
广度优先遍历的含义是:从图中某个顶点v出发,在访问了v之后依次访问v的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,且“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。(38)是下图的广度优先遍历序列。A.1 2 6 34 5B.1 2 34 5 6C.1 6 5 2 34D.1 64 52 3
题目
广度优先遍历的含义是:从图中某个顶点v出发,在访问了v之后依次访问v的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,且“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。(38)是下图的广度优先遍历序列。
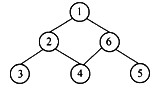
A.1 2 6 34 5
B.1 2 34 5 6
C.1 6 5 2 34
D.1 64 52 3
相似考题
参考答案和解析
解析:本题考查图结构的基本运算。根据题目描述,对题中图进行广度优先遍历时,先访问顶点1,由于2和6是顶点 1的邻接顶点,因此接下来应访问顶点2或顶点6,若先访问顶点2,此时的访问序列为 1 2 6;反之,访问序列则为1 6 2,然后访问顶点2、6(或6、2)的邻接顶点。因此,最后的遍历序列为1 26 34 5、1 2 6 3 54、1 62 54 3或1 624 5 3。
更多“广度优先遍历的含义是:从图中某个顶点v出发,在访问了v之后依次访问v的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,且“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。(38)是下图的广度优先遍历序列。A.1 2 6 34 5B.1 2 34 5 6C.1 6 5 2 34D.1 64 52 3”相关问题
-
第1题:
图的遍历是从图中的某个顶点出发,按照某种搜索策略访问图中所有顶点且每个顶点仅访问一次。()此题为判断题(对,错)。
参考答案:正确
-
第2题:
若从无向图的一个顶点出发进行广度优先遍历可访问到图中的所有顶点,则该图一定是连通图。()此题为判断题(对,错)。
参考答案:正确
-
第3题:
若从无向图的一个顶点出发进行广度优先遍历可访问到图中所有顶点,则该图一定是连通图。()此题为判断题(对,错)。
参考答案:正确
-
第4题:
● 广度优先遍历的含义是:从图中某个顶点 v出发,在访问了 v 之后依次访问 v的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,且“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。 (38) 是下图的广度优先遍历序列。
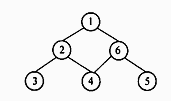
(38)
A. 1 2 6 3 4 5
B. 1 2 3 4 5 6
C. 1 6 5 2 3 4
D. 1 6 4 5 2 3
正确答案:A
-
第5题:
阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 图是很多领域中的数据模型,遍历是图的一种基本运算。从图中某顶点v出发进行广度优先遍历的过程是: ①访问顶点v; ②访问V的所有未被访问的邻接顶点W1 ,W2 ,..,Wk; ③依次从这些邻接顶点W1 ,W2 ,..,Wk出发,访问其所有未被访问的邻接顶点;依此类推,直到图中所有访问过的顶点的邻接顶点都得到访问。 显然,上述过程可以访问到从顶点V出发且有路径可达的所有顶点。对于从v出发不可达的顶点u,可从顶点u出发再次重复以上过程,直到图中所有顶点都被访问到。 例如,对于图4-1所示的有向图G,从a出发进行广度优先遍历,访问顶点的一种顺序为a、b、c、e、f、d。

 设图G采用数组表示法(即用邻接矩阵arcs存储),元素arcs[i][j]定义如下:
设图G采用数组表示法(即用邻接矩阵arcs存储),元素arcs[i][j]定义如下: 图4-1的邻接矩阵如图4-2所示,顶点a~f对应的编号依次为0~5.因此,访问顶点a的邻接顶点的顺序为b,c,e。 函数BFSTraverse(Graph G)利用队列实现图G的广度优先遍历。 相关的符号和类型定义如下: define MaxN 50 /*图中最多顶点数*/ typedef int AdjMatrix[MaxN][MaxN]; typedef struct{ int vexnum, edgenum; /*图中实际顶点数和边(弧)数*/ AdjMatrix arcs; /*邻接矩阵*/ )Graph; typedef int QElemType; enum {ERROR=0;OK=1}; 代码中用到的队列运算的函数原型如表4-1所述,队列类型名为QUEUE。 表4-1 实现队列运算的函数原型及说明
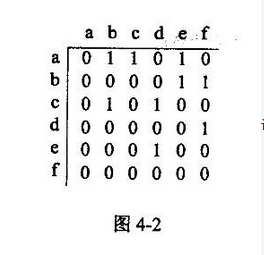
图4-1的邻接矩阵如图4-2所示,顶点a~f对应的编号依次为0~5.因此,访问顶点a的邻接顶点的顺序为b,c,e。 函数BFSTraverse(Graph G)利用队列实现图G的广度优先遍历。 相关的符号和类型定义如下: define MaxN 50 /*图中最多顶点数*/ typedef int AdjMatrix[MaxN][MaxN]; typedef struct{ int vexnum, edgenum; /*图中实际顶点数和边(弧)数*/ AdjMatrix arcs; /*邻接矩阵*/ )Graph; typedef int QElemType; enum {ERROR=0;OK=1}; 代码中用到的队列运算的函数原型如表4-1所述,队列类型名为QUEUE。 表4-1 实现队列运算的函数原型及说明
【代码】 int BFSTraverse(Graph G) {//对图G进行广度优先遍历,图采用邻接矩阵存储 unsigned char*visited; //visited[]用于存储图G中各顶点的访问标志,0表示未访问 int v, w, u; QUEUEQ Q; ∥申请存储顶点访问标志的空间,成功时将所申请空间初始化为0 visited=(char*)calloc(G.vexnum, sizeof(char)); If( (1) ) retum ERROR; (2) ; //初始化Q为空队列 for( v=0; v<G.vexnum; v++){ if(!visited[v]){ //从顶点v出发进行广度优先遍历 printf("%d”,v); //访问顶点v并将其加入队列 visited[v]=1; (3) ; while(!isEmpty(Q)){ (4) ; //出队列并用u表示出队的元素 for(w=0;v<G.vexnum; w++){ if(G.arcs[u][w]!=0&& (5) ){ //w是u的邻接顶点且未访问过 printf("%d”, w); //访问顶点w visited[w]=1; EnQueue(&Q, w); } } } } free(visited); return OK; )//BFSTraverse
正确答案:1、visited==NULL
2、InitQueue(&Q)
3、EnQueue(&Q,v)
4、DeQueue(&Q,&u)
5、visited==0
-
第6题:
阅读下列说明和C代码,回答问题1至问题2,将解答写在答题纸的对应栏内。
【说明】
一个无向连通图G点上的哈密尔顿(Hamiltion)回路是指从图G上的某个顶点出发,经过图上所有其他顶点一次且仅一次,最后回到该顶点的路径。哈密尔顿回路算法的基础如下:假设图G存在一个从顶点V0出发的哈密尔顿回路V1--V2--V3--...--Vn-1--V0。算法从顶点V0出发,访问该顶点的一个未被访问的邻接顶点V1,接着从顶点V1出发,访问V1一个未被访问的邻接顶点V2,..。;对顶点Vi,重复进行以下操作:访问Vi的一个未被访问的邻接接点Vi+1;若Vi的所有邻接顶点均已被访问,则返回到顶点Vi-1,考虑Vi-1的下一个未被访问的邻接顶点,仍记为Vi;直到找到一条哈密尔顿回路或者找不到哈密尔顿回路,算法结束。
【C代码】
下面是算法的C语言实现。
(1)常量和变量说明
n :图G中的顶点数
c[][]:图G的邻接矩阵
K:统计变量,当前已经访问的顶点数为k+1
x[k]:第k个访问的顶点编号,从0开始
Visited[x[k]]:第k个顶点的访问标志,0表示未访问,1表示已访问
(2)C程序
#include#include #define MAX 100voidHamilton(intn,int x[MAX,intc[MAX][MAX]){int;int visited[MAX];int k;/*初始化 x 数组和 visited 数组*/for (i=0:i
【问题1】(10分)
根据题干说明。填充C代码中的空(1)~(5)。
【问题2】(5分)
根据题干说明和C代码,算法采用的设计策略为( ),该方法在遍历图的顶点时,采用的
是( )方法(深度优先或广度优先)。答案:解析:【问题1】(10分)
1. visited[0] = 1
2. visited[x[k]] == 0
3. k==n-1&&c[x[k]][x[0]==1
4. visited[x[k]] = 1
5. k = k - 1
【问题2】(5分)
回溯法、深度优先。 -
第7题:
图的深度优先遍历算法中需要设置一个标志数组,以便区分图中的每个顶点是否被访问过。()答案:对解析:深度优先遍历算法需设置一个数组,用来标志顶点是否被访问过。 -
第8题:
阅读下列说明和?C?代码,回答问题?1?至问题?2,将解答写在答题纸的对应栏内。
【说明】
一个无向连通图?G?点上的哈密尔顿(Hamiltion)回路是指从图?G?上的某个顶点出发,经过图上所有其他顶点一次且仅一次,最后回到该顶点的路劲。一种求解无向图上哈密尔顿回
路算法的基础私下如下:假设图?G?存在一个从顶点?V0?出发的哈密尔顿回路?V1——V2——V3——...——Vn-1——V0。算法从顶点?V0?出发,访问该顶点的一个未被访问的邻接顶点?V1,接着从顶点?V1?出发,访问?V1?一个未被访问的邻接顶点?V2,..。;对顶点?Vi,重复进行以下操作:访问?Vi?的一个未被访问的邻接接点?Vi+1;若?Vi?的所有邻接顶点均已被访问,则返回到顶点?Vi-1,考虑Vi-1?的下一个未被访问的邻接顶点,仍记为?Vi;知道找到一条哈密尔顿回路或者找不到哈密尔顿回路,算法结束。
【C?代码】
下面是算法的?C?语言实现。
(1)常量和变量说明
n :图?G?中的顶点数
c[][]:图?G?的邻接矩阵
K:统计变量,当期已经访问的定点数为?k+1
x[k]:第?k?个访问的顶点编号,从?0?开始
Visited[x[k]]:第?k?个顶点的访问标志,0?表示未访问,1?表示已访问
⑵C?程序


【问题?1】(10?分)
根据题干说明。填充?C?代码中的空(1)~(5)。
【问题?2】(5?分)
根据题干说明和?C?代码,算法采用的设计策略为( ),该方法在遍历图的顶点时,采用的
是(?)方法(深度优先或广度优先)。答案:解析:【问题 1】(10 分)
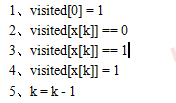
【问题 2】(5 分)
回溯法、深度优先。 -
第9题:
对于任意一个图,从它的某个结点进行一次深度或广度优先遍历可以访问到该图的每个顶点
正确答案:错误 -
第10题:
下列有关图遍历的说法中不正确的是()
- A、连通图的深度优先搜索是一个递归过程
- B、图的广度优先搜索中邻接点的寻找具有“先进先出”的特征
- C、非连通图不能用深度优先搜索法
- D、图的遍历要求每一顶点仅被访问一次
正确答案:D -
第11题:
单选题下列有关图遍历的说法中不正确的是()A连通图的深度优先搜索是一个递归过程
B图的广度优先搜索中邻接点的寻找具有“先进先出”的特征
C非连通图不能用深度优先搜索法
D图的遍历要求每一顶点仅被访问一次
正确答案: C解析: 暂无解析 -
第12题:
判断题对任意一个图,从某顶点出发进行一次深度优先或广度优先遍历,可访问图的所有顶点。A对
B错
正确答案: 错解析: 暂无解析 -
第13题:
阅读下列算法说明和算法,将应填入(n)处的语句写在对应栏内。
1. 【说明】
实现连通图G的深度优先遍历(从顶点v出发)的非递归过程。
【算法】
第一步:首先访问连通图G的指定起始顶点v;
第二步:从V出发,访问一个与v(1)p,再从顶点P出发,访问与p(2)顶点q,然后从q出发,重复上述过程,直到找不到存在(3)的邻接顶点为止。
第三步:回退到尚有(4)顶点,从该顶点出发,重复第二、三步,直到所有被访问过的顶点的邻接点都已被访问为止。
因此,在这个算法中应设一个栈保存被(5)的顶点,以便回溯查找被访问过顶点的未被访问过的邻接点。
正确答案:(1)邻接的顶点 (2)邻接的且未被访问的 (3)未访问过 (4)未被访问过的邻接点的 (5)访问过
(1)邻接的顶点 (2)邻接的且未被访问的 (3)未访问过 (4)未被访问过的邻接点的 (5)访问过 解析:本题考查连通图的深度优先遍历算法的非递归过程。
在做题前,我们首先来了解一下图的遍历。和树的遍历类似,图的遍历也是从某个顶点出发,沿着某条搜索路径对图中每个顶点各做一次且仅做一次访问。
连通图的深度优先遍历可定义如下:首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点(亦称为从源点可达的顶点)均已被访问为止。其关键是每次遍历都是往下直到最后再往回搜索,找到还未被访问过的邻接点的顶点,然后从该顶点出发,对它及下面的顶点进行深度优先遍历。下面来具体分析其算法。
第(1)空在第二步中,在访问起始顶点v后应该访问的结点,那么这个结点肯定是与起始顶点v邻接的顶点,因此此空答案为“邻接的顶点”。
第(2)空是在访问p顶点后应该访问的顶点,接下来应该也是访问与p顶点邻接的顶点,但这个时候p顶点的邻接顶点中有已经被访问过了的顶点,因此在访问前还需判断此顶点是否被访问过了,所以此空答案为“邻接的且未被访问的”。
第(3)空也在第二步中,结合前后的内容,可以知道此空是要判断是否还可以找到与当前访问顶点邻接而未被访问的顶点,根据上面分析,如果找不到,才往回搜索,因此此空答案为“未访问过”。
第(4)空是回退过程中要注意的地方,一般回退到还未被访问过的邻接点的顶点,接着访问这个未被访问过的邻接点。因此此空答案为“未被访问过的邻接点的”。
第(5)空是存放在栈中的内容,栈具有后进先出的特点,根据上面对深度优先遍历的分析可以知道,在回退的过程中需要用到被访问过的顶点,而且回退的过程是按遍历的顶点的顺序回退的,越后被访问的顶点越先被回退,因此此空答案是“访问过”。 -
第14题:
若从无向图的一个顶点出发进行深度优先遍历可访问到图中所有顶点,则该图一定是连通图。()此题为判断题(对,错)。
参考答案:正确
-
第15题:
● 对连通图进行遍历前设置所有顶点的访问标志为 false(未被访问) ,遍历图后得到一个遍历序列,初始状态为空。深度优先遍历的含义是:从图中某个未被访问的顶点 v 出发开始遍历,先访问 v 并设置其访问标志为 true(已访问) ,同时将 v 加入遍历序列,再从 v 的未被访问的邻接顶点中选一个顶点,进行深度优先遍历;若 v的所有邻接点都已访问,则回到 v 在遍历序列的直接前驱顶点,再进行深度优先遍历,直至图中所有顶点被访问过。 (40) 是下图的深度优先遍历序列。
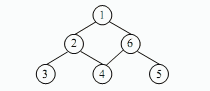
(40)
A. 1 2 3 4 6 5
B. 1 2 6 3 4 5
C. 1 6 2 5 4 3
D. 1 2 3 4 5 6
正确答案:A
-
第16题:
调用一次深度优先遍历可以访问到图中的所有顶点。
此题为判断题(对,错)。
正确答案:×
-
第17题:
试题四(共 15 分)阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】 图是很多领域中的数据模型,遍历是图的一种基本运算。从图中某顶点 v出发进行广度优先遍历的过程是:①访问顶点 v;②访问 V 的所有未被访问的邻接顶点 W1 ,W2 ,..,Wk;③依次从这些邻接顶点 W1 ,W2 ,..,Wk 出发,访问其所有未被访问的邻接顶 点;依此类推,直到图中所有访问过的顶点的邻接顶点都得到访问。显然,上述过程可以访问到从顶点 V 出发且有路径可达的所有顶点。对于 从 v 出发不可达的顶点 u,可从顶点 u 出发再次重复以上过程,直到图中所有顶 点都被访问到。例如,对于图 4-1 所示的有向图 G,从 a 出发进行广度优先遍历,访问顶点 的一种顺序为 a、b、c、e、f、d。图 4-1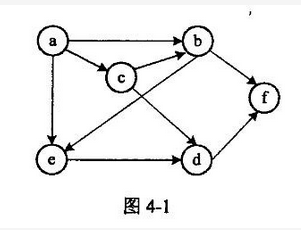
设图 G 采用数组表示法(即用邻接矩阵 arcs 存储),元素 arcs[i][ j]定义如下:

图 4-1 的邻接矩阵如图 4-2 所示,顶点 a~f 对应的编号依次为 0~5.因此,访问顶点 a 的邻接顶点的顺序为 b,c,e。函数 BFSTraverse(Graph G)利用队列实现图 G 的广度优先遍历。相关的符号和类型定义如下:#define MaxN:50 /*图中最多顶点数*/ typedef int AdjMatrix[MaxN][MaxN];typedef struct{int vexnum,edgenum;/*图中实际顶点数和边(弧)数*/ AdjMatrix arcs; /*邻接矩阵*/)Graph;typedef int QElemType; enum {ERROR=0;OK=l};代码中用到的队列运算的函数原型如表 4-1 所述,队列类型名为 QUEUE。
表 4-1 实现队列运算的函数原型及说明
【代码】int BFSTraverse(Graph G){//图 G 进行广度优先遍历,图采用邻接矩阵存储unsigned char*visited; //visited[]用于存储图 G 中各顶点的访问标 志,0 表示未访问int v,w;u;
QUEUEQ Q;∥申请存储顶点访问标志的空间,成功时将所申请空间初始化为 0 visited=(char*)calloc(G.vexnum, sizeof(char));If( (1) ) retum ERROR; (2) ; //初始化 Q 为空队列 for( v=0; v答案:解析:1、visited==NULL
2、InitQueue(&Q)
3、EnQueue(&Q,v)
4、DeQueue(&Q,&u)
5、visited==0 -
第18题:
下面关于图的遍历说法不正确的是()。A.遍历图的过程实质上是对每个顶点查找其邻接点的过程
B.深度优先搜索和广度优先搜索对无向图和有向图都适用
C.深度优先搜索和广度优先搜索对顶点访问的顺序不同,它们的时间复杂度也不相同
D.深度优先搜索是一个递归的过程,广度优先搜索的过程中需附设队列答案:C解析:深度优先搜索和广度优先搜索的时间算杂度相同,均为O(n+e)。 -
第19题:
调用一次深度优先遍历可以访问到图中的所有顶点。()答案:错解析:调用一次深度优先遍历不一定能访问到图中的所有顶点。 -
第20题:
对任意一个图,从某顶点出发进行一次深度优先或广度优先遍历,可访问图的所有顶点。
正确答案:错误 -
第21题:
下列关于图遍历的说法不正确的是()。
- A、连通图的深度优先搜索是一个递归过程
- B、图的广度优先搜索中邻接点的寻找具有“先进先出”的特征
- C、非连通图不能用深度优先搜索法
- D、图的遍历要求每一顶点仅被访问一次
正确答案:C -
第22题:
多选题以下说法中正确的是A连通图的广度优先搜索中一般要采用队列来暂存刚访问过的顶点
B图的深度优先搜索中一般要采用栈来暂存刚访问过的顶点
C有向图的遍历不可采用广度优先搜索方法
D无向图中的极大连通子图称为连通分量
正确答案: D,C解析: -
第23题:
判断题对于任意一个图,从它的某个结点进行一次深度或广度优先遍历可以访问到该图的每个顶点A对
B错
正确答案: 对解析: 暂无解析