
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】 设有整数数组A[1:N](N>1),其元素有正有负。下面的流程图在该数组中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标K、元素个数L以及最大的和值M。 例如,若数组元素依次为3,-6,2,4,-2,3,-1,则输出K=3,L=4,M=7。该流程图中考察了A[1:N]中所有从下标i到下标j(j≥i)的各元素之和S,并动态地记录其最大值M。【流程图】注:循环开始框内应给出循环控制变量的初值和终值,默认递增值
题目
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】 设有整数数组A[1:N](N>1),其元素有正有负。下面的流程图在该数组中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标K、元素个数L以及最大的和值M。 例如,若数组元素依次为3,-6,2,4,-2,3,-1,则输出K=3,L=4,M=7。该流程图中考察了A[1:N]中所有从下标i到下标j(j≥i)的各元素之和S,并动态地记录其最大值M。
【流程图】 注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为:循环控制变量=初值,终值
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为:循环控制变量=初值,终值
相似考题
更多“阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】 设有整数数组A[1:N](N1),其元素有正有负。下面的流程图在该数组中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标K、元素个数L以及最大的和值M。 例如,若数组元素依次为3,-6,2,4,-2,3,-1,则输出K=3,L=4,M=7。该流程图中考察了A[1:N]中所有从下标i到下标j(ji)的各元素之和S,并动态地记录其最大值M。【流程图】注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式”相关问题
-
第1题:
阅读下列说明、流程图和算法,将应填入(n)处的字句写在对应栏内。
【流程图说明】
下图所示的流程图5.3用N-S盒图形式描述了数组Array中的元素被划分的过程。其划分方法;以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于Array[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。

【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int Array[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组Ar ray中的下标。递归函数void sort(int Array[],int L,int H)的功能是实现数组Array中元素的递增排序。
【算法】
void sort(int Array[],int L,int H){
if (L<H) {
k=p(Array,L,H);/*p()返回基准数在数组Array中的下标*/
sort((4));/*小于基准数的元素排序*/
sort((5));/*大于基准数的元素排序*/
}
}
正确答案:(1)j←j-1
(1)j←j-1 -
第2题:
阅读以下说明和流程图,回答问题1-2,将解答填入对应的解答栏内。
[说明]
下面的流程图采用欧几里得算法,实现了计算两正整数最大公约数的功能。给定正整数m和 n,假定m大于等于n,算法的主要步骤为:
(1)以n除m并令r为所得的余数;
(2)若r等于0,算法结束;n即为所求;
(3)将n和r分别赋给m和n,返回步骤(1)。
[流程图]
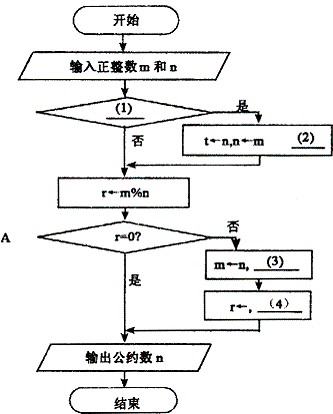
[问题1] 将流程图中的(1)~(4)处补充完整。
[问题2] 若输入的m和n分别为27和21,则A中循环体被执行的次数是(5)。
正确答案:[问题1] (1) n>m或nm或其它等效形式 (2) m←t (3) n←r (4) m%n [问题2] (5) 1
[问题1] (1) n>m或nm或其它等效形式 (2) m←t (3) n←r (4) m%n [问题2] (5) 1 解析:(1)~(2)当n的值大于(等于)m时,应交换两者的值,再使用欧几里得算法;
(3)~(4)略;
(5)m,n和r在执行循环A前后的值分别为: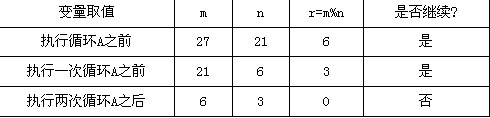
-
第3题:
试题一(共15分)
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的
对应栏内。
【说明】
两个包含有限个元素的非空集合A、B的相似度定义为IAUBI/IA U Bl,即它们的交
集大小(元素个数)与并集大小之比。
以下的流程图计算两个非空整数集合(以数组表示)的交集和并集,并计算其相似
度。己知整数组A[1:m】和B【1:n】分别存储了集合A和B的元素(每个集合中包含的元素
各不相同),其交集存放于数组C[1:s】,并集存放于数组D【1:t】,集合A和B的相似度存
放于SIM。
例如,假设A={1,2,3,4},B={1,4,5,6},则C={1,4},D={1,2,3,4,5,
6},A与B的相似度SIM=1/3。
 正确答案:
正确答案:
本题考查程序处理流程图的设计能力。
首先我们来理解两个有限集合的相似度的含义。两个包含有限个元素的非空集合A、
B的相似度定义为它们的交集大小(元素个数)与并集大小之比。如果两集合完全相等,
则相似度必然为1(100%);如果两集合完全不同(没有公共元素),则相似度必然为0;
如果集合A中有一半元素就是集合B的全部元素,而另一半元素不属于集合B,则这两
个集合的相似度为0.5(50%)。因此,这个定义符合人们的常理性认识。
在大数据应用中,经常要将很多有限集进行分类。例如,每天都有大量的新闻稿。
为了方便用户检索,需要将新闻稿分类。用什么标准来分类呢?每一篇新闻稿可以用其
中所有的关键词来表征。这些关键词的集合称为这篇新闻稿的特征向量。两篇新闻稿是
否属于同一类,依赖于它们的关键词集合是否具有较高的相似度(公共关键词个数除以
总关键词个数)。搜索引擎可以将相似度超过一定水平的新闻稿作为同一类。从而,可以
将每天的新闻稿进行分类,就可以按用户的需要将某些类的新闻稿推送给相关的用户。
本题中的集合用整数组表示,因此,需要规定同一数组中的元素各不相同(集合中
的元素是各不相同的)。题中,整数组A[1:m],和B[l:n]分别存储了集合A和B的元素。
流程图的目标是将A、B中相同的元素存放入数组C[1:s](共s个元素),并将A、B中
的所有元素(相同元素只取一次)存放入数组D[1:t(共t个元素),最后再计算集合A
和B相似度s/t。
流程图中的第一步显然是将数组A中的全部元素放入数组D中。随后,只需要对数
组B中的每个元素进行判断,凡与数组A中某个元素相同时,就将其存入数组C;否则
就续存入数组D(注意,数组D中已有m个元素)。这需要对j(遍历数组B)与i(遍
历数组A)进行两重循环。判断框B[j]=A[i]成立时,B[j]应存入数组C;否则应继续i
循环,直到循环结束仍没有相等情况出现时,就应将B[j]存入数组D。存入数组C之前,
需要将其下标s增1;存入数组D之前,需要将其下标t增1。因此,初始时,应当给j
赋0,使数组C的存数从C[1]开始。从而,()处应填s,(3)处应填C[s]。而数组D
是在已有m个元素后续存,所以,初始时,数组D的下标t应当是m,续存是从D【m+1】
开始的。因此,(2)处应填t,(4)处应填D[t]。
两重循环结束后,就要计算相似度s/t,将其赋予SIM,因此(5)处应填s/t。
参考答案
(l)s(2)t(3)C[s](4)D[t](5)s/t
-
第4题:
●试题二
阅读下列说明、流程图和算法,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
下面的流程图(如图3所示)用N-S盒图形式描述了数组A中的元素被划分的过程。其划分方法是:以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于A[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。例如,对数组(4,2,8,3,6),以4为基准数的划分过程如下:
【流程图】
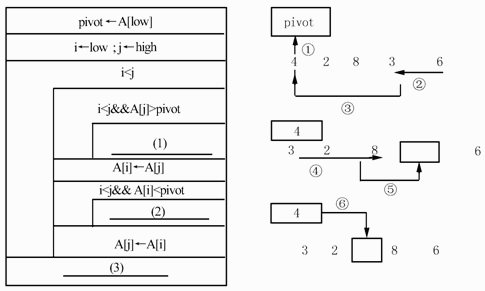
图3流程图
【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int A[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组A中的下标。递归函数void sort(int A[],int L,int H)的功能是实现数组A中元素的递增排序。
【算法】
void sort (int A[], int 1,int H){
if ( L<H){
k=p(A,L,R);//p()返回基准数在数组A中的下标
sort( (4) );//小于基准数的元素排序
sort( (5) );//大于基准数的元素排序
}
}
正确答案:
●试题二【答案】(1)j--(2)i++(3)A[i]←pivot或[j]←pivot(4)A,L,k-1或A,L,k(5)A,k+I,H或A,k,H【解析】题目考查快速排序算法。快速排序采用了一种分治的策略,通常称为分治法。其基本思想是:将原问题分解为若干个规模更小,但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。快速排序的具体过程为:第一步,在待排序的n个记录中任取一个记录,以该记录的排序码为基准,将所有记录分成2组,第一组各记录的排序码都小于等于该排序码,第二组各记录的排序码都大于该排序码,并把该记录排在这2组中间,这个过程称为一次划分。第二步,采用同样的方法,对划分出来的2组元素分别进行快速排序,直到所有记录都排到相应的位置为止。在进行一次划分时,若选定以第一个元素为基准,就可将第一个元素备份在变量pivot中,如图中的第①步所示。这样基准元素在数组中占据的位置就空闲出来了,因此下一步就从后向前扫描。如图中的第②步所示,找到一个比基准元素小的元素时为止,将其前移,如图中的第③步所示。然后再从前向后扫描,如图中的第④步所示,找到一个比基准元素大的元素时为止,将其后移,如图中的第⑤步所示。这样,从后向前扫描和从前向后扫描交替进行,直到扫描到同一个位置为止,如图中的第⑥步所示。由题目中给出的流程图可知,以第一个元素作为基准数,并将A[low]备份至pivot,i用于从前向后扫描的位置指示器,其初值为low,j用于从后往前扫描的位置指示器,其初值为high。当i<j时进行循环:1)从后向前扫描数组A,在i<j的情况下,如果被扫描的元素A[j]>pivot,就继续向前扫描(j--);如果被扫描的元素A[i]<pivot就停止扫描,并将此元素的值赋给目前空闲着的A[i]。2)这时,再从前向后扫描,在i<j的情况下,如果被扫描的元素A[j]<pivot,就继续向后扫描(i++);如果被扫描的元素A[j]>pivot就停止扫描,并将此元素的值赋给目前空闲着的A[j]。3)这时又接第(1)步,直到i>j时退出循环。退出循环时,将pivot赋给当前的A[i](A[i]←pivot)。递归函数的目的是执行一系列调用,直到到达某一点时递归终止。为了保证递归函数正常执行,应该遵守下面的规则:1)每当一个递归函数被调用时,程序首先应该检查基本的条件是否满足,例如,某个参数的值等于0,如果是这种情形,函数应停止递归。2)每次当函数被递归调用时,传递给函数一个或多个参数,应该以某种方式变得"更简单",即这些参数应该逐渐靠近上述基本条件。例如,一个正整数在每次递归调用时会逐渐变小,以至最终其值到达0。本题中,递归函数sort(intA[],intL,intH)有3个参数,分别表示数组A及其下界和上界。根据流程图可知,这里的L相当于流程图中的i,这里的H相当于流程图中的j。因为P()返回基准数所在数组A中的下标,也就是流程图中最后的"A[i]←pivot"中的i。根据快速排序算法,在第一趟排序后找出了基准数所在数组A中的下标,然后以该基准数为界(基准数在数组中的下标为k),把数组A分成2组,分别是A[L,…,k-1]和A[k+l,…,H],最后对这2组中的元素再使用同样的方法进行快速排序。 -
第5题:
试题三(共15分)
阅读以下说明和C函数,回答问题 l和问题 2,将解答填入答题纸的对应栏内。
【说明】
对于具有n个元素的整型数组a,需要进行的处理是删除a中所有的值为 0的数组元素,并将a中所有的非 O元素按照原顺序连续地存储在数组空间的前端。下面分别用函数CompactArr_v1 和CompactArr v2来实现上述处理要求,函数的返回值为非零元素的个数。 函数CompactArr_vl(int a[],int n)的处理思路是:先申请一个与数组a的大小相同的动态数组空间,然后顺序扫描数组a的每一个元素,将遇到的非O元素依次复制到动态数组空间中,最后再将动态数组中的元素传回数组a中。
函数CompactArr_v2(int a[],int n)的处理思路是:利用下标i(初值为 0)顺序扫描数组a的每一个元素,下标k(初值为0)表示数组 a中连续存储的非0元素的下标。扫描时,每遇到一个数组元素,i就增 1,而遇到非 0元素并将其前移后k才增 1。

【问题1】 (12分)
请根据说明中函数CompactArr_v1的处理思路填补空缺(1)~(3),根据CompactArr_v2的处理
思路填补空缺(4)。
【问题2】(3分)
请说明函数CompactArr vl存在的缺点。
正确答案:
试题三参考答案(共 15分)
【问题 1】 (12分)
(1) sizeof(int) (3分)
若考生解答为一个正整数,则给 2分
(2)temp[k++] 或*(temp+k++)或等价表示 (3分)
(3) ik 或等价表示 (3分)
(4)a[k++] 或*(a+k++)或等价表示 (3分)
【问题 2】(3分)
可能由于动态内存申请操作失败而导致函数功能无法实现,时间和空间效率低。
注:考生仅回答出运行速度慢则给 2分,其他含义相同的描述可给满分或酌情给分。 -
第6题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
两个包含有限个元素的非空集合A、B的相似度定义为|A∩B|/|A∪B|,即它们的交集大小(元素个数)与并集大小之比。
以下的流程图计算两个非空整数集合(以数组表示)的交集和并集,并计算其相似度。已知整数组A[1:m]和B[1:n]分别存储了集合A和B的元素(每个集合中包含的元素各不相同),其交集存放于数组C[1:s],并集存放于数组D[1:t],集合A和B的相似度存放于SIM。
例如,假设A={1,2,3,4},B={1,4,5,6},则C={1,4),D={1,2,3,4,5,6},A与B的相似度SIM=1/3。
[流程图]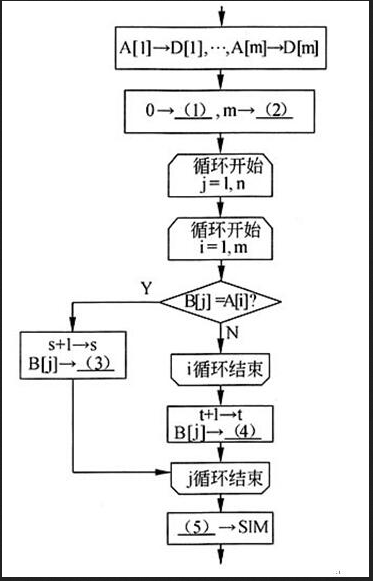 答案:解析:s
答案:解析:s
t
C[s]
D[t]
s/t
【解析】
本题考查程序处理流程图的设计能力。
首先我们来理解两个有限集合的相似度的含义。两个包含有限个元素的非空集合A、B的相似度定义为它们的交集大小(元素个数)与并集大小之比。如果两集合完全相等,则相似度必然为1(100%);如果两集合完全不同(没有公共元素),则相似度必然为0;如果集合A中有一半元素就是集合B的全部元素,而另一半元素不属于集合B,则这两个集合的相似度为0.5(50%)。因此,这个定义符合人们的常理性认识。
在大数据应用中,经常要将很多有限集进行分类。例如,每天都有大量的新闻稿。为了方便用户检索,需要将新闻稿分类。用什么标准来分类呢?每一篇新闻稿可以用其中所有的关键词来表征。这些关键词的集合称为这篇新闻稿的特征向量。两篇新闻稿是否属于同一类,依赖于它们的关键词集合是否具有较高的相似度(公共关键词个数除以总关键词个数)。搜索引擎可以将相似度超过一定水平的新闻稿作为同一类。从而,可以将每天的新闻稿进行分类,就可以按用户的需要将某些类的新闻稿推送给相关的用户。
本题中的集合用整数组表示,因此,需要规定同一数组中的元素各不相同(集合中的元素是各不相同的)。题中,整数组A[1:m]和B[1:n]分别存储了集合A和B的元素。流程图的目标是将A、B中相同的元素存放入数组C[1:s](共s个元素),并将A、B中的所有元素(相同元素只取一次)存放入数组D[1:t](共t个元素),最后再计算集合A和B相似度s/t。
流程图中的第一步显然是将数组A中的全部元素放入数组D中。随后,只需要对数组B中的每个元素进行判断,凡与数组A中某个元素相同时,就将其存入数组C;否则就续存入数组D(注意,数组D中已有m个元素)。这需要对j(遍历数组B)与i(遍历数组A)进行两重循环。判断框B[j]=A[i]成立时,B[j]应存入数组C;否则应继续i循环,直到循环结束仍没有相等情况出现时,就应将B[i]存入数组D。存入数组C之前,需要将其下标s增1;存入数组D之前,需要将其下标t增1。因此,初始时,应当给i赋0,使数组C的存数从C[1]开始。从而,(1)处应填s,(3)处应填C[s]。而数组D是在已有m个元素后续存,所以,初始时,数组D的下标t应当是m,续存是从D[m+1]开始的。因此,(2)处应填t,(4)处应填D[t]。
两重循环结束后,就要计算相似度s/t,将其赋予SIM,因此(5)处应填s/t。 -
第7题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾依次分离出各个关键词{A(i)|i=1,…,n}(n>1)},其中包含了很多重复项,经下面的流程处理后,从中挑选出所有不同的关键词共m个{K(j)|j=1,…,m},而每个关键词K(j)出现的次数为NK(j),j=1,…,m。
[流程图]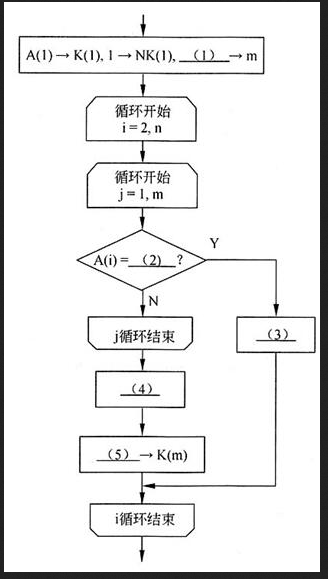 答案:解析:1
答案:解析:1
K(j)
NK(j)+1→NK(i) 或NK(j)++ 或等价表示
m+1→m或m++ 或等价表示
A(i)
【解析】
流程图中的第1框显然是初始化。A(1)→K(1)意味着将本书的第1个关键词作为选出的第1个关键词。1→NK(1)意味着此时该关键词的个数置为1。m是动态选出的关键词数目,此时应该为1,因此(1)处应填1。
本题的算法是对每个关键词与已选出的关键词进行逐个比较。凡是遇到相同的,相应的计数就增加1;如果始终没有遇到相同关键词的,则作为新选出的关键词。
流程图第2框开始对i=2,n循环,就是对书中其他关键词逐个进行处理。流程图第3框开始j=1,m循环,就是按己选出的关键词依次进行处理。
接着就是将关键词A(i)与选出的关键词K(j)进行比较。因此(2)处应填K(j)。
如果A(i)=K(i),则需要对计数器NK(j)增1,即执行NK(j)+1→NK(j)。因此(3)处应填NK(j)+1→NK(j)。执行后,需要跳出j循环,继续进行i循环,即根据书中的下一个关键词进行处理。
如果A(i)不等于NK(j),则需要继续与下个NK(j)进行比较,即继续执行j循环。如果直到j循环结束仍没有找到匹配的关键词,则要将该A(i)作为新的已选出的关键词。因此,应执行A(i)→K(m+1)以及m+1→m。更优的做法是先将计数器m增1,再执行A(i)→K(m)。因此(4)处应填m+1→m,(5)处应填A(i)。 -
第8题:
阅读以下说明和流程图,填补流程图中的空缺(1)~(9),将解答填入对应栏内。1、【说明】 假设数组A中的各元素A(1),A(2),…,A(M)已经按从小到大排序(M≥1);数组B中的各元素B(1),B(2),…,B(N)也已经按从小到大排序(N≥1)。执行下面的流程图后,可以将数组A与数组B中所有的元素全都存入数组C中,且按从小到大排序 (注意:序列中相同的数全部保留并不计排列顺序)。例如,设数组A中有元素:2,5, 6,7,9;数组B中有元素2,3,4,7:则数组C中将有元素:2,2,3,4,5,6,7, 7, 9。【流程图】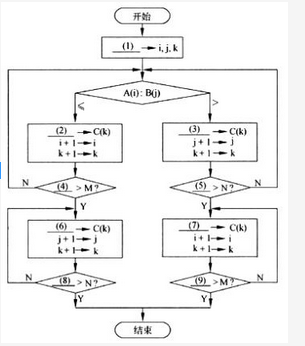 答案:解析:(1)1(2)A(i)(3)B(j)(4)i(5)j(6)B(j)(7)A(i)(8)j(9)i
答案:解析:(1)1(2)A(i)(3)B(j)(4)i(5)j(6)B(j)(7)A(i)(8)j(9)i
【解析】
这是最常见的一种合并排序方法。为对较大的序列进行排序,先将其分割成容量相当的几个部分,分别进行排序,最后再合并在一起。当然,这些排序要么都是升序,要么都是降序。本题全部是按升序排序的。 例如,为了将整副扑克牌按升序进行排序,先将其分割成两个部分(数量大致相当),对每个部分完成升序排序后,就形成了两叠已排序的牌。如何将其合并呢?办法如下。 每次都比较各叠最上面的两张牌,取出比较小的,放入新堆,再继续比较。直到其中一堆空了,就将另一堆剩余的牌逐张放入新堆。新堆就是合并后的已完成排序的序列。 在数据排序时,遇到相同的数比较时,任取一个就可以了。 对本题来说,i、j、k是数组A、B、C的下标,初始时,都应该是1。因此,空(1)处应填写1。 将A(i)与B(j)进行比较后,如果A(i)≤B(j),那么应该将A(i)→C(k)。这是升序的要求。因此,空(2)处应填A(i)。如果A(i)>B(j),则应将B(j)→C (k)。因此,空(3)处应填B(j)。 在A(i)→C(k)后,i应增加1,为下次取A(i)再比较做准备(k也需要增加1,为下次存入C(k)做准备)。这时,需要比较数组A是否已经取完,即判断i>M是否成立。如果i>M,则表示数组A中的元素已经全部取出,需要将数组B中剩余的元素逐个移入C(k)。因此,空(4)处应填i,空(6)处应填B(j)。数组B处的元素何时移完呢?这就需要判断i>N是否成立。因此,空(8)处应填j。 同样,空(3)处将B(j)存入C(k),直到,j>N时数组B中的元素取完。此时,需要将数组A中剩余的元素逐个移入C(k),直到i>M时全部完成。因此,空(5)处应填j,空(7)处应填A(i),空(9)处应填i。 -
第9题:
阅读以下说明和流程图,填写流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】如果n位数(n≧2)是回文数(从左到右读与从右到左读所得结果一致),且前半部分的数字递增(非减)、后半部分的数字将递减(非增),则称该数为拱形回文数。例如,12235753221 就是一个拱形回文数。显然,拱形回文数中不含数字0。下面的流程图用于判断给定的n位数(各位数字依次存放在数组的各个元素A[ i ]中,i =1,2,…,n)是不是拱形回文数。流程图中,变量T 动态地存放当前位之前一位的数字。当n 是奇数时,还需要特别注意中间一位数字的处理。【流程图】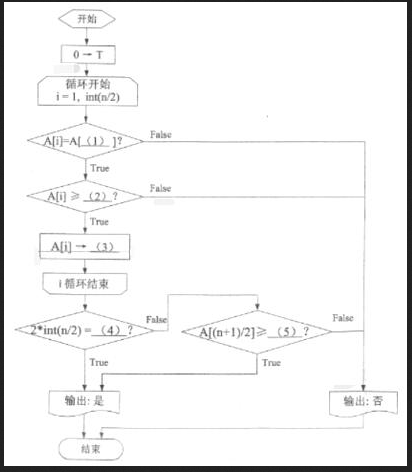
注1:“循环开始”框内给出的循环控制变量的初值、终值和增值(默认为1),格式为:循环款控制变量=初值,终值[ , 增值 ]注2:函数int(x)为取x的整数部分,即不超过x 的最大整数。答案:解析:(1)n-i+1(2)T&&A[i]!=O或 T&&A[i]>0(3)T(4)n(5)T或A[n/2]或A[(n-1)/2]
【解析】
1)跟A[i]对称的后半部分元素下标是n-i+1 ;2)T动态地存放当前位之前一位的数字,所以这甲A[i] 大于前一项T值,且在拱形回文数中,不含数字0,所以再加上一个条件 A[i]!=03)比较完后,将A[i]值赋给T,T 进行动态地存放当前位之前一位的数字。4.5)判断元素个数是偶数还是奇数,如果是奇数,则还需要进行判断最中间的元素,所以4 空这里填空n,5空填的是为奇数个时最中间元素的前一项元素的表示。 -
第10题:
试题(15 分)阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏 内。【说明】设有整数数组 A[1:N](N>1),其元素有正有负。下面的流程图在该数组 中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标 K、元素 个数 L 以及最大的和值 M。例如,若数组元素依次为 3,-6,2,4,-2,3,-1,则输出 K=3,L=4,M=7。 该流程图中考察了 A[1:N]中所有从下标 i 到下标 j(j≥i)的各元素之和 S,并动态地记录其最大值 M。【流程图】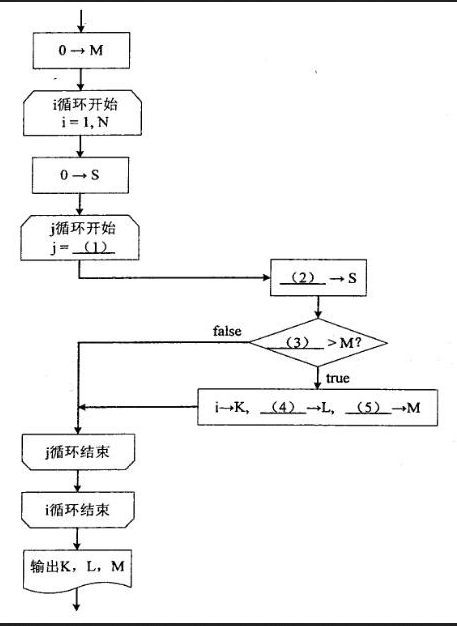
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为 1,格式为:循环控制变量=初值,终值答案:解析:1、j=i+1
2、S+A[j]
3、S
4、j-i+1
5、S -
第11题:
试题一(共 20 分)阅读下列说明和图,回答问题 1 至问题 3,将解答填入答题纸的对应栏内。【说明】设有二维整数数组(矩阵)A[1:m,1:n],其每行元素从左至右是递增的,每列元素从上到下是递增的。以下流程图旨在该矩阵中需找与给定整数 X 相等的数。如果找不到则输出“false”;只要找到一个(可能有多个)就输出“True”以及该元素的下标 i 和 j(注意数组元素的下标从 1 开始)。例如,在如下矩阵中查找整数 8,则输出伟:True,4,12 4 6 94 5 9 106 7 10 128 9 11 13流程图中采用的算法如下:从矩阵的右上角元素开始,按照一定的路线逐个取元素与给定整数 X 进行比较(必要时向左走一步或向下走一步取下一个元素),直到找到相等的数或超出矩阵范围(找不到)。【流程图】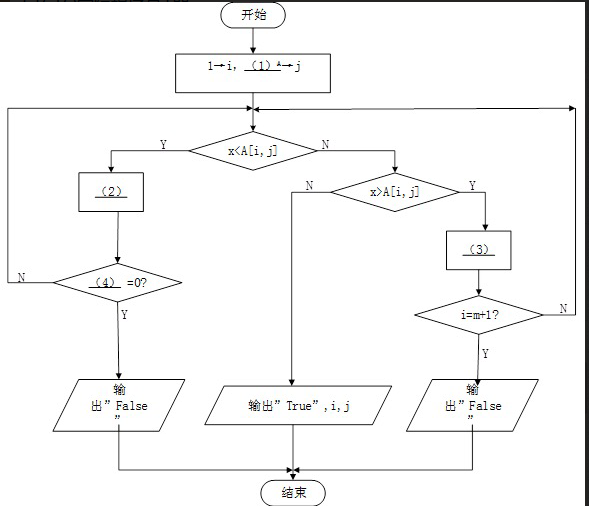
【问题】该算法的时间复杂数是()
供选择答案:A.O(1) B.O(m+n) C.(m*n) D,O(m2+n2)答案:解析:(1)n(2)j-1→j(3)i+1→I(4)j(5)C
【解析】
读题,可以看出元素查找的过程为从右上角开始,往右或者往下进行查找。因此,初始值i=1,j=n。如果查找值小于右上角值,则往右移动一位再进行比较。所以,第二空填j-1→j 。接下来是判断什么时候跳出循环。此时,终止循环的条件是:j=0,也就是其从最右端移到了最左端。再看X第12题:
设有n阶对称矩阵A,用数组s进行压缩存储,当i≥j时,A的数组元素aij相应于数组s的数组元素的下标为()。(数组元素的下标从1开始)
i(i-1)/2+j
略第13题:
阅读以下说明和流程图,回答问题将解答填入对应栏内。
[说明]
已知递推数列:a(1)=1,a (2s)= a (s),a(2s+1)=a (s)+a (s+1)(s 为正整数)。试求该数列的第n项与前n项中哪些项最大?最大值为多少?
算法分析:该数列序号分为奇数或偶数两种情况做不同递推,所得数列呈大小有规律的摆动。设置a数组,赋初值a (1)=1。根据递推式,在循环中分项序号s (2~n)为奇数或偶数作不同递推:每得一项 a (s),即与最大值max 作比较,如果a (s)>max,则max=a(i)。最后,在所有项中搜索最大项(因最大项可能多于一项),并打印最大值max。
[问题]
将流程图中的(1)~(5)处补充完整。
注:流程图中(1)循环开始的说明按照“循环变量名:循环初值,循环终值,增量”格式描述。
[流程图]
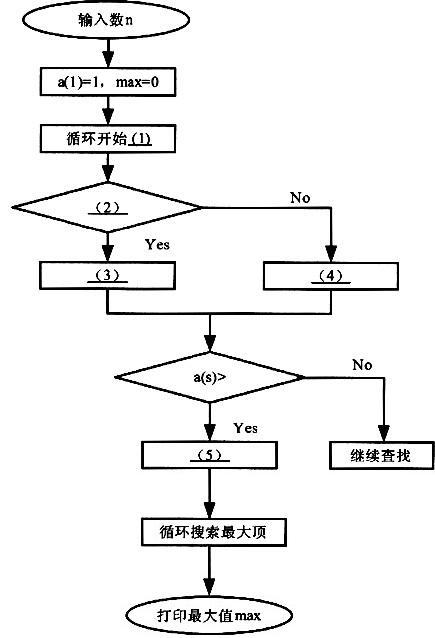 正确答案:(1)for s=2 to n (2) mod(s2)=0 (3) a(s)=a(s/2) (4) a(s)=a(s+1)/2+a(s-1)/2) (5) max=a(s)
正确答案:(1)for s=2 to n (2) mod(s2)=0 (3) a(s)=a(s/2) (4) a(s)=a(s+1)/2+a(s-1)/2) (5) max=a(s)
(1)for s=2 to n (2) mod(s,2)=0 (3) a(s)=a(s/2) (4) a(s)=a(s+1)/2+a(s-1)/2) (5) max=a(s)第14题:
阅读下列说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】 设有二维整数数组(矩阵)A[1:m,1:n],其每行元素从左到右是递增的,每列元素从上到下是递增的。以下流程图旨在该矩阵中需找与给定整数X相等的数。如果找不到则输出“false”;只要找到一个(可能有多个)就输出“True”以及该元素的下标i和j(注意数组元素的下标从1开始)。 例如,在如下矩阵中查找整数8,则输出伟:True,4,1 2 4 6 9 4 5 9 10 6 7 10 12 8 9 11 13 流程图中采用的算法如下:从矩阵的右上角元素开始,按照一定的路线逐个取元素与给定整数X进行比较(必要时向左走一步或向下走一步取下一个元素),直到找到相等的数或超出矩阵范围(找不到)。
【流程图】
 【问题】该算法的时间复杂数是() 供选择答案:A.O(1) B.O(m+n) C.O(m*n) D,O(m²+n²)正确答案:(1)n
【问题】该算法的时间复杂数是() 供选择答案:A.O(1) B.O(m+n) C.O(m*n) D,O(m²+n²)正确答案:(1)n
(2)j-1→j
(3)i+1→I
(4)j
(5)C
第15题:
?????? 阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的
对应栏内。
【说明】
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾
依次分离出各个关键词{A(i)li=l,…,n}(n>1)}.其中包含了很多重复项,经下面的流程
处理后,从中挑选出所有不同的关键词共m个{K(j)[j=l,…,m},而每个关键词K(j)出现的次数为NK(j).j=l,…,m。

??????
正确答案:
??流程图中的第1框显然是初始化。A(1)→K(1)意味着将本书的第1个关键词作为选出的第1个关键词。1→NK(1)意味着此时该关键词的个数置为1。m是动态选出的关键词数目,此时应该为1,因此(1)处应填1。?本题的算法是对每个关键词与已选出的关键词进行逐个比较。凡是遇到相同的,相??应的计数就增加1;如果始终没有遇到相同关键词的,则作为新选出的关键词。流程图第2框开始对i=2,n循环,就是对书中其他关键词逐个进行处理。流程图第3框开始j=l,m循环,就是按已进出的关键词依次进行处理。接着就是将关键词A(i)与选出的关键词K(j)进行比较。因此(2)处应填K(j)。如果A(i)=K(j),则需要对计数器NK(j)增1.即执行NK(j)+1→NK(j)。因此(3)处应填NK(j)+I→NK(j)。执行后,需要跳出j循环,继续进行i循环,即根据书中的下一个关键词进行处理。如果A(i)不等于NK(j),则需要继续与下个NK(j)进行比较,即继续执行j循环。如果直到j循环结束仍没有找到匹配的关键词,则要将该A(i)作为新的已选出的关键词。因此,应执行A(i)→K(m+1)以及m+l→m。更优的做法是先将计数器m增1,再执行A(j)→K(m)。因此(4)处应填m+l→m,(5)处应填A(i)。试题一参考答案(1)1(2)K(j)(3)Nk(j)+I→NK(j)或NK(j)十十或等价表示(4)m+l→m或m++或等价表示(5)A(i)??第16题:
●试题一
阅读下列说明和流程图,将应填入(n)处的语句写在答题纸的对应栏内。
【说明】
下列流程图用于从数组K中找出一切满足:K(I)+K(J)=M的元素对(K(I),K(J))(1≤I≤J≤N)。假定数组K中的N个不同的整数已按从小到大的顺序排列,M是给定的常数。
【流程图】
此流程图1中,比较"K(I)+K(J)∶M"最少执行次数约为 (5) 。

图1
正确答案:
●试题一【答案】(1)(2)<(3)I+l->I(4)J-1->J(5)「N/2」【解析】该算法的思路是:设置了两个变量I和J,初始时分别指向数组K的第一个元素和最后一个元素。如果这两个元素之和等于M时,输出结果,并这两个指针都向中间移动;如果小于M,则将指针I向中间移动(因为数组K已按从小到大的顺序排列);如果大于M,则将指针J向中间移动(因为数组K已按从小到大的顺序排列)。当IJ时,说明所有的元素都搜索完毕,退出循环。根据上面的分析,(1)、(2)空要求填写循环结束条件,显然,(1)空处应填写"",(2)空处应填写"<"。这里主要要注意I=J的情况,当I=J时,说明指两个指针指向同一元素,应当退出循环。(3)空在流程图有两处,一处是当K(I)+K(J)=M时,另一处是当K(I)+K(J)<M时,根据上面分析这两种情况都要将指针I向中间移动,即"I+1->I"。同样的道理,(4)空处应填写"J-1->J"。比较"K(I)+K(J):M"最少执行次数发生在第1元素与第N个元素之和等于M、第2元素与第N-1个元素之和等于M、……,这样每次比较,两种指针都向中间移动,因此最小执行次数约为"N-2"。第17题:
试题一(共 15 分)
阅读以下说明和流程图,填补流程图中的空缺(1)~(9) ,将解答填入答题纸的对应栏内。
[说明]
假设数组 A 中的各元素 A(1),A(2) ,…,A(M)已经按从小到大排序(M≥1) ;数组 B 中的各元素 B(1),B(2),…,B(N)也已经按从小到大排序(N≥1) 。执行下面的流程图后, 可以将数组 A 与数组 B 中所有的元素全都存入数组 C 中, 且按从小到大排序 (注意:序列中相同的数全部保留并不计排列顺序) 。例如,设数组 A 中有元素:2,5,6,7,9;数组B 中有元素:2,3,4,7;则数组 C 中将有元素:2,2,3,4,5,6,7,7,9。
[流程图]
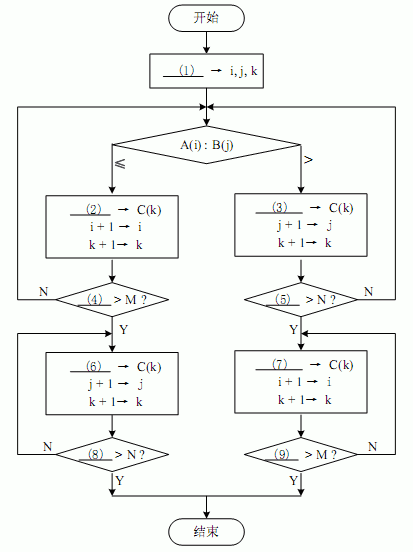 正确答案:
正确答案:
第18题:
阅读下列说明和流程图,填补流程图中的空缺(1)~(9),将解答填入答题纸的对应栏内。【说明】假设数组A中的各元素A⑴,A (2),…,A (M)已经按从小到大排序(M>1):数组B中的各元素B(1) , B (2) . B (N)也已经按从小到大排序(N≥1)。执行下面的流程图后,可以将数组A与数组B中所有的元素全都存入数组C中,且按从小到大排序(注意:序列中相同的数全部保留并不计排列顺序)。例如,设数组A中有元素: 2,5,6,7,9;数组B中有元素: 2,3,4,7;则数组C中将有元素: 2,2,3,4,5,6,7,7,9.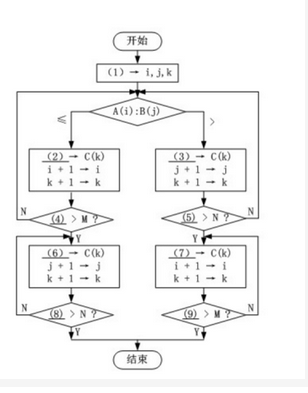 答案:解析:(1)1 (2)A (i) (3) B (j)⑷ i (5)J(6) B (j)(7) A (i)(8) j(9) i
答案:解析:(1)1 (2)A (i) (3) B (j)⑷ i (5)J(6) B (j)(7) A (i)(8) j(9) i第19题:
阅读以下说明和流程图,填补流程图和问题中的空缺(1)~(5),将解答填入答题纸的对应栏内。【说明】设整型数组A[1:N]每个元素的值都是1到N之间的正整数。一般来说,其中会有一些元素的值是重复的,也有些数未出现在数组中。下面流程图的功能是查缺查重,即找出A[1:N]中所有缺的或重复的整数,并计算其出现的次数(出现次数为0时表示缺)。流程图中采用的算法思想是将数组A的下标与值看作是整数集[1:N]加上的一个映射,并用数组C[1:N]记录各整数出现的次数,需输出所有缺少的或重复的数及其出现的次数。【流程图】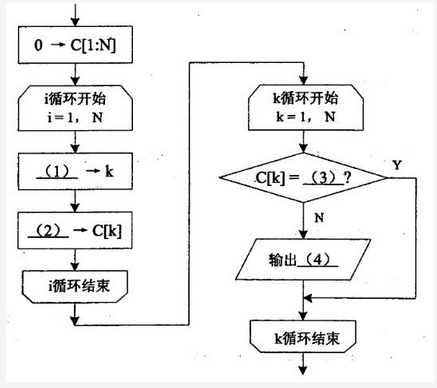
【问题】 如果数组A[1:5]的元素分别为{3,2,5,5,1},则算法流程结束后输出结果为: (5) 输出格式为:缺少或重复的元素,次数(0表示缺少)答案:解析:(1)A[i](2)C[k]+1(3)1(4)k和C[k](5)4,{1,1,1,0,2}
【解析】
(1)A[i](2)C[k]+1(3)1(4)k和C[k](5)4,{1,1,1,0,2}第20题:
阅读说明和流程图,填补流程图中的空缺(1)?(5),将答案填入答题纸对应栏内。【说明】本流程图用于计算菲波那契数列{a1=1,a2=1,…,an=an-1+an-2!n=3,4,…}的前n项(n>=2) 之和S。例如,菲波那契数列前6项之和为20。计算过程中,当前项之前的两项分别动态地保存在变量A和B中。【流程图】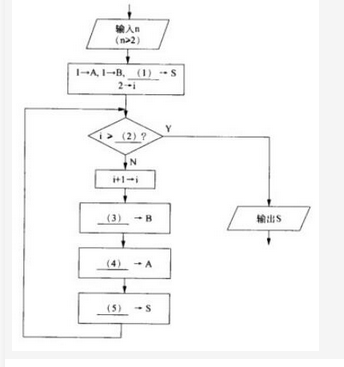 答案:解析:(1)2或A+B(2)n(3)A+B(4)B-A(5)S+B
答案:解析:(1)2或A+B(2)n(3)A+B(4)B-A(5)S+B
【解析】
菲波那契数列的特点是首2项都是1,从第3项开始,每一项都是前两项之和。该数列的前几项为1,1,2, 3,5,8,…。在流程图中,送初始值1—A,2—B后,显然前2项的和S应等于2,所以(1)处应填2 (或A+B)。此时2→i (i表示动态的项编号),说明已经计算出前2项之和。接着判断循环的结束条件。显然当i=n时表示已经计算出前n项之和,循环可以结束了。因此(2)处填n。判断框中用“>”或“≥”的效果是一样的,因为随着i的逐步增1,只要有i=n结束条件就不会遇到i>n的情况。不过编程的习惯使循环结束条件扩大些,以防止逻辑出错时继续循环。接下来i+1→i表示数列当前项的编号增1,继续往下计算。原来的前两项值(分别在变量A和B中)将变更成新的前两项再放到变量A和B中。
首先可以用A+B—B实现(原A) + (原B)—(新B),因此(3)处填A+B。为了填新A值(原来的B值),不能用B—A,因为变量B的内容已经改变为(原A) + (原B),而B-A正是((原A) + (原B))-(原A)=(原B),因此可以用B-A—A来实现新A的赋值。这样,(4)处填B-A。最后应是前n项和值的累加(比原来的S值增加了新B值),所以(5)处应填S+B。填完各个空后,最好再用具体的数值来模拟流程图走几个循环检查所填的结果(这是防止逻辑上出错的好办法)。第21题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
下面流程图的功能是:在给定的一个整数序列中查找最长的连续递增子序列。设序列存放在数组A[1:n](n≥2)中,要求寻找最长递增子序列A[K:K+L-1](即A[K]<A[K+1]<…<A[K+L-1])。流程图中,用Kj和Lj分别表示动态子序列的起始下标和长度,最后输出最长递增子序列的起始下标K和长度L。
例如,对于序列A={1,2,4,4,5,6,8,9,4,5,8},将输出K=4,L=5。
[流程图]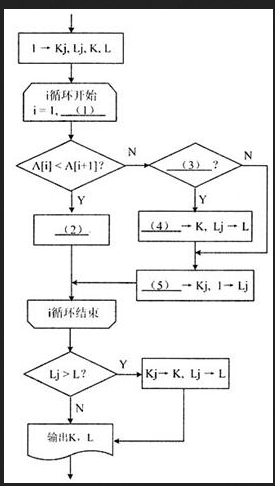
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为:循环控制变量=初值,终值答案:解析:n-1
Lj+1→Lj
Lj>L
Kj
i+1
【解析】
本题考查程序员在设计算法,理解并绘制程序流程图方面的能力。
本题的目标是:在给定的一个整数序列中查找最长的连续递增子序列。查找的方法是:对序列中的数,从头开始逐个与后面邻接的数进行比较。若发现后面的数大于前面的数,则就是连续递增的情况;若发现后面的数并不大,则以前查看的数中,要么没有连续递增的情况,要么连续递增的情况已经结束,需要再开始新的查找。
为了记录多次可能出现的连续递增情况,需要动态记录各次出现的递增子序列的起始位置(数组下标K1)和长度(Lj)。为了求出最大长度的递增子序列,就需要设置变量L和K,保存迄今为止最大的Lj及其相应的Kj。正如打擂台一样,初始时设置擂主L=1,以后当Li>L时,就将Lj放到L中,作为新的擂主。擂台上始终是迄今为止的连续递增序列的最大长度。而Kj则随Lj→L而保存到K中。
由于流程图中最关键的步骤是比较A[i]与A[i+1],因此对i的循环应从1到n-1,而不是1到n。最后一次比较应是"A[n-1]<A[n]?"。因此(1)处应填n-1。
当A[i]<A[i+1]成立时,这是递增的情况。此时应将动态连续递增序列的长度增1,因此(2)处应填写Li+1→Lj。
当A[i]<A[i+1]不成立时,表示以前可能存在的连续递增已经结束。此时的动态长度Li应与擂台上的长度L进行比较。即(3)处应填Lj>L。
当Lj>L时,则Lj将做新的擂主(Lj→L),同时执行Kj→K。所以(4)处应填Kj。
当Lj→L不成立时,L不变,接着要从新的下标i+1处开始再重新查找连续递增子序列。因此(5)处应填i+1。长度Lj也要回到初始状态1。
循环结束时,可能还存在最后一个动态连续子序列(从下标Kj那里开始有长度Lj的子序列)没有得到处理。因此还需要再打一次擂台,看是否超过了以前的擂主长度。一旦超过,还应将其作为擂主,作为查找的结果。第22题:
第一题 阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
【说明】
对于大于1的正整数n,(x+1)n可展开为
问题:1.1 【流程图】
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1。
格式为:循环控制变量=初值,终值,递增值。答案:解析:(1)2,n,1
(2)A[k]
(3)k-1,1,-1
(4)A[i]+A[i-1]
(5)A[i]
【解析】
(1)(3)空为填写循环初值终值和递增值,题目中给出的格式为循环控制变量=初值,终值,递增值。按照题意,实质为求杨辉三角。如下图: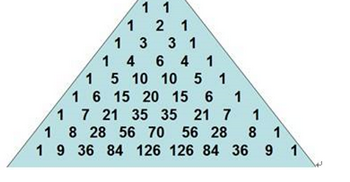

第23题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
【说明】
设有整数数组A[1:N](N>1),其元素有正有负。下面的流程图在该数组中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标K、元素个数L以及最大的和值M。
例如,若数组元素依次为3,-6,2,4,-2,3,-1,则输出K=3,L=4,M=7。该流程图中考察了A[1:N]中所有从下标i到下标j(j≥i)的各元素之和S,并动态地记录其最大值M。
【流程图】
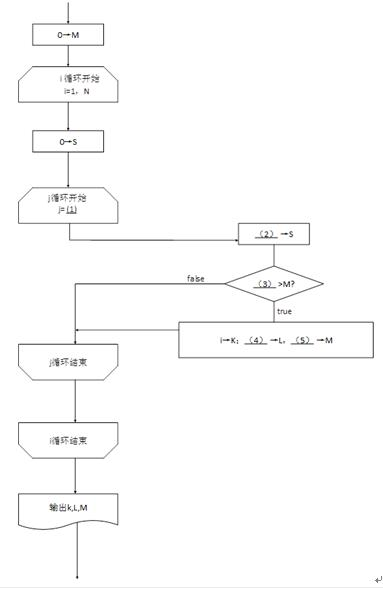
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为:循环控制变量=初值,终值答案:解析:(1)(1)i,N
(2)S+A[j]
(3)S
(4)j-i+1
(5)S
【解析】
要想在数组中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标K、元素个数L以及最大的和值M
那么,会将数组从第一个元素出发,依次比较A[1],A[1] +A[2],A[1] +A[2]+A[3],……,A[1] +A[2]+…+A[N],然后再比较A[2], A[2] +A[3],A[2] +A[3]+A[4],……,A[2] +A[3]+…+A[N],然后再比较A[3] +A[4],A[3] +A[4]+A[5],……,A[3] +A[4]+…+A[N],直到最后一个元素A[N]。按照这种逻辑,要使用两个循环,且要保存之前求和项。一个是i循环,从1到N递增,另一个是j循环,j表示的是求和项的最大下标值,那么j从i开始,且要小于N。 S+A[j]->S不断保留A[i]+ A[i+1]+…A[j]的值,直到j循环结束。并将S的值与之前保存的M的值进行比较,如果S>M,则将S的值赋给M,并求出L值,在这里,i是最小下标值,j是最大下标值,那么L=j-i+1。如果S