
试题一(共15 分 )阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。【 说明 】下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子
题目
试题一(共15 分 )
阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。
【 说明 】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B 的下标,k为指定关键词出现的次数。

相似考题
更多“ 试题一(共15 分 )阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。【 说明 】下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,”相关问题
-
第1题:
阅读下列说明和流程图,将应填入(n)的字句写在对应栏内。
【说明】
下列流程图(如图4所示)用泰勒(Taylor)展开式
sinx=x-x3/3!+x5/5!-x7/7!+…+(-1)n×x2n+1/(2n+1)!+…
【流程图】
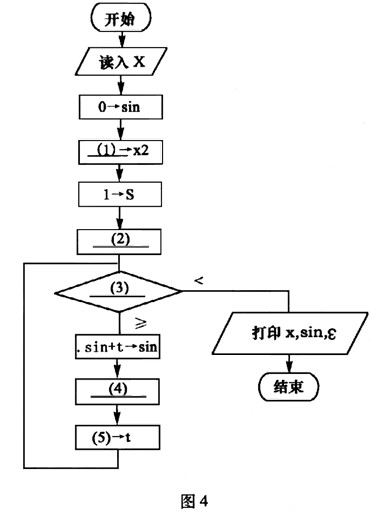
计算并打印sinx的近似值。其中用ε(>0)表示误差要求。
正确答案:(1)x*x (2)x->t (3)│t│:ε (4)s+2->s (5)(-1) * t* x2/(s* (s-1))
(1)x*x (2)x->t (3)│t│:ε (4)s+2->s (5)(-1) * t* x2/(s* (s-1)) 解析:该题的关键是搞清楚几个变量的含义。很显然变量t是用来保存多项式各项的值,变量s和变量x2的作用是什么呢?从流程图的功能上看,需要计算11、3!、5!,……,又从变量s的初值置为1可知,变量s主要用来计算这此数的阶乘的,但没有其他变量用于整数自增,这样就以判断s用来存储奇数的,即s值依次为1、3、5,……。但x2的功能还不明确,现在可以不用管它。
(2)空的作用是给t赋初值,即给它多项式的第一项,因此应填写“x->t”。(3)空处需填写循环条件,显然当t的绝对值小于ε(>0)就表示已经达到误差要求,因此(3)空应填入“│t│:ε”。由变量s的功能可知,(4)空应当实现变量s的增加,因此(4)空应填入“s+2->s”。 (5)空应当是求多项式下一项的值,根据多项式连续两项的关系可知,当前一项为t时,后一项的值为(-1)*t*x*x/(s*(s-1))。但这样的话,每次循环都需要计算一次x*x,计算效率受到影响,联想到变量x2还没用,这时就可以判断x2就是用来存储x*x的值,使得每次循环者少进行一次乘法运算。因此(1)空处应填入“x*x”,(5)空处应填入“(-1)*t*x2/(s*(s-1))”。 -
第2题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
下列流程图用泰勒(Taylor)展开式y=ex=1+x+x2/2!+x3/3!+…+xn/n!+…计算并打印ex的近似值,其中用ε(>0)表示误差要求。
【流程图】
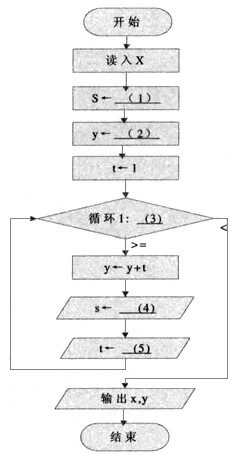 正确答案:(1)0 (2)0 (3)|t|:ε (4)s+1 (5)t*x/s
正确答案:(1)0 (2)0 (3)|t|:ε (4)s+1 (5)t*x/s
(1)0 (2)0 (3)|t|:ε (4)s+1 (5)t*x/s 解析:本题考查程序流程图的内容。
首先让我们来了解一下题目的真正含义,题目要求用泰勒展开式计算y=ex的近似值。并且给出了误差要求,只要当误差小于ε时,就可以输出计算结果了。泰勒展开式的式子是n项之和,每多加一项,其值就越接近真实值。因此,在程序设计时,每加一项之前,先进行此项与ε的比较,来判定计算结果是否已满足题目要求。
从流程图中看到有S、y、t、x这几个变量。其中x、y是公式中的变量,而S、t则是中间变量。从y←y+t语句可以看出,t是每次要加的项,S则是帮助t改变的变量。在计算开始前,我们应该将y的值赋为零,因此,第(2)空答案就为0;而S在t没发生变化的初值也应该是0,即第(1)空答案为0。
第(3)空处是个条件判断语句,应该是进行该加项与ε比较判断,因此第(3)空的答案是|t|:ε。
第(4)空与第(5)空要一起考虑。由于S是帮助t改变的变量,而t的每次改变是分母乘以一个加1的数,而分子乘以x。这里假设S是帮助t改变分母的变量,第(4)空应填s+1,那么第(5)空应该为t*x/s。 -
第3题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
[说明]
下面的流程图实现了正整数序列{K(1),K(2),…,K(n)}的重排,得到的新序列中,比K(1)小的数都在K(1)的左侧,比K(1)大的数都在K(1)的右侧。以n=6为例,序列{12,2,9,13,21,8}的重排过程为:
{12,2,9,13,21,8}
→{2,12,9,13,21,8}
→{9,2,12,13,21,8}
→{8,9,2,12,13,21}
[流程图]
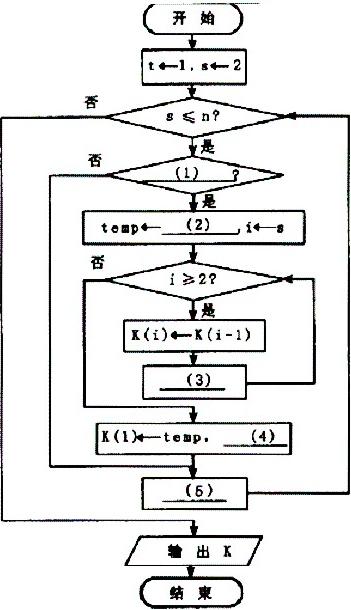 正确答案:(1) K(s)K(t) (2) K(s) (3) i←i-1 (4) t←t+1 (5) s←s+1
正确答案:(1) K(s)K(t) (2) K(s) (3) i←i-1 (4) t←t+1 (5) s←s+1
(1) K(s)K(t) (2) K(s) (3) i←i-1 (4) t←t+1 (5) s←s+1 解析:算法中变量K(t)始终代表原始序列中的K(1)值,t则代表它在当前序列中的位置编号,初始值为1; k(s)代表待比较的数。算法首先拿K(t)和其后的数做比较,若K(s)比K(t)小,则K(s)移至序列的最左侧,同时顺次把第i,is位的元素向右移一位。让s自增1,重复这一步骤,直至到达序列末端(即s=n)为止。 -
第4题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
[说明]
下面的流程图用于计算一个英文句子中最长单词的长度(即单词中字母个数)MAX。假设该英文句子中只含字母、空格和句点“.”,其中句点表示结尾,空格之间连续的字母串称为单词。
[流程图]
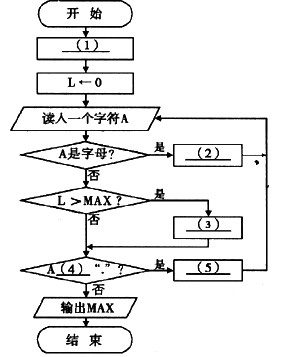 正确答案:(1)MAX←0 (2)←L+1 (3)MAX←L (4)≠ (5)L←0
正确答案:(1)MAX←0 (2)←L+1 (3)MAX←L (4)≠ (5)L←0
(1)MAX←0 (2)←L+1 (3)MAX←L (4)≠ (5)L←0 解析:本题用到的三个变量及其作用分别为:A,存放输入的一个字符;MAX,存放当前为止最长单词的长度;L,存放当前单同的长度。
(1)使用变量MAX应先赋予初值,由上下文知其初值为0;
(2)读取当前单词时,每读人一个字母,单词长度值L应增1;
(3)当前单词长度L比MAX时,应更新MAX的值;
(4)若当前字符不是句点,应当继续读取字符;
(5)读取下一个单词前,应当重置L的值。 -
第5题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
设学生(学生数少于50人)某次考试的成绩按学号顺序逐行存放于某文件中,文件以单行句点“.”为结束符。下面的流程图用于读取该文件,并把全部成绩从高到低排序到数组B[50]中。
【流程图】
 正确答案:(1)B[0]←a (2)i←0 (3)a="." (4)aB[j] (5)j--
正确答案:(1)B[0]←a (2)i←0 (3)a="." (4)aB[j] (5)j--
(1)B[0]←a (2)i←0 (3)a="." (4)aB[j] (5)j-- 解析:本题考查用程序流程图来描述排序。
题目要求将文件中学生的成绩读出,并把全部成绩从高到低排序到数组B[50]中。这里面涉及两个问题,第一是从文件中读数,文件中的数据是以单行句点“.”为结束符的,在未读到此符号前,应该将继续取数据。第二是排序,每取到一个学生的成绩都要与数组的学生成绩比较,按照从高到低的顺序在数组中找到合适的位置存放。下面来具体分析流程图。
第(1)空在条件判断为假的情况下执行流程中,如果条件为假说明从文件中取到的数据是学生成绩。从程序流程图中可以看到,从文件中读的数据存放在变量a中,而此空是第一次取数据,应该存放数组B的第一个位置,因此此空答案为B[0]←a。
第(2)空是紧接着第(1)空来的,在上面已经把从文件中读到的第一个数存放到了数组中,接下来应该处理数组的下标问题,从后面的流程中可以推断出变量i是存放数组当前下标的,而且没有初值,那么此空的任务应该是用来给变量i赋一个初值,而对数组的操作应该从头开始,因此此空答案为i←0。
第(3)空是循环的判断条件,如果条件成立则结束,在这之前又对文件进行了一次读数,根据我们上面的分析只有在读到了结束符时程序才结束,那么此空肯定是判断从文件中读到的数据是否为结束符,因此此空答案为a="."?。
第(4)空也是一个循环的判断条件,如果条件成立,则将取到的数存放到数组的当前下标位置;如果不成立,则循环找到合适的位置再存放。从这里我们不难推断出,流程图中是将从文件取到的成绩与当前数组中的最小成绩进行比较的,而当前数组中的最小成绩存放在位置j中,因此此空答案为aB[i]?。
第(5)空在循环体中,这个循环的作用是为当前从文件中读到的成绩在已经排好序的数组元素中找到合适的位置,找到了就要插入,数组中的元素是按从大到小排列的,在查找合适位置时是从后往前依次比较,因此此空的任务应该是将数组的下标往前移动,所以此空答案为“i--”。 -
第6题:
●试题二
阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
该程序运行后,输出下面的数字金字塔

【程序】
include<stdio.h>
main ()
{char max,next;
int i;
for(max=′1′;max<=′9′;max++)
{for(i=1;i<=20- (1) ;++i)
printf(" ");
for(next= (2) ;next<= (3) ;next++)
printf("%c",next);
for(next= (4) ;next>= (5) ;next--)
printf("%c",next);
printf("\n");
}
}
正确答案:
●试题二【答案】(1)(max-′0′)(2)′1′(3)max(4)max-1(5)′1′【解析】该程序共有9行输出,即循环控制变量max的值是从1~9。每行输出分3部分,先用循环for语句输出左边空白,(1)空填"(max-′0′)";再用循环输出从1到max-′0′的显示数字,即(2)空和(3)空分别填1和max;最后输出从max-′1′~1的显示数字,即(4)空和(5)空分别填和max-1和′1′。 -
第7题:
●试题一
阅读下列说明和流程图,将应填入(n)处的语句写在答题纸的对应栏内。
【说明】
下列流程图用于从数组K中找出一切满足:K(I)+K(J)=M的元素对(K(I),K(J))(1≤I≤J≤N)。假定数组K中的N个不同的整数已按从小到大的顺序排列,M是给定的常数。
【流程图】
此流程图1中,比较"K(I)+K(J)∶M"最少执行次数约为 (5) 。

图1
正确答案:
●试题一【答案】(1)(2)<(3)I+l->I(4)J-1->J(5)「N/2」【解析】该算法的思路是:设置了两个变量I和J,初始时分别指向数组K的第一个元素和最后一个元素。如果这两个元素之和等于M时,输出结果,并这两个指针都向中间移动;如果小于M,则将指针I向中间移动(因为数组K已按从小到大的顺序排列);如果大于M,则将指针J向中间移动(因为数组K已按从小到大的顺序排列)。当IJ时,说明所有的元素都搜索完毕,退出循环。根据上面的分析,(1)、(2)空要求填写循环结束条件,显然,(1)空处应填写"",(2)空处应填写"<"。这里主要要注意I=J的情况,当I=J时,说明指两个指针指向同一元素,应当退出循环。(3)空在流程图有两处,一处是当K(I)+K(J)=M时,另一处是当K(I)+K(J)<M时,根据上面分析这两种情况都要将指针I向中间移动,即"I+1->I"。同样的道理,(4)空处应填写"J-1->J"。比较"K(I)+K(J):M"最少执行次数发生在第1元素与第N个元素之和等于M、第2元素与第N-1个元素之和等于M、……,这样每次比较,两种指针都向中间移动,因此最小执行次数约为"N-2"。 -
第8题:
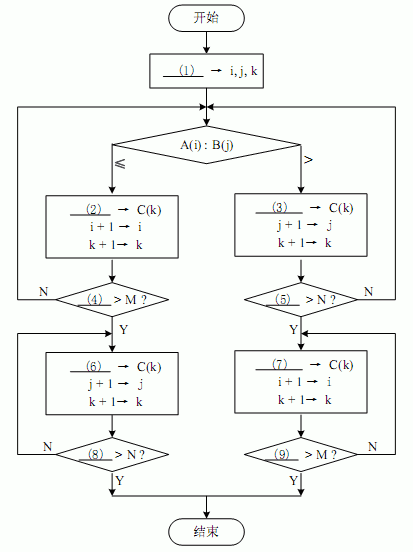
试题一(共 15 分)
阅读以下说明和流程图,填补流程图中的空缺(1)~(9) ,将解答填入答题纸的对应栏内。
[说明]
假设数组 A 中的各元素 A(1),A(2) ,…,A(M)已经按从小到大排序(M≥1) ;数组 B 中的各元素 B(1),B(2),…,B(N)也已经按从小到大排序(N≥1) 。执行下面的流程图后, 可以将数组 A 与数组 B 中所有的元素全都存入数组 C 中, 且按从小到大排序 (注意:序列中相同的数全部保留并不计排列顺序) 。例如,设数组 A 中有元素:2,5,6,7,9;数组B 中有元素:2,3,4,7;则数组 C 中将有元素:2,2,3,4,5,6,7,7,9。
[流程图]
 正确答案:
正确答案:
-
第9题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾依次分离出各个关键词{A(i)|i=1,…,n}(n>1)},其中包含了很多重复项,经下面的流程处理后,从中挑选出所有不同的关键词共m个{K(j)|j=1,…,m},而每个关键词K(j)出现的次数为NK(j),j=1,…,m。
[流程图]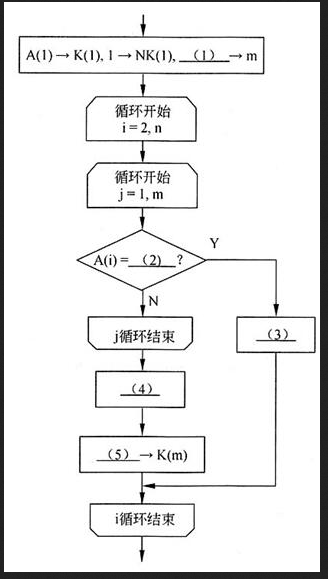 答案:解析:1
答案:解析:1
K(j)
NK(j)+1→NK(i) 或NK(j)++ 或等价表示
m+1→m或m++ 或等价表示
A(i)
【解析】
流程图中的第1框显然是初始化。A(1)→K(1)意味着将本书的第1个关键词作为选出的第1个关键词。1→NK(1)意味着此时该关键词的个数置为1。m是动态选出的关键词数目,此时应该为1,因此(1)处应填1。
本题的算法是对每个关键词与已选出的关键词进行逐个比较。凡是遇到相同的,相应的计数就增加1;如果始终没有遇到相同关键词的,则作为新选出的关键词。
流程图第2框开始对i=2,n循环,就是对书中其他关键词逐个进行处理。流程图第3框开始j=1,m循环,就是按己选出的关键词依次进行处理。
接着就是将关键词A(i)与选出的关键词K(j)进行比较。因此(2)处应填K(j)。
如果A(i)=K(i),则需要对计数器NK(j)增1,即执行NK(j)+1→NK(j)。因此(3)处应填NK(j)+1→NK(j)。执行后,需要跳出j循环,继续进行i循环,即根据书中的下一个关键词进行处理。
如果A(i)不等于NK(j),则需要继续与下个NK(j)进行比较,即继续执行j循环。如果直到j循环结束仍没有找到匹配的关键词,则要将该A(i)作为新的已选出的关键词。因此,应执行A(i)→K(m+1)以及m+1→m。更优的做法是先将计数器m增1,再执行A(i)→K(m)。因此(4)处应填m+1→m,(5)处应填A(i)。 -
第10题:
第一题 阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
【说明】
对于大于1的正整数n,(x+1)n可展开为
问题:1.1 【流程图】
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1。
格式为:循环控制变量=初值,终值,递增值。答案:解析:(1)2,n,1
(2)A[k]
(3)k-1,1,-1
(4)A[i]+A[i-1]
(5)A[i]
【解析】
(1)(3)空为填写循环初值终值和递增值,题目中给出的格式为循环控制变量=初值,终值,递增值。按照题意,实质为求杨辉三角。如下图: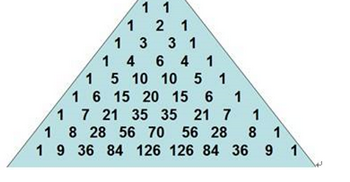

-
第11题:
阅读以下说明和流程图,填写流程图中的空缺,将解答填入答题纸的对应栏内。【说明】设[a1b1],[a2b2],...[anbn]是数轴上从左到右排列的n个互不重叠的区间(a1 答案:解析:1.A2.ai3.bi4.A 、B5.B
答案:解析:1.A2.ai3.bi4.A 、B5.B
【解析】
若A≤ai则输出A,反之输出ai。若A≤bi不满足则输出bi,依次类推。 -
第12题:
问答题阅读以下说明和流程图,将应填入____处的字句写在答题纸的对应栏内。下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在"aaaa"中只出现两次"aa"。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图8-17中,i为字符串A中当前正在进行比较的动态子串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。正确答案: 0→k(2)i+j(3)i+m(4)1+1(5)i解析: 在文章中查找某关键词出现的次数是经常碰到的问题。流程图最终输出的计算结果k就是文章字符串A中出现关键字符串B的次数。显然,流程图开始时应将k赋值0,以后每找到一处出现该关键词,就执行增1操作k=k+1。因此(1)处应填0→k。字符串A和字符串B的下标都是从0开始的。所以在流程图执行的开始处,需要给它们赋值0,接下来执行的第一个小循环就是判断A(i),A(i+1),…,A(i+j-1)是否完全等于B(0),B(1),…,B(m-1),其循环变量j=0,1,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。 因此,该循环中继续执行的判断条件应该是A(i+j)=B(j)且j -
第13题:
阅读以下说明和流程图,填补流程图中的空缺(1)一(5),将解答填入答题纸的对应栏内。
【说明】
下面的流程图采用公式ex=1+x+x2/2 1+x3/3 1+x4/4 1+…+xn/n!+???计算ex的近似值。设x位于区间(0,1),该流程图的算法要点是逐步累积计算每项xx/n!的值(作为T),再逐步累加T值得到所需的结果s。当T值小于10-5时,结束计算。
【流程图】
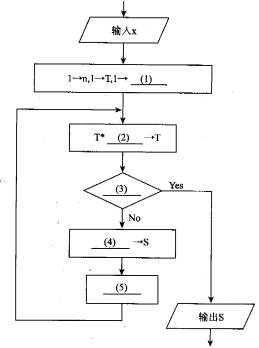 正确答案:(1)S (2)x/n (3)T<O.00001 (4)S+T (5)n+1->n
正确答案:(1)S (2)x/n (3)T<O.00001 (4)S+T (5)n+1->n
(1)S (2)x/n (3)T<O.00001 (4)S+T (5)n+1->n 解析:在题目中已经给出了指数函数ex的公式,即基本算法,另外也给出了计算过程中控制误差终止计算的方法。本题主要的重点是如何设计计算流程,实现级数前若干项的求和,以及判断计算终止的条件。级数求和一般都是采用逐项累加的方法。从流程图我们可以看出s为累加结果,T为动态的项值,最后通过s+T->S来完成各项的累加。已知T=xnx/n!,如果每次都直接计算T的值,计算量会比较大。从ex的公式中我们可以看出每一项都一个共同点,就是后一项和前一项有简单的关系Tn=T(n-i)*x/n,我们可以充分利用前项的计算结果来计算后一项,这样就会大大减少计算量。这也是程序员需要掌握的基本技巧。在流程图中,一开始先输入变量x,接着对其他变量赋初值。级数项号n的初始值为1,逐次进行累积的T的初始值为1,根据后面的流程推断可以看出逐次进行累加的s应该有初始值l的(在输入的x满足条件直接退出循环的时候根据公式输出的值为D,所以空(1)的答案为“S”。从前面分析直到e。的公式中后一项和前一项有简单的关系Tn=T(n-i)*x/n,所以空(2)的答案为“x/n”。空(3)处是判断计算过程结束的条件,按照题目中的要求“当T值小于lO-5时,结束计算。”所以空(3)的答案为“T<0.00001”。按照题意空(4)处是要对每项的结果进行累加赋给S,实现s+T->s,所以空(4)的答案为“S+T”。流程走到空(5)的时候已经求出第n项的值Tn,并累加到s中,根据算法下一步应该计算第n+1项的值,所以这里需要对级数的项号n进行自增,空(5)的答案可以为“n+=1”或者n++,但是根据流程图以上的书写风格写为“n+1->n”应该是最佳答案。 -
第14题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
有数组A(4,4),把1到16个整数分别按顺序放入A(1,1),…,A(1,4),A(2,1),…,A(2,4),A(3,1),…,A(3,4),A(4,1),…,A(4,4)中,下面的流程图用来获取数据并求出两条对角线元素之积。
【流程图】
 正确答案:(1)141 (2)141 (3)1 (4)s×A[ii] (5)s×A[5-ii]
正确答案:(1)141 (2)141 (3)1 (4)s×A[ii] (5)s×A[5-ii]
(1)1,4,1 (2)1,4,1 (3)1 (4)s×A[i,i] (5)s×A[5-i,i] 解析:本题考查用程序流程图描述数组及求对角线的和。
题目要求把1到16个整数分别按顺序放入A(1,1),…,A(1,4),A(2,1),…,A(2,4), A(3,1),…,A(3,4),A(4,1),…,A(4,4)中,那么数组中的元素刚好构成一个方阵,用流程图求出这个方阵的对角线之积。下面来具体分析流程图。
第(1)空与第(2)空应该结合起来完成,它们都是一个循环判断语句的条件,从图中可以看出,如果这两个条件都成立,则读出当前数组中的元素值,根据题目要求,数组中的元素个数是每行4个每列4个,那么循环的上界应该是4,而下标是从1开始的,因此这两个空答案为1,4,1。
第(3)空是一个赋值语句,给变量s赋一个初值,从图中后面的语句不难看出s中存放的是求积的结果,那么在求积以前,s的值应该为1,因此此空答案为1。
第(4)空也是一个赋值语句,是在循环条件判断语句下,我们已经知道变量s中存放的是每次求积的结果,那么此空很明显是用来求积的,用当前取到的对角线元素乘以变量s中存放的值,因此此空答案为s×A[i,i]。
第(5)空和上一空非常相似,但它是用来求另外一条对角线的积的,它也是在一个循环下来实现的,这条对角线的元素位置与上面那条具有对称的特点,因此此空答案为s×A[5-i,i]。 -
第15题:
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
[说明]
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中,n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i为字符串A中当前正在进行比较的动态予串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
[流程图]
 正确答案:0-k i+j i+m i+1 i
正确答案:0-k i+j i+m i+1 i
0-k i+j i+m i+1 i 解析:本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果K就是文章字符串A中出现关键词字符串B的次数。显然,流程图开始时应将K赋值0,以后每找到一处出现该关键词,就执行增1操作K=K+1。
因此(1)处应填0→K。
字符串A和B的下标都是从0开始的。所以在流程图执行的开始处,需要给它们赋值0。接下来执行的第一个小循环就是判断A(i),A(i+1),…,A(i+j-1)是否完全等于B(0),B(1),…,B(m-1),其循环变量j=0,1,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是A(i+j)=B(j)且jm。只要遇到A(i+j)≠B(j)或者j=m(关键词各字符都己判断过)就不再继续执行该循环了。因此流程图的(2)处应填州i+j。
许多考生在(2)处填i,当j增1变化后,仍然使用A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在j=0,1,…,m-1时全都成立A(i+j)=B(j)(找到了一处关键词),直到j=m时才结束小循环;二是在jm时就发现了字符不等的情况,这说明此处并不出现关键词。因此流程图中用jm来区分找到与没有找到关键词的两种情况。
对于j=m,已找到一处关键词的情况,显然应该执行k=k+1,对关键词出现次数的变量k进行增1计算。同时,为了继续进行以后的判断,应将字符串A的下标i右移m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就使关键词的出现有可能发生部分重叠的现象。
流程图中,对于jm的情况,表示刚才判断关键词时并非各个字符都完全相同,也就是说,刚才的判断结论是此处并没有出现关键词。即A(i)开始的子串并不是关键词。因此,下次判断关键词应该以A(i+1)开始,即(4)处应填i+1。
在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对A(n-m),A(n-m+1),…,A(n-1)的判断。下标n-m来自从n-1倒数m个数。可以先试验写出A(n-m),A(n-m+1),…,A(n-1),再判断其个数是否为m。经检查,个数为(n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。
既然最后一次判断关键词应该是对A(n-m),A(n-m+1),…,A(n-1)的判断,即对i=n-m进行的小循环判断,所以当i>n-m时就应该停止大循环,停止再查找关键词了。
-
第16题:
阅读以下说明和流程图,回答问题,并将解答填入对应栏内。
【说明】
求解约瑟夫环问题。算法分析:n个士兵围成一圈,给他们依次编号,班长指定从第w个士兵开始报数,报到第s个士兵出列,依次重复下去,直至所有士兵都出列。
【流程图】

【问题】
将流程图中的(1)~(5)处补充完整。
正确答案:(1)L[i].nextp=1 (2) k=w-1 (3) count!=n (4) ++I (5) ++count
(1)L[i].nextp=1 (2) k=w-1 (3) count!=n (4) ++I (5) ++count -
第17题:
?????? 阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的
对应栏内。
【说明】
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾
依次分离出各个关键词{A(i)li=l,…,n}(n>1)}.其中包含了很多重复项,经下面的流程
处理后,从中挑选出所有不同的关键词共m个{K(j)[j=l,…,m},而每个关键词K(j)出现的次数为NK(j).j=l,…,m。

??????
正确答案:
??流程图中的第1框显然是初始化。A(1)→K(1)意味着将本书的第1个关键词作为选出的第1个关键词。1→NK(1)意味着此时该关键词的个数置为1。m是动态选出的关键词数目,此时应该为1,因此(1)处应填1。?本题的算法是对每个关键词与已选出的关键词进行逐个比较。凡是遇到相同的,相??应的计数就增加1;如果始终没有遇到相同关键词的,则作为新选出的关键词。流程图第2框开始对i=2,n循环,就是对书中其他关键词逐个进行处理。流程图第3框开始j=l,m循环,就是按已进出的关键词依次进行处理。接着就是将关键词A(i)与选出的关键词K(j)进行比较。因此(2)处应填K(j)。如果A(i)=K(j),则需要对计数器NK(j)增1.即执行NK(j)+1→NK(j)。因此(3)处应填NK(j)+I→NK(j)。执行后,需要跳出j循环,继续进行i循环,即根据书中的下一个关键词进行处理。如果A(i)不等于NK(j),则需要继续与下个NK(j)进行比较,即继续执行j循环。如果直到j循环结束仍没有找到匹配的关键词,则要将该A(i)作为新的已选出的关键词。因此,应执行A(i)→K(m+1)以及m+l→m。更优的做法是先将计数器m增1,再执行A(j)→K(m)。因此(4)处应填m+l→m,(5)处应填A(i)。试题一参考答案(1)1(2)K(j)(3)Nk(j)+I→NK(j)或NK(j)十十或等价表示(4)m+l→m或m++或等价表示(5)A(i)?? -
第18题:
●试题一
阅读下列说明和流程图,将应填入(n)的字句写在答题纸的对应栏内。
【说明】
下列流程图(如图4所示)用泰勒(Taylor)展开式
sinx=x-x3/3!+x5/5!-x7/7!+…+(-1)n×x 2n+1/(2n+1)!+…
【流程图】
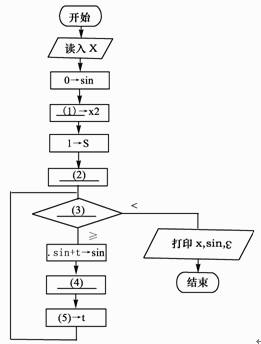
图4
计算并打印sinx的近似值。其中用ε(>0)表示误差要求。
正确答案:
●试题一【答案】(1)x*x(2)x->t(3)|t|∶ε(4)s+2->s(5)(-1)*t*x2/(s*(s-1))【解析】该题的关键是搞清楚几个变量的含义。很显然变量t是用来保存多项式各项的值,变量s和变量x2的作用是什么呢?从流程图的功能上看,需要计算1!、3!、5!,……,又从变量s的初值置为1可知,变量s主要用来计算这此数的阶乘的,但没有其他变量用于整数自增,这样就以判断s用来存储奇数的,即s值依次为1、3、5,……。但x2的功能还不明确,现在可以不用管它。(2)空的作用是给t赋初值,即给它多项式的第一项,因此应填写"x->t"。(3)空处需填写循环条件,显然当t的绝对值小于ε(>0)就表示已经达到误差要求,因此(3)空应填入"|t|∶ε"。由变量s的功能可知,(4)空应当实现变量s的增加,因此(4)空应填入"s+2->s"。(5)空应当是求多项式下一项的值,根据多项式连续两项的关系可知,当前一项为t时,后一项的值为(-1)*t*x*x/(s*(s-1))。但这样的话,每次循环都需要计算一次x*x,计算效率受到影响,联想到变量x2还没用,这时就可以判断x2就是用来存储x*x的值,使得每次循环者少进行一次乘法运算。因此(1)空处应填入"x*x",(5)空处应填入"(-1)*t*x2/(s*(s-1))"。 -
第19题:
试题三(共 15 分)
阅读以下说明和 C 程序,将应填入 (n) 处的字句写在答题纸的对应栏内。
 正确答案:
正确答案:
-
第20题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
下面流程图的功能是:在给定的两个字符串中查找最长的公共子串,输出该公共子串的长度L及其在各字符串中的起始位置(L=0时不存在公共字串)。例如,字符串"The light is not bright tonight"与"Tonight the light is not bright"的最长公共子串为"he light is not bright",长度为22,起始位置分别为2和10。
设A[1:M]表示由M个字符A[1],A[2],…,A[M]依次组成的字符串;B[1:N]表示由N个字符B[1],B[2],…,B[N]依次组成的字符串,M≥N≥1。
本流程图采用的算法是:从最大可能的公共子串长度值开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串,即在A、B字符串中分别顺序取出长度为L的子串后,调用过程判断两个长度为L的指定字符串是否完全相同(该过程的流程略)。
[流程图]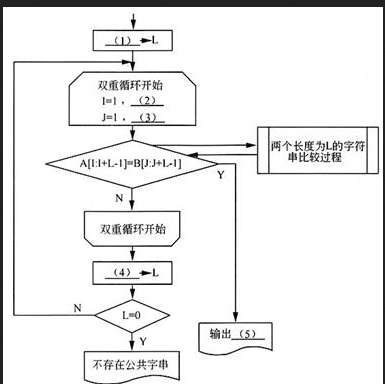 答案:解析:N或rnin(M,N)
答案:解析:N或rnin(M,N)
M-L+1
N-L+1
L-1
L,I,J
【解析】
本题考查对算法流程图的理解和绘制能力。这是程序员必须具有的技能。
本题的算法可用来检查某论文是否有大段抄袭了另一论文。"The light is not bright tonight"是著名的英语绕口令,它与"Tonight the light is not bright"大同小异。
由于字符串A和B的长度分别为M和N,而且M≥N≥1,所以它们的公共子串长度L必然小于或等于N。题中采用的算法是,从最大可能的公共子串长度值L开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串。因此,初始时,应将min(M,N)送L,或直接将N送L。(1)处应填写N或min(M,N),或其他等价形式。
对每个可能的L值,为查看A、B串中是否存在长度为L的公共子串,显然需要执行双重循环。A串中,长度为L的子串起始下标可以从l开始直到M-L+1(可以用实例来检查其正确性);B串中,长度为L的子串起始下标可以从1开始直到N-L+1。因此双重循环的始值和终值就可以这样确定,即(2)处应填M-L+1,或等价形式;(3)处应填N-L+1或等价形式(注意循环的终值应是最右端子串的下标起始值)。
A串中从下标I开始长度为L的子串可以描述为A[I:I+L-1];B串中从下标J开始长度为L的子串可以描述为A[J:J+L-1]。因此,双重循环体内,需要比较这两个子串(题中采用调用专门的函数过程或子程序来实现)。
如果这两个子串比较的结果相同,那么就已经发现了A、B串中最大长度为L的公共子串,此时,应该输出公共子串的长度值L、在A串中的起始下标I、在B串中的起始下标J。因此,(5)处应填L,I,J(可不计顺序)。
如果这两个子串比较的结果不匹配,那么就需要继续执行循环。如果直到循环结束仍然没有发现匹配子串时,就需要将L减少1((4)处填L-1或其等价形式)。只要L非0,则还可以继续对新的L值执行双重循环。如果直到L=0,仍没有发现子串匹配,则表示A、B两串没有公共子串。 -
第21题:
阅读下列说明和图,回答问题,将解答填入答题纸的对应栏内。
阅读以下说明和C函数,将应填入 (n) 处的语句或语句成分写在答题纸的对应栏内。
【说明1】
函数deldigit(char *s) 的功能是将字符串s中的数字字符去掉,使剩余字符按原次序构成一个新串,并保存在原串空间中。其思路是:先申请一个与s等长的临时字符串空间并令t指向它,将非数字字符按次序暂存入该空间,最后再拷贝给s。
【C函数】
char *t = (char *)malloc( (1) ); /*申请串空间*/ int i, k = 0; if (!t) return; for(i = 0; i < strlen(s); i++)if ( !(*(s+i)>=’0’ && *(s+i)<=’9’) ) { t[k++] = (2) ;} (3) = ’\0’; /*设置串结束标志*/ strcpy(s,t);free(t);}
【说明2】
函数reverse(char *s, int len)的功能是用递归方式逆置长度为len的字符串s。例如,若串s的内容为"abcd",则逆置后其内容变为"dcba"。
【C函数】
void reverse(char *s, int len){ char ch; if ( (4) ) { ch = *s; *s = *(s+len-1); *(s+len-1) = ch; reverse( (5) ); }}答案:解析:(1)strlen(s)+1
(2)*(s+i),或s[i]或其等价表示
(3)*(t+k)或t[k] 或其等价表示
(4)len>1 或len>=1 或其等价表示
(5)s+1 len-2
【解析】
根据说明1,在函数deldigit(char*s)中需先申请一个与s等长的临时字符串空间并令t指向它,因此空(1)处应填入"strlen(s)+1",其中,加1的原因是函数strlen计算s所指向字符串的长度时,没有包含串结束标志字符"\0"。当然,申请比"strlen(s)+1"更大的存储区也可以,只是没有必要。
由于需要将非数字字符按原来的顺序存入t所指向的存储区,所以空(2)处填入"s[i]",或其等价表示形式。
最后在设置t所指向字符串的结束标志,即令t[k]='\0'.在这里,空(3)处的t[k]写为t[k++]也可以,而写为t[k+1]或t[++k]则不符合整个代码的处理逻辑。
函数reverse(char*s,int len)的功能是用递归方式逆置长度为len的字符串s,其中以下代码实现了将s所指字符与串中最后一个字符交换的处理。
Ch=*s; *s=*(s+len-1); *(s+len-1)=ch; -
第22题:
阅读以下说明和流程图,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在"aaaa"中只出现两次"aa"。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
【流程图】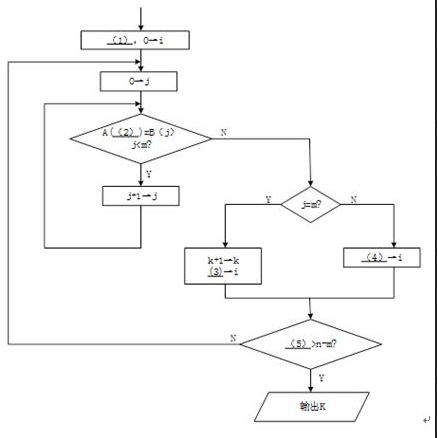 答案:解析:
答案:解析: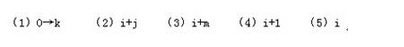
【解析】
本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果 k就是文章字符串 A中出现关键词字符串 B的次数。显然,流程图开始时应将 k赋值 0,以后每找到一处出现该关键词,就执行增1操作 k=k+1。因此(1)处应填0→k。
字符串 A和 B的下标都是从 0开始的。所以在流程图执行的开始处,需要给它们赋值 0。接下来执行的第一个小循环就是判断 A(i),A(i+1),…,A(i+j一1)是否完全等于 B(0),B(1),…,B(m一1),其循环变量j=0,l ,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是 A(i+j)=B(j)且j许多考生在(2)处填 i,当j 增 1 变化后,仍然使用 A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在 j=0,1 ,…,m-1 时全都成立 A(i+j)=B(j)(找到了一处关键词),直到j=m 时才结束小循环;二是在 j对于 j=m,己找到一处关键词的情况,显然应该执行 k=k+1,对关键词出现次数的变量 k进行增 1计算。同时,为了继续进行以后的判断,应将字符串 A 的下标 i右移 m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写 i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的 j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就 使关键词的出现有可能发生部分重叠的现象。
流程图中,对于 j在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对 A(n-m),A(n-m+1),… ,A(n一1)的判断。下标 n-m来自从 n-1 倒数 m个数。可以先试验写出A(n-m),A(n-m+1),… ,A(n一1),再判断其个数是否为m。经检查,个数为 (n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。 既然最后一次判断关键词应该是对A(n-m),A(n-m+1),… ,A(n一1)的判断,即对 i=n-m进行的小循环判断,所以当 i>n-m 时就应该停止大循环,停止再查找关键词了。 -
第23题:
阅读下列说明和?C++代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
阅读下列说明和?Java代码,将应填入?(n)?处的字句写在答题纸的对应栏内。
【说明】
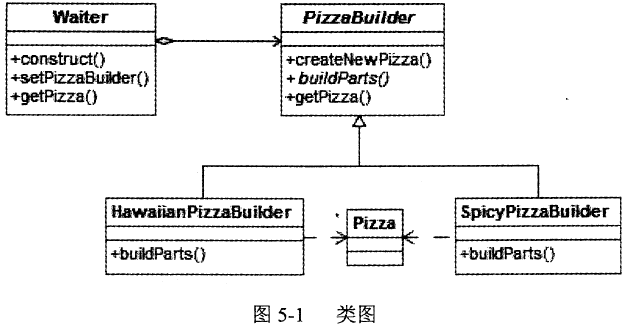
某快餐厅主要制作并出售儿童套餐,一般包括主餐(各类比萨)、饮料和玩具,其餐品种
类可能不同,但其制作过程相同。前台服务员?(Waiter)?调度厨师制作套餐。现采用生成器?(Builder)?模式实现制作过程,得到如图?6-1?所示的类图。


 答案:解析:
答案:解析: