16倍。 -
第10题:
分层抽样要求A.样本含量应等于随机抽样1.5倍
B.层内变异小
C.层间变异大,层内变异小
D.层内变异大
E.各层的特征等于总体的特征答案:C解析: -
第11题:
在相同样本量下,有放回简单随机抽样比不放回的估计量方差要大,精度要低。
正确答案:正确 -
第12题:
判断题在相同样本量下,有放回简单随机抽样比不放回的估计量方差要大,精度要低。A对
B错
正确答案: 错解析: 暂无解析 -
第13题:
以下关于敏感性训练的说法正确的是( )。
A.强调的是训练的内容
B.是对感情上的训练
C.强调训练的过程
D.是对思想上的训练
E.直接训练管理者对他人的敏感性
正确答案:BCE
敏感性训练是指直接训练管理人员对其他人的敏感性的培训,它强调的不是训练的内容,而是训练的过程;不是思想上的训练,而是感情上的训练。 -
第14题:
对应GradientBoostingtree算法,以下说法正确的是()
1.当增加最小样本分裂个数,我们可以抵制过拟合
2.当增加最小样本分裂个数,会导致过拟合
3.当我们减少训练单个学习器的样本个数,我们可以降低variance
4.当我们减少训练单个学习器的样本个数,我们可以降低bias
A.2和4
B.2和3
C.1和3
D.1和4
正确答案:C
-
第15题:
下列选项中,不是对支持向量机的描述的是?()A.以结构风险最小为原则
B.训练数据较小
C.对于复杂的非线性的决策边界的建模能力高度准确,并且也不太容易过拟合
D.在线性的情况下,就在原空间寻找两类样本的最优分类超平面
正确答案:B
-
第16题:
以下有关特征数据归一化的说法错误的是:( )A.特征数据归一化加速梯度下降优化的速度
B.特征数据归一化有可能提高模型的精度
C.线性归一化适用于特征数值分化比较大的情况
D.概率模型不需要做归一化处理
答案:C
-
第17题:
对应GradientBoostingtree算法,以下说法正确的是:( )A.当增加最小样本分裂个数,我们可以抵制过拟合
B.当增加最小样本分裂个数,会导致过拟合
C.当我们减少训练单个学习器的样本个数,我们可以降低variance
D.当我们减少训练单个学习器的样本个数,我们可以降低bias
答案:AC
-
第18题:
甲和乙入选学校的定点投篮大赛,他们每天训练后投10个球测试,记录命中的个数,五天后记录的数据绘制成折线统计图,则下列对甲、乙数据的描述正确的是()。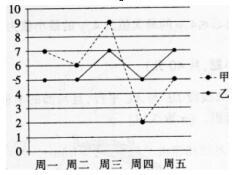 A.甲的方差比乙的方差小
A.甲的方差比乙的方差小
B.甲的方差比乙的方差大
C.甲的平均数比乙的平均数小
D.甲的平均数比乙的平均数大答案:B解析:方差的大小反映数据的稳定性,甲的数据稳定性差,因此甲的方差大。通过计算,甲乙的平均数相等。故正确答案为B。 -
第19题:
当模型中解释变量间存在高度的多重共线性时( )。A.各个解释变量对被解释变量的影响将难以精确鉴别
B.部分解释变量与随机误差项之间将高度相关
C.估计量的精度将大幅度下降
D.估计对于样本容量的变动将十分敏感
E.模型的随机误差项也将序列相关答案:A,C,D解析: -
第20题:
单样本F检验对于数据分布有哪些前提要求?( )A.所有的差异分数是从正态分布的差异总体中随机抽取的
B.所有的样本都从正态分布的总体中随机抽取
C.所有的样本都从正态分布的总体中随机抽取,且方差同质
D.样本从二项分布的总体中随机抽取答案:C解析:本题旨在考查考生对于t检验知识点的理解和把握程度。t检验、z检验和后面涉及的F检验都要求数据是来自正态分布的总体.而且要求数据方差同质。故本题的正确答案是C。 -
第21题:
从全球化对组织的影响来看,服装、包装食品产业的企业可以通过满足本国消费者的特殊需求取得成功。下列关于这类产业的特征,说法正确的有( )。A.全球化压力大
B.全球化压力小
C.本土化压力大
D.本土化压力小答案:B,C解析:服装、包装食品产业的全球化压力小、本土化压力大,企业可以通过满足本国消费者的特殊需求取得成功。 -
第22题:
在计量经济研究中,产生异方差性的原因主要有()。
- A、模型中遗漏了某些解释变量
- B、模型函数形式的设定误差
- C、样本数据的测量误差
- D、随机因素的影响
- E、非随机因素的影响
正确答案:A,B,C,D -
第23题:
判断题随机森林中的每棵树都不进行剪枝,因此过拟合的风险很高。A对
B错
正确答案: 错解析: 暂无解析 -
第24题:
多选题以下有关随机森林算法的说法正确的是()A随机森林算法的分类精度不会随着决策树数量的增加而提高
B随机森林算法对异常值和缺失值不敏感
C随机森林算法不需要考虑过拟合问题
D决策树之间相关系数越低、每棵决策树分类精度越高的随机森林模型的分类效果越好
正确答案: A,D解析: 暂无解析