
假设某程序语言的文法如下:S→SaT|TT→TbR|RT→PdR|P P→fSg|e其中:VT={a,b,d,e,f,g},VN{S,T,R,P},S是开始符号。那么,此方法是(38 方法。这种文法的语法分析通常采用优先矩阵,优先矩阵给出了该文法中各个终结符之间的优先关系 (大于,小于,等于,无关系)。在上述文法中,某些终结符之间的优先关系如下:b(39)a:f(40)g;a(41)a;d(42)d。A.正规文法B.算符文法C.二义文法D.属性文法
题目
假设某程序语言的文法如下:
S→SaT|T
T→TbR|R
T→PdR|P P→fSg|e
其中:VT={a,b,d,e,f,g},VN{S,T,R,P},S是开始符号。那么,此方法是(38 方法。这种文法的语法分析通常采用优先矩阵,优先矩阵给出了该文法中各个终结符之间的优先关系 (大于,小于,等于,无关系)。在上述文法中,某些终结符之间的优先关系如下:
b(39)a:f(40)g;a(41)a;d(42)d。
A.正规文法
B.算符文法
C.二义文法
D.属性文法
相似考题
更多“假设某程序语言的文法如下:S→SaT|TT→TbR|RT→PdR|P P→fSg|e 其中:VT={a,b,d,e,f,g},VN{S,T,R,P},S ”相关问题
-
第1题:
假设某程序语言的文法如下:S→A|B|(T),T→TDS|S,考察该文法的句型(SD(T)DB),其中:素短语是哪个()。AS
BB
C(T)
DSD(T)
正确答案:C
-
第2题:
文法G=(VT,VN,P,S)的类型由C中的(32)决定。若GO=({a,b},{S,X,Y},P,S),P中的产生式及其序号如下:
1:S→XaaY
2:X→Dqb
3:Y→XbXla
则GO为(33)型文法,对应于(34),由GO推导出句子aaaaa和baabbb时,所用产生式序号组成的序列分别为(35)和(36)。
A.VT
B.VN
C.P
D.S
正确答案:C
-
第3题:
考查下列文法:
G(VT,VN,E,P)
其中:Vsub>T={+,*,(,),i);VN={E,T,F};E是开始符号;P为:
E→E+T|T
T→T*F|F
F→(E)|i
F*F+T是该文法的一个句型,其中(1)是句柄,(2)是素短语,(3)是该句型的直接推导,(4)是该句型的最左推导,(5)是该文法的一个句子。
A.F
B.F*F
C.F+T
D.F*F+T
正确答案:A
-
第4题:
已知G4=(VT{a,',',(,)},VN={S,L,L'},S,P),其中P为, S→(L)|a|ξ L→SL' L'→,SL'|ξ FOLLOW(S)是(29)。
A.{',',ξ,}}
B.{','#,}}
C.{a,','ξ,}}
D.{a,',',#}
正确答案:B
解析:终结符A的FOLLOW集合定义如下:FOLLOW(A)={a|S…Aa…,a∈VT,A∈VN},若S…A,则规定#∈FOLLOW(A),约定#为句子结束标记。给定一个文法,求FOLLOW(A)的算法如下:①对于文法的开始符号S,置#于FOLLOW(S)中;②若A→αBβ∈P,则把FIRST(β)中的所有非∈—元素都加至FOLLOW(B)中;③若A→αB∈P,或A→αBβ∈P而βξ,则把FOLLOW(A)加至FOLLOW(B)中。重复使用上述3条规则,直到每个FOLLOW集合不再增大为止。非形式地说,一个非终结符的FOLLOW集合,就是从文法开始符号可以推导出的所有含A句型中紧跟在A之后的所有终结符号。首先,因为S是开始符号,所以,置#于FOLLOW(S)中。根据L→SL',把FIRST(L')中的所有非ξ一元素都加至FOLLOW(S)中,即把','加至FOLLOW(S)中。又根据L→SL'和L'ξ,把FOLLOW(L)加至FOLLOW(S)中,即把')'加至FOLLOW(S)中。最后,FOLLOW(S)为{#,',',)}。 -
第5题:
已知文法G1=(VT={a,b,d},VN={S,A,B},S,P),其中P为: S→dAB A→aA|a B→bB|ε 该文法属于(28)文法。
A.0型
B.上下文有关
C.上下文无关
D.正规
正确答案:C
解析:乔姆斯基(Chomsky)把文法分成4种类型,即0型、1型、2型和3型,由此产生的语言分别称为0型、1型、2型和3型语言。这几类文法的差别在于对产生式的形式施加不同的限制,如下表所示。0型文法也称短语文法,1型文法也称上下文有关文法,2型文法也称上下文无关文法,2型文法的识别器模型是下推自动机。3型文法也称线性文法(或称正规文法),其识别器模型是有限状态自动机。文法G1的所有产生式形式都是A→β,其中A∈VN,β∈V*,且第1条规则S→dAB是非线性的,因此文法G1属于2型文法,又称上下文无关文法。 -
第6题:
已知文法G2=(VT={a,',',(,)},VN={S,L),S,P),其中P为 S→(L)|a L→-L,s|s 与G2等价的不含左递归规则的文法是(29)。
A.G21=(VT={a,',',(,)},VN={S,L},S,P),其中P为 S→(L)|a L→S,S|S
B.G22=(VT<a,',',(,)},VN={S,L,L'},S,P),其中P为 S→(L)|a L→SL' L'→SL'|ε
C.G23=(VT{a,',',(,)},VN={S,L,L'},S,P),其中P为 S→(L)|a L→SL' U→,SL'|ε
D.G24=(VT=(a,',',(,)},VN=<S,L,L'},S,P),其中P为 S→(L)|a L→SL' L→SL'|S
正确答案:C
解析:采用自顶向下的预测分析法首先是等价改写给定的文法,消除文法的左递归和提取产生式的公共左因子。消除直接左递归的方法如下:若A→Aα|β,其中α,β∈(VT∪VN)*,β不以A开始,则关于A的这种形式的产生式可改写成A→βA'A'→αA'|ε一般而言,假设A的产生式为A→Aα1|Aα2|…|Aαn|β1|β2|…|βm其中αI(i=1,2,…,n)不等于ε,βj(j=1,2,…,m)不以A开始,那么上述产生式可改成A→β1A'|β2A'|…|βmA'A'→α1A'|α2A'|…|αnA'|ε消除文法G2中规则的左递归后,其规则变成S→(L)|aL→SL'L'→,SL'|ε -
第7题:
考察下列文法:G(VT,VN,E,P)
其中:VT={+,*,(,),i}
VN={E,T,F}
E是开始符号;
P:
E→E+T|T
T→T*F|F
F→(E)|i
F*F+T是该文法的一个句型,其中(53)是句柄,(54)是素短语。(55)是该句型的直接推导,(56)是该句型的最左推导。(57)是该文法的一个句子。
A.F
B.F*F
C.F+T
D.F*F+T
正确答案:A
-
第8题:
考查文法:G(VT,VN,E,P)
其中,VT={+,*,(,),i},VN={E,T,F},E为开始符。
P:E→E+T|T
T→T*F|P
F→(E)|i
F*F+T是该文法的一个句型,在此句型中,(27)是句柄,(28)是该句型的直接推导,(29)该句型的最左推导。
A.F
B.F*F
C.F+T
D.F*F+T
正确答案:A
-
第9题:
设语言L={w|w∈{a,b}+且w中a和b的个数相等},产生语言L的上下文无关文法是(28)。
A.Ga=(VT={a,b},VN={S,A,B},S,P),其中P为, S→a|aA|bSS A→aB|bS B→b|bA|aBB
B.Gb=(VT={a,b},VN={S,A,B},S,P),其中P为, S→b|bB|aSS B→aS|bA A→a|aB|bAA
C.Gc=(VT={a,b},VN{S,A,B},S,P),其中P为, S→aB|bA A→a|aS|bAA B→b|bS|aBB
D.Gd=(VT={a,b},VN={S,A,B},S,P),其中P为, S→aB|bA|s A→aS|bAA B→bS|aBB
正确答案:C
解析:字母表{a,b}上的任何非空串,从其所含a和b的个数来划分,分成下面3个集合:①a和b的个数相等:②a比b的个数多,但仅要a比b的个数多1个的那些子串;③b比a的个数多,但仅要b比a的个数多1个的那些子串。通过上面的分析,根据用文法规则产生句子的原理,设3个非终结符号,不妨称做S、A、B,它们的产生式分别完成:①用S的产生式推导出a和b的个数相等的串;②用A的产生式推导出a比b的个数多1个的串;③用B的产生式推导出b比a的个数多1个的串。根据3个非终结符号S、A、B的含义,显然,关于S的产生式应该是S→aB|bA。对于A产生的串,若第1个字符是a,则剩下的是a和b的个数相等的串:若第1个字符是b,则跟随b的是a比b的个数多2个的串,这个串是两个a比b的个数多1个的子串。根据上述分析,写出关于A的产生式A→a|aS|bAA。可以通过和A类似的分析,写出关于B的产生式B→b|bS|aBB。可以用归纳法证明上面所写的文法是正确的。现在,我们很清楚被选答案中的4个文法所描述的语言,它们分别是:L(Ga)={w|w∈{a,b}+且w中a比b的个数多一个}L(Gb)={w|w∈{a,b}+且w中b比a的个数多一个}L(Gc)={w|w∈{a,b}+且w中a和b的个数相等}L(Gd)={w|w∈{a,b}+且w中a和b的个数相等} -
第10题:
己知文法G2=(VT={a,',',(,)},VN={S,L},S,P),其中P为, S→(L)|a L→L,S|S 右句型(L,(L,S))的句柄是(28)。
A.(L,(L,S))
B.(L,S)
C.L,S
D.S
正确答案:C
解析:在自底向上分析的过程中,按最右推导的逆过程构造出最右推导,称为规范归约。关键是每步找出被归约的右句型的“可归约串”,称为“句柄”。请读者仔细领会句柄的定义。右句型(最右推导推导出的句型)γ的句柄是一个产生式A→β以及γ中的一个位置,根据这个位置可找到β,用A代替β得到最右推导的前一个右句型。即如果有下面的最右推导:SaAwaβw那么,在a后A→β是aβw的句柄。句柄右边的w仅含终结符号。有的教课书上,句柄的定义借助于短语、直接短语的定义给出:设G=(VT,VN,S,P)足一个文法,若SaAγaβγ则在句型aβγ中,β是相对于非终结符号A的短语。又若SaAγaβγ则在句型αβγ中,β是相对于非终结符号A的直接短语,最左边的直接短语称为句柄。根据句型(L,(L,S))的最右推导:S(L,(L))(L,(L,S))(此步最右推导使用规则S→L,S)因此,(L,(L,S)中的L,S是句型(L,(L,S))的句柄。 -
第11题:
已知文法G1=(VT={a,b,d},VN={S,A,B},S,P),其中P为, S→dAB A→aA|a B→bB|ε 该文法生成的语言是(28)。
A.{dambn|m≥0,n≥O}
B.{dambn|m≥1,n≥0}
C.{dambn|m≥0,n≥1}
D.{dambn|m≥1,n≥1}
正确答案:B
解析:已知文法G=(VT,VN,S,P),它所产生的语言定义如下:若有S(11)w,则称w是文法G的一个句型。仅含终结符的句型是一个句子。语言L(G)是由文法G产生的所有句子组成的集合:L(G)={w|Sw且w∈VT*}推导的定义如下:设文法G=(VT,VN,S,P),A→β∈P,γ,δ∈V*,则稀γAδ直接推导出γβδ,表示成这个定义告诉我们,若知道γAδ∈V*,根据A→β∈,可求出γβδ∈V*,方法是用A→β的右部β替换γAδ中的A得到γβδ;相反,若知道γβδ∈V*,根据A→β∈P,可求出γAδ∈V*,方法是用A→p的左部A替换γβδ中的β得到γAδ。若存在一个推导序列:,则称从a0经n步推导出an,表示成根据文法G1的第1条规则S→dAB知道,文法G1产生的句子的第1个字符是d,后跟着由A产生的终结字符串,再后边跟着由B产生的终结字符串。根据文法G1的第2条规则A→aA|a知道,由A产生的终结字符串是{am|m1};根据B的规则B→bB|ε知道,由B产生的终结字符串是{bn|0}。因此,L(G1)={dambn|m1,n0}。 -
第12题:
单选题文法G://S→S+T|TT→T*P|PP→(S)|i句型P+T+i的短语有()Ai,P+T
BP,P+T,i,P+T+i
CP+T+i
DP,P+T,i
正确答案: B解析: 暂无解析 -
第13题:
已知文法G2=(VT={a,',',(,)},VN={S,L),S,P),其中P为,
S→(L)|a
L→L,S|S
(a,a)是L(G2)的句子,这个句子的分析树是(28)。
A.
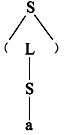
B.
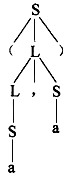
C.
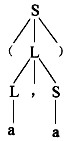
D.
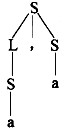 正确答案:B
正确答案:B
解析:根据推导构造分析树,已知文法G[S],对于w,若w∈L(G),则存在一个推导序列Sw。分析树的构造步骤如下所述。首先,设置以开始符号S为标识的根结点,然后,对进行的每一步推导,根据使用的产生式,生成一个子树,直至推导结束。设推导使用的产生式为A→x1x2…xn,则生成以A为根结点,从左至右标识为x1,x2,…,xn的子结点的一棵子树。例如,对于本题的文法G2和句子(a,a),其推导和构造分析树的过程如下:S(L)(L,S)(S,S)(a,S)(a,a)S→(L)L→L,SL→SS→aS→a上面构造树的过程是从树根开始,每进行一步推导,就生出某一子树的子结点,直至推导结束。这种画树过程是从树根到树叶。对于一个w,我们把构造Sw称作句法(语法)分析,上面这种分析过程称为自项向下分析。 -
第14题:
假设某程序语言的文法如下:
S→SaT|T
T→TbR|R
R→PdR|P
P→fSg|e
其中Vr={a,b,d,e,f,g};Vn={S,T,R,P};S是开始符号,那么,此文法是(43)文法。这种文法的语法分析通常采用优先矩阵。优先矩阵给出了该文法中各个终结符之间的优先关系(大于、小于、等于和无关系)。在上述文法中,某些终结符之间的优先关系如下:b{(44)}a;f{(45)}g;a{(46)}a;d{(47)}d。
A.五则文法
B.算符文法
C.二义文法
D.属性文法
正确答案:B
-
第15题:
假设某程序语言的文法如下:
S→a|b|(T)
T→TdS|S
其中:VT={a,b,d,(,)},VN{S,T},S是开始符号。
考查该文法,称句型(Sd(T)db)是S的一个(33),其中,(34)是句柄:(35)是素短语;(36)是该句型的直接短语;(37)是短语。
A.最左推导
B.最右推导
C.规范推导
D.推导
正确答案:D
-
第16题:
已知文法G2=(VT={a,b},VN={S,A},S,P),其中P为, S→Sb|Ab A→aSb|ε 该文法生成的语言是(28)。
A.{ambn|n>m≥0}
B.{ambn|m>n≥0}
C.{ambn|n≥m≥1}
D.{ambn|m≥n≥1}
正确答案:A
解析:根据文法G2的产生式A→aSb|ε,用A的产生式推导出终结符号串,如果仅用A→ε,则产生{ε};如果先用若干次A→aSb推导,再用A→ε,则推导过程如下:因此,由A生成的终结符号集合是{ambm|m>0}。从S出发使用产生式S→Sb|Ab进行推导,或者。最后,L(G2)={ambm|m0}连接{bk|k>0}={ambm+k|m+k>m0}={ambn|n>m0}。 -
第17题:
设有关系模式W(C,P,S,G,T,R),其中各属性的含义足:C—课程,P—教师,S—学生,G—成绩,T—时间,R—教室,根据语义有如下数据依赖集
D={C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R}关系模式w的一个码(关键字)是(40),w的规范化程度最高达到(41)。
A.(S,C)
B.(T,R)
C.(T,P)
D.(T,S)
正确答案:D
-
第18题:
文法G=(VT,VN,P,S)的类型由G中的(21)决定。若GO=({a,b},{S,X, Y},P,S),P中的产生式及其序号如下:
1:S→XaaY
2:X→YY|b
3:Y→XbX|a
则GO为(22)型文法,对应于(23),由GO推导出句子aaaa和baabbb时,所用产生式序号组成的序列分别为(24)和(25)。
A.VT
B.VN
C.P
D.S
正确答案:C
-
第19题:
假设某程序语言的文法如下:
S→a|b|(T)
T→TdS|S
其中,VT={a,b,d,(,));VN={S,T},S是开始符号。考察该文法,句型(Sd(T)db)是S的一个(28)。
其中(29)是最左素短语,(30)是该句型的直接短语。
(74)
A.最左推导
B.最右摊导
C.规范推导
D.推导
正确答案:D
-
第20题:
已知G4=(VT{a,',',(,)},VN={S,L,L'},S,P),其中P为, S→(L)|a|ε L→SL' L'→,SL'|ε FIRST(SL')是(29)。
A.{',',ε}
B.{(,a}
C.{(,a,',')
D.{(,a,',' ,ε)
正确答案:D
解析:FIRST(α)的定义如下:FIRST(α)={a|αa…,a∈VT},若αs,则规定ε∈FIRST(α)。从上面定义可以看出,FLRST(α)是从α推导出来的终结符号集合。从SL'推导出的终结符号集合首先包括从S推导出来的终结符号。因为S的规则是S→(L)|a|ε,因此,从S推导出来的终结符号有‘(’和‘a’。又因为Sε,因此,FIRST(SL')中也包括从L'推导出来的终结符号。根据L'→,SL'|ε,从L'推导出来的终结符号是','。最后,SL'ε,则ε∈FIRST(SL')。 -
第21题:
已知文法G2=(VT={a,',',(,)},VN{S,L},S,P),其中P为, S→(L)|a L→L,S|S (a,(a,a))是L(G2[S])的句子,这个句子的最左推导是(28)
A.
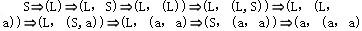
B.
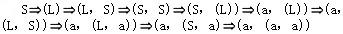
C.
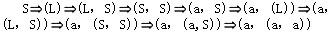
D.
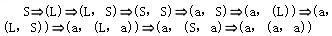 正确答案:C
正确答案:C
解析:设文法G=(VT,VN,S,P),A→β∈P,γ,δ∈V*,则称γAδ直接推导出γβδ,表示成:γAδγβδ也称γβδ直接归约到γAδ。对于以上公式,若γ∈VT*,即A是γAδ中最左边的非终结符号,则称以上公式是一个最左推导。若Sa的每一步都是最左推导,则称Sa是一个最左推导,a称为一个左句型。对于以上公式,若δ∈VT*,即A是γAδ中最右边的非终结符号,则称以上公式是一个最右推导。若Sa的每一步都是最右推导,则称Sa是一个最右推导,a称为一个右句型。最右推导也称作规范推导,右句型也称作规范句型。对于句子(a,(a,a)),被选择答案中A是最右推导,C是最左推导,B和D的推导序列中,既有最左推导,又有最右推导。 -
第22题:
考查下列文法:C(VT,VN,E,P)
其中:VT={+,*,(,),i}
VN={E,T,F}
E是开始符号
P:
E→E+T|T
T→T*F|F
F→(E)|i
F*F+T是该文法的一个句型,其中,(61)是句柄,(62)是素短语。(63)是该句型的直接推导,(64)是该句型的最左推导。(65)是该文法的一个句子。
A.F
B.F*F
C.F+T
D.F*F+,T
正确答案:A
-
第23题:
文法G://S→S+T|TT→T*P|PP→(S)|i句型P+T+i的短语有()
- A、i,P+T
- B、P,P+T,i,P+T+i
- C、P+T+i
- D、P,P+T,i
正确答案:B