
假设字符a,b,c,d,e,f的应用频率分别是0.07,0.09,0.12,0.22,0.23,0.27,则c的Huffman(哈夫曼)编码为(51)。A.110B.001C.10D.11
题目
假设字符a,b,c,d,e,f的应用频率分别是0.07,0.09,0.12,0.22,0.23,0.27,则c的Huffman(哈夫曼)编码为(51)。
A.110
B.001
C.10
D.11
相似考题
更多“假设字符a,b,c,d,e,f的应用频率分别是0.07,0.09,0.12,0.22,0.23,0.27,则c的Huffman(哈夫曼)编码 ”相关问题
-
第1题:
哈夫曼编码是一种最优的前缀码。对一个给定的字符集及其字符频率,其哈夫曼编码不一定是唯一的,但是每个字符的哈夫曼码的长度一定是唯一的。()此题为判断题(对,错)。
答案:错
解析:哈夫曼码是唯一的,但长度可以重复。二叉树根节点到每个叶节点的最短路径是唯一的,但是完全可以有两个叶节点到根节点的距离相同。
-
第2题:
给定5个字符a~f,它们的权值集合W={2,3,4,7,8,9},试构造关于W的一棵哈夫曼树,求其带权路径长度WPL和各个字符的哈夫曼树编码。正确答案:
-
第3题:
关于编码有下述说法:
①对字符集进行编码时,如果字符集中任一字符的编码都是其它字符的编码的前缀,则称这种编码称为前缀编码。
②对字符集进行编码时,要求字符集中任一字符的编码都不是其它字符的编码的后缀,这种编码称为后缀编码。
③不存在既是前缀编码又是后缀编码的编码。
④哈夫曼编码属于前缀编码。
⑤哈夫曼编码属于后缀编码。
⑥哈夫曼编码对应的哈夫曼树是正则二叉树。
其中正确的是(13)。
A.①③④⑥
B.②④⑥
C.②③④⑥
D.①④⑥
正确答案:B
解析:前缀编码要求字符集中任一字符的编码都不是其它字符的编码的前缀,类似地,后缀编码要求字符集中任一字符的编码都不是其它字符的编码的后缀。因此①是错误的,②是正确的。存在既是前缀编码又是后缀编码的编码,比如01、10、111,因此③是错的。哈夫曼编码属于前缀编码,其对应的哈夫曼树没有度为1的结点,因此哈夫曼树是正则二叉树。于是④、⑥正确,⑤错误。 -
第4题:
JPEG建议使用两种熵编码方法,分别是(50)。
A.哈夫曼编码和自适应二进制算术编码
B.哈夫曼编码和LZW编码
C.RLE编码和LZW编码
D.LZW编码和自适应二进制算术编码
正确答案:A
解析:本题考查JPEG编码中的熵编码方法。在JPEG标准的压缩算法中,为了进一步达到压缩数据的目的,需要对量化后的DC码和AC行程编码的码字再作基于统计特性的熵编码。JPEG建议使用两种熵编码方法:哈大曼(Huffman)编码和自适应二进制算术编码(Adaptive Binary Arithmetic Coding)。熵编码可以分两步进行,首先把DC码和行程码字转换成一个中间符号序列,然后给这些符号赋以变长码字。 -
第5题:
已知一个文件中出现的各字符及其对应的频率如下表所示。若采用定长编码,则该文件中字符的码长应为 (64) 。若采用Huffman编码,则字符序列“face”的编码应为 (65) 。

A.2
B.3
C.4
D.5
正确答案:B
本题考查Huffman编码的相关知识。字符在计算机中是用二进制表示的,每个字符用不同的二进制编码来表示。码的长度影响存储空间和传输效率。若是定长编码方法,用2位码长,只能表示4个字符,即00、01、10和11;若用3位码长,则可以表示8个字符,即000、001、010、O11、100、101、110、111。对于题中给出的例子,一共有6个字符,因此采用3位码长的编码可以表示这些字符。Huffman编码是一种最优的不定长编码方法,可以有效的压缩数据。要使用Huffman编码,除了知道文件中出现的字符之外,还需要知道每个字符出现的频率。下图(a)是题干中给出对应的编码树,可以看到,每个字符及其对应编码为图(b),因此字符序列“face”的编码应为110001001101,即65选择A。 -
第6题:
设有一份电文中共使用a、b、c、d、e、f这6个字符,它们的出现频率如下表所示,现通过构造哈夫曼树为这些字符编码。那么,编码长度最长的两个字符是( )。 A.c、e
A.c、e
B.b、e
C.b、f
D.e、f答案:C解析:构造最优二叉树的哈夫曼算法如下。① 根据给定的n个权值{W1, W2,…,Wn}构成n棵二叉树的集合F= {T1,T2,…,Tn},其中每棵树Ti中只有一个带权为Wi的根结点,其左右子树均空。② 在F中选取两棵根结点的权值最小的树作为左右子树,构造一棵新的二叉树,置新构造二叉树的根结点的权值为其左、右子树根结点的权值之和。③从F中删除这两棵树,同时将新得到的二叉树加入到F中。重复②、③,直到F中只含一棵树时为止。这棵树便是最优二叉树(哈夫曼树)。从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径,路径上的分支数目称为路径长度。树的路径长度是从树根到每一个结点的路径长度之和。树的带权路径长度为树中所有叶子结点的带权路径长度之和。根据算法,那么最长的路径应该就是b、f。 -
第7题:
关于哈夫曼树,下列说法正确的是()。A.在哈夫曼树中,权值相同的叶子结点都在同一层上
B.在哈夫曼树中,权值较大的叶子结点一般离根结点较远
C.哈夫曼树是带权路径长度最短的树,路径上权值较大的结点离根较近
D.在哈夫曼编码中,当两个字符出现频率相同时,其编码也相同,对于这种情况应作特殊外理答案:C解析:哈弗曼编码中不允许出现两个字符编码相同的情况。 -
第8题:
已知一个文件中出现的各个字符及其对应的频率如下表所示。若采用Huffman编码,则字符序列“bee”的编码应为( )。 A.01011011101
A.01011011101
B.10011011101
C.10111011101
D.010111101011答案:C解析:① 有6个不同字母,需要采用3位二进制进行编码。② 本题对应的哈夫曼树如下所示:
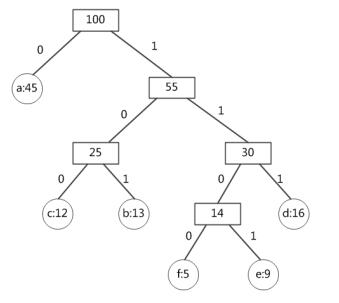
-
第9题:
哈夫曼编码
正确答案: 一种广泛应用而且非常有效的数据压缩编码。 -
第10题:
假设用于通讯的电文仅由6个字符组成,字母在电文中出现的频率分别为7,19,22,6,32,14。若为这6个字母设计哈夫曼编码(设生成新的二叉树的规则是按给出的次序从左至右的结合,新生成的二叉树总是插入在最右),则频率为7的字符编码是()。
- A、00
- B、01
- C、10
- D、11
- E、011
- F、110
- G、1110
- H、1111
正确答案:G -
第11题:
单选题在数据压缩编码的应用中,哈夫曼(Huffman)算法是一种采用了()思想的算法。A贪心
B分冶
C递推
D回溯
正确答案: A解析: 暂无解析 -
第12题:
问答题假设通信用的报文由9个字母A、B、C、D、E、F、G、H和I组成,它们出现的频率分别是:10、20、5、15、8、2、3、7和30。请请用这9个字母出现的频率作为权值求:写出每个字符的哈夫曼编码。正确答案: 每个字符的哈夫曼编码为:A:100,B:11,C://1010,D://000,E://0010,F://10110,G://10111,H:0011,I:01。解析: 暂无解析 -
第13题:
有一分电文共使用5个字符;a,b,c,d,e,它们的出现频率依次为 4、 7、 5、 2、9,试构造哈夫曼树,并给出每个字符的哈夫曼编码。参考答案: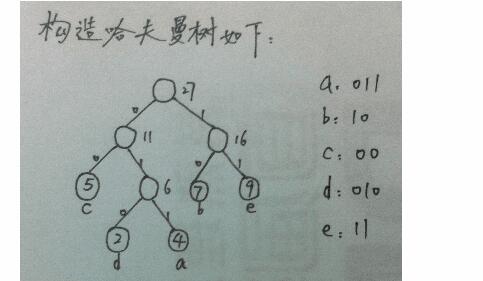
-
第14题:
根据使用频率为5个字符设计的哈夫曼编码不可能是()。A.0000010100111
B.00000001001011
C.000001011011
D.00100101110111
参考答案:D
-
第15题:
若一棵哈夫曼(Huffman)树共有9个顶点,则其叶子节点的个数为(15)。
A.4
B.5
C.6
D.7
正确答案:B
解析:哈夫曼首先给出了对于给定的叶子数目及其权值构造最优二叉树的方法,根据这种方法构造出来的二叉树称为哈夫曼树。假设有n个权值,则构造出的哈夫曼树有n个叶子节点。N个权值分别设为w1,w2,…,wn,则哈夫曼树的构造规则如下。第一步:将w1,w2,…,wn看成是有n棵树的森林;第二步:在森林中选出两个根节点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根节点权值为其左右子树根节点权值之和;第三步:从森林中删除选取的两棵树,并将新树加入森林:第四步:重复第二步和第三步,直到森林中只剩一棵树为止,该树即为所求的哈夫曼树。从以上构造过程可知,哈夫曼树是严格的二叉树,没有度数为1的分支节点。n个叶子的哈夫曼树要经过n-1次合并,产生n-1个新节点,最后求得的哈夫曼树中共有2n-1个节点。 -
第16题:
常用的统计编码方法包括哈夫曼编码和算术编码,其中(41)。
A.算术编码需要传送码表,哈夫曼编码采用0到1之间的实数进行编码
B.哈夫曼编码需要传送码表,算术编码采用0到1之间的实数进行编码
C.哈夫曼编码需要传送码表,并且采用0到1之间的实数进行编码
D.算术编码需要传送码表,并且采用0到1之间的实数进行编码
正确答案:B
解析:统计编码又称为熵压缩法,它的理论依据是信息熵,用这种压缩方法可以无失真地恢复原始数据,并且在编码的过程中不会丢失信息量,但通常压缩比较低。常用的统计编码方法包括哈夫曼编码和算术编码。哈夫曼编码方法中,根据符号的概率大小确定编码。霍夫曼编码的码长是可变的,但在传输过程中不需要附加同步代码,只需要根据码表依次进行编码即可。哈夫曼编码中编码位数都是整数位,编码效率不能达到最优。而算术编码则用0到 1之间的实数对消息进行编码。算术编码用到的两个基本参数是符号出现的概率和它的编码间隔。 -
第17题:
常用的统计编码方法包括哈夫曼编码和算术编码,其中()是正确的。A.算述编码需要传送码表,并且采用0到1之间的实数进行编码
B.哈夫曼编码需要传送码表,并且采用0到1之间的实数进行编码
C.算术编码需要传送码表,哈夫曼编码采用0到1之间的实数进行编码
D.哈夫曼编码需要传送码表,算术编码采用0到1之间的实数进行编码答案:D解析: -
第18题:
有关哈夫曼编码方法,以下说法正确的是 ( )A.哈夫曼编码是一种用于校验的编码方法
B.编码过程中需要根据符号出现的概率来进行编码
C.编码过程中需要建立"词典"
D.哈夫曼编码方法不能用于静态图像压缩答案:B解析:本题考查无损压缩技术中的哈夫曼编码的基本概念。哈夫曼编码属于熵编码,是建立在信源的统计特性之上的无损压缩编码技术,按照信源符号出现的频度或概率排序后递归地自底向上建立编码树,即可得到变长编码。除熵编码外,词典编码也属于无损压缩编码,其基本思想是利用数据本身包含有重复代码这个特性。静态图像的压缩编码可以采用无损压缩编码或有损压缩编码方法,需要视具体需求进行选择。 -
第19题:
已知一个文件中出现的各个字符及其对应的频率如下表所示。若采用定长编码,则该文件中字符的码长应为(64)。若采用Huffman编码,则字符序列“face”的编码应为(65)。
 A.2
A.2
B.3
C.4
D.5答案:B解析:①有6个不同字母,需要采用3位二进制进行编码。
②哈夫曼静态编码:它对需要编码的数据进行两遍扫描:第一遍统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并必须把树的信息保存起来,即把字符0~255(28=256)的频率值以2~4BYTES的长度顺序存储起来,(用4Bytes的长度存储频率值,频率值的表示范围为0~232-1,这已足够表示大文件中字符出现的频率了。)以便解压时创建同样的哈夫曼树进行解压;第二遍则根据第一遍扫描得到的哈夫曼树进行编码,并把编码后得到的码字存储起来。 -
第20题:
在数据压缩编码的应用中,哈夫曼(Huffman)算法是一种采用了()思想的算法。
- A、贪心
- B、分冶
- C、递推
- D、回溯
正确答案:A -
第21题:
在哈夫曼编码中,当两个字符出现的频率相同时,其编码也相同,对于这种情况应作特殊处理。
正确答案:错误 -
第22题:
判断题在哈夫曼编码中,当两个字符出现的频率相同时,其编码也相同,对于这种情况应作特殊处理。A对
B错
正确答案: 对解析: 暂无解析 -
第23题:
单选题假设用于通讯的电文仅由6个字符组成,字母在电文中出现的频率分别为7,19,22,6,32,14。若为这6个字母设计哈夫曼编码(设生成新的二叉树的规则是按给出的次序从左至右的结合,新生成的二叉树总是插入在最右),则频率为7的字符编码是()。A00
B01
C10
D11
E011
F110
G1110
H1111
正确答案: D解析: 暂无解析