
阅读下列C程序和程序说明,将应填入(n)处的字句写在对应栏内。【说明】下面是一个用C编写的快速排序算法。为了避免最坏情况,取基准记录pivot时,采用从left、right和mid=[(left+right)/2]中取中间值,并交换到right位置的办法。数组a存放待排序的一组记录,数据类型为T,left和right是待排序子区间的最左端点和最右端点。void quicksort (int a[], int left, int right) {int temp;if (left<right) {hat p
题目
阅读下列C程序和程序说明,将应填入(n)处的字句写在对应栏内。
【说明】下面是一个用C编写的快速排序算法。为了避免最坏情况,取基准记录pivot时,采用从left、right和mid=[(left+right)/2]中取中间值,并交换到right位置的办法。数组a存放待排序的一组记录,数据类型为T,left和right是待排序子区间的最左端点和最右端点。
void quicksort (int a[], int left, int right) {
int temp;
if (left<right) {
hat pivot = median3 (a, left, right); //三者取中子程序
int i = left, j = right-1;
for(;;){
while (i <j && a[i] < pivot) i++;
while (i <j && pivot < a[j]) j--;
if(i<j){
temp = a[i]; a[j] = a[i]; a[i] = temp;
i++; j--;
}
else break;
}
if (a[i] > pivot)
{temp = a[i]; a[i] = a[right]; a[right] = temp;}
quicksort( (1) ); //递归排序左子区间
quieksort(a,i+1 ,right); //递归排序右子区间
}
}
void median3 (int a[], int left, int right)
{ int mid=(2);
int k = left;
if(a[mid] < a[k])k = mid;
if(a[high] < a[k]) k = high; //选最小记录
int temp = a[k]; a[k] = a[left]; a[left] = temp; //最小者交换到 left
if(a[mid] < a[right])
{temp=a[mid]; a[mid]=a[right]; a[right]=temp;}
}
消去第二个递归调用 quicksort (a,i+1,right)。 采用循环的办法:
void quicksort (int a[], int left, int right) {
int temp; int i,j;
(3) {
int pivot = median3(a, left, right); //三者取中子程序
i = left; j = righi-1;
for (;; ){
while (i<j && a[i] < pivot)i++;
while (i<j && pivot <a[j]) j--;
if(i <j) {
temp = a[i]; a[j]; = a[i]; a[i]=temp;
i++; j--;
}
else break;
}
if(a[i]>pivot){(4);a[i]=pivot;}
quicksoft ((5)); //递归排序左子区间
left = i+1;
}
}
相似考题
更多“阅读下列C程序和程序说明,将应填入(n)处的字句写在对应栏内。【说明】下面是一个用C编写的快速排序算法。为了避免最坏情况,取基准记录pivot时,采用从left、right和mid=[(left+right)/2]中取中间值,并交换到right位置的办法。数组a存放待排序的一组记录,数据类型为T,left和right是待排序子区间的最左端点和最右端点。void quicksort (int a[], int left, int right) {int temp;if (left<right) {hat p”相关问题
-
第1题:
使用VC6打开考生文件夹下的工程test41_3。此工程包含一个test41_3.cpp,其中定义了类Rectangle,但该类的定义并不完整。请按要求完成下列操作,将程序补充完整。
(1)定义类Rectangle的私有数据成员left,top和fight,bottom,它们都是int型的数据。请在注释“//**1**”之后添加适当的语句。
(2)添加类Rectangle的带四个int型参数1、t、r、b的构造函数的声明,并使这四个参数的默认值均为0,请在注释“//**2**”之后添加适当的语句。
(3)添加类Rectangle的成员函数SetTop()参数为int型的t,作用为把t的值赋给类的数据成员top,添加类Rectangle的成员函数SetBottom()参数为int型的t,作用为把t的值赋给类的数据成员bottom,请在注释“//**3**”之后添加适当的语句。
(4)完成派生类Rectangle的成员函数Show()的定义,使其以格式“right-bottom point is(right,bottom)”输出,请在注释“//**4**”之后添加适当的语句。
源程序文件test41_3.cpp清单如下:
include <iostream.h>
class Rectangle
{
// ** 1 **
int right, bottom;
public:
// ** 2 **
~ Rectangle(){};
void Assign(int 1, int t, int r, int b);
void SetLeft(int t){left = t;}
void SetRight(int t){right = t;}
// ** 3 **
void SetBottom(int t){bottom = t;}
void Show();
};
Rectangle::Rectangle(int 1, int t, int r, int b)
{
left = 1; top = t;
right = r; bottom = b;
}
void Rectangle::Assign(int 1, int t, int r, int b)
{
left = 1; top = t;
right = r; bottom = b;
}
void Rectangle::Show()
{
cout<<"left-top point is ("<<left<<","<<top<<")"<<'\n';
// ** 4 **
}
void main()
{
Rectangle rect;
rect.Show();
rect.Assign(100,200,300,400);
rect.Show();
}
正确答案:(1) int left top; (2) Rectangle(int 1=0 int t=0 int r=0 int b=0); (3) void SetTop(int t){top=t;} (4) cout"right-bottom point is ("right""bottom")"'\n';
(1) int left, top; (2) Rectangle(int 1=0, int t=0, int r=0, int b=0); (3) void SetTop(int t){top=t;} (4) cout"right-bottom point is ("right","bottom")"'\n'; 解析:主要考查考生对于类的定义和定义一般成员函数的掌握,其中(2)中为了使构造函数可以不带参数,使用了对于参数给定默认值的方法,这点需要考生注意,(4)中连续的字符流的输出可以连续使用“”符号实现。 -
第2题:
阅读下列说明、流程图和算法,将应填(n)处的字句写在对应栏内。
[说明]
下面的流程图(如图3所示)用N - S盒图形式描述了数组A中的元素被划分的过程。其划分方法是:以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于A[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为 low,上界为high,数组中的元素互不相同。例如,对数组(4,2,8,3,6),以4为基准数的划分过程如下:

[流程图]
[算法说明]
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int A[],int low,int hieh)实现了上述流程图的划分过程并返回基准数在数组A中的下标。递归函数void sort(int A[],int L,int H)的功能是实现数组A中元素的递增排序。
[算法]
void sort(int A[],int L,int H) {
if (L<H) {
k=p(A,L,R); //p()返回基准数在数组A中的下标
sort((4)); //小于基准敷的元素排序
sort((5)); //大于基准数的元素排序
}
}
正确答案:(1)j--(2)i++(3)A[i]←pivot或[j]←pivot(4) ALk-1或ALk (5)Ak+1H或AkH
(1)j--(2)i++(3)A[i]←pivot或[j]←pivot(4) A,L,k-1或A,L,k (5)A,k+1,H或A,k,H 解析:题目考查快速排序算法。快速排序采用了一种分治的策略,通常称为分治法。其基本思想是:将原问题分解为若干个规模更小,但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。
快速排序的具体过程为:第一步,在待排序的n个记录中任取一个记录,以该记录的排序码为基准,将所有记录分成2组,第一组各记录的排序码都小于等于该排序码,第二组各记录的排序码都大于该排序码,并把该记录排在这2组中间,这个过程称为一次划分。第二步,采用同样的方法,对划分出来的2组元素分别进行快速排序,直到所有记录都排到相应的位置为止。
在进行一次划分时,若选定以第一个元素为基准,就可将第一个元素备份在变量pivot中,如图中的第①步所示。这样基准元素在数组中占据的位置就空闲出来了,因此下一步就从后向前扫描。如图中的第②步所示,找到一个比基准元素小的元素时为止,将其前移,如图中的第③步所示。然后再从前向后扫描,如图中的第④步所示,找到一个比基准元素大的元素时为止,将其后移,如图中的第⑤步所示。这样,从后向前扫描和从前向后扫描交替进行,直到扫描到同一个位置为止,如图中的第⑥步所示。
由题目中给出的流程图可知,以第一个元素作为基准数,并将A[low]备份至pivot,i用于从前向后扫描的位置指示器,其初值为low, j用于从后往前扫描的位置指示器,其初值为high。当i1)从后向前扫描数组A,在ipivot,就继续向前扫描(j--);如果被扫描的元素A[i]2)这时,再从前向后扫描,在ipivot就停止扫描,并将此元素的值赋给目前空闲着的A[j]。
3)这时又接第(1)步,直到i>j时退出循环。退出循环时,将pivot赋给当前的A[i](A[i]←pivot)。
递归函数的目的是执行一系列调用,直到到达某一点时递归终止。为了保证递归函数正常执行,应该遵守下面的规则:
1)每当一个递归函数被调用时,程序首先应该检查基本的条件是否满足,例如,某个参数的值等于0,如果是这种情形,函数应停止递归。
2)每次当函数被递归调用时,传递给函数一个或多个参数,应该以某种方式变得“更简单”,即这些参数应该逐渐靠近上述基本条件。例如,一个正整数在每次递归调用时会逐渐变小,以至最终其值到达0。
本题中,递归函数sort(int A[],int L, int H)有3个参数,分别表示数组A及其下界和上界。根据流程图可知,这里的L相当于流程图中的i,这里的H相当于流程图中的j。因为P()返回基准数所在数组A中的下标,也就是流程图中最后的“A[i]←pivot”中的i。根据快速排序算法,在第一趟排序后找出了基准数所在数组A中的下标,然后以该基准数为界(基准数在数组中的下标为k),把数组A分成2组,分别是A[L,…,k-1)和A[k+1,…,H),最后对这2组中的元素再使用同样的方法进行快速排序。 -
第3题:
从字符串S("abcdefg") 中返回子串B("cd") 的正确表达式是______。
A.Mid(S,3,2)
B. Right(Left(S,4) ,2)
C. Left(Right(S,5) ,2)
D. 以上都可以
正确答案:D
-
第4题:
从字符串S(“abcdefg”)中返回子串B(“cd”)的正确表达是( )。
A.Mid(S,3,2)
B.Right(Left(S,4),2)
C.Left(Right(S,5),2)
D.以上都可以
正确答案:D
解析:本题考察VBA的函数。Mid(字符串表达式>,N1>,[N2]):从字符串左边第N1个字符起截取N2个字符,选项A从字符串S左边第3个字符起截取2个字符是“cd”。在这里考生要注意,对于Mid函数,如果N1大于字符串的字符数,则返回零长度字符串;如果省略N2,则返回字符串中左边起N1个字符开始的所有字符。Left(字符串表达式>,N>):从字符串左边截取N个字符;Right(字符串表达式 >,N>):从字符串右边截取N个字符,由此可以判断出选项B和C都返回“cd”,这里也要注意,如果N值为0,返回零长度字符串,如果大于等于字符串的字符数,则返回整个字符串。答案为D。 -
第5题:
从字符串S("abcdefg")返回子串B("cd")的正确表达式为( )。A.Mid(S,3,2)B.Right(Left(S,4),2)C.Left(Right(S,5)2)D.以上都可以
正确答案:D
A项是从S中第三个字符起,返回2个字符。B项首先是返回左边的四个字符,即abcd.然后返回右边的2个字符,即cd.C项返回右边的5个字符,即cdefg,然后返回左边的两个字符。 -
第6题:
阅读以下说明和C++程序,将应填入(n)处的字句写在对应栏内。
【说明】以下程序实现了二叉树的结点删除算法,若树中存在要删除的结点,则删除它,否则返回。 FindNode ()函数能够在二叉树中找到给定值的结点,并返回其地址和父结点。
【C++程序】
template < class T >
void BinSTree < T >: :Delete( const T& item)
{
TreeNode < T > * DelNodePtr, * ParNodePtr, * RepNodePtr;
if(( DelNodePtr = FindNode (item,ParNodePtr)) = = NULL)
(1)
if(DelNodePtr→right = = NULL) //被删除结点只有一个子结点的情况
RepNodePtr = DelNodePtr→left;
else if( DelNodePtr→left = = NULL)
(2);
else // 被删除结点有两个子结点的情况
{
TreeNode < T >* PofRNodePtr = DelNodePtr;
RepNodePtr = DelNodePtr→left;
while(RepNodePtr→right ! = NULL)
{ //定位左子树的最右结点
PofRNodePtr =RepNodePtr;
RepNodePtr = RepNodePtr→right;
}
if(PofRNodePtr = = DelNodePtr) //左子树没有右子结点
(3);
else //用左子顷的最右结点替换删除的结点
{
(4)
RepNodePtr→left = DelNodePtr→left;
RepNodePtr→right = DelNodePtr→right;
}
}
if (5)//要删除结点是要结点的情况
root = RepNodePtr;
else if ( DelNodePtr→data < ParNodePtr→Data)
ParNodePtr→left = RepNodePtr;
else
ParNodePtr→right =RepNodePtr;
FirstTreeNode ( DelNodePtr ) ;//释放内存资源
size→;
}
正确答案:(1)return
(1)return 解析:树中找不到要删除的结点,直接返回。 -
第7题:
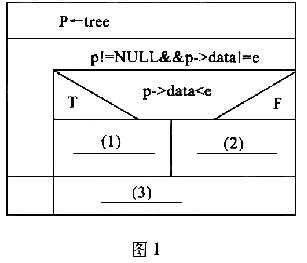
阅读下列说明和流程图,将应填入(n)的语句写在对应栏内。
【流程图说明】
下面的流程(如图1所示)用N-S盒图形式描述了在一棵二叉树排序中查找元素的过程,节点有3个成员:data, left和right。其查找的方法是:首先与树的根节点的元素值进行比较:若相等则找到,返回此结点的地址;若要查找的元素小于根节点的元素值,则指针指向此结点的左子树,继续查找;若要查找的元素大于根节点的元素值,则指针指向此结点的右子树,继续查找。直到指针为空,表示此树中不存在所要查找的元素。
【算法说明】
【流程图】
将上题的排序二叉树中查找元素的过程用递归的方法实现。其中NODE是自定义类型:
typedef struct node {
int data;
struct node * left;
struct node * right;
}NODE;
【算法】
NODE * SearchSortTree(NODE * tree, int e)
{
if(tree!=NULL)
{
if(tree->data<e)
(4); //小于查找左子树
else if(tree->data<e)
(5); //大于查找左子树
else return tree;
}
return tree;
}
正确答案:(1)p=p->left (2)ptr=p->right (3)return P (4) return SearchSortTree(tree->left ) (5)return SearchSortTree(tree->right)
(1)p=p->left (2)ptr=p->right (3)return P (4) return SearchSortTree(tree->left ) (5)return SearchSortTree(tree->right) 解析:所谓二叉排序树,指的是一棵为空的二叉树,或者是一棵具有如下特性的非空二叉树:
①若它的左子树非空,则左子树上所有结点的值均小于根结点的值。②若它的右子树非空,则右子树上所有结点的值均大干根结点的值。③左、右子树本身又各是一棵二叉排序树。
先来分析流程图。在流程图中只使用一个变量p,并作为循环变量来控制循环,所以循环体中必须修改这个值。当进入循环时,首先判断p是不是为空和该结点是不是要找的结点,如果这两个条件有一个满足就退出循环,返回prt,(如果是空,则返回NULL,说明查询失败;否则返回键值所在结点的指针。)因此(3)空处应当填写“return p”。如果两个条件都不满足,就用查找键值e与当前结点的关键字进行比较,小的话,将指针p指向左子树继续查找,大的话将指针P指向右子树继续查找。于是,(1)空处应当填写“p=p->left”,(2)空处应当填写“p=p->right”。
再来分析程序。虽然是递归算法,但实现思路和非递归是一样。首先用查找键值e与树根结点的关键字比较,如果值小的话,就在左子树中查找(即返回在左子树中查找结果);如果值大的话在右子树中查找(即返回在右子树中查找结果);如果相等的活就返回树根指针。因此(4)、(5)空分别应填写“return SearehSortTree(tree->left)”和“return SearehSoaTree(tree->right)”。 -
第8题:
阅读下列说明和C代码,回答问题1至问题3,将解答写在答题纸的对应栏内。 【说明】 采用归并排序对n个元素进行递增排序时,首先将n个元素的数组分成各含n/2个元素的两个子数组,然后用归并排序对两个子数组进行递归排序,最后合并两个已经排好序的子数组得到排序结果。 下面的C代码是对上述归并算法的实现,其中的常量和变量说明如下: arr:待排序数组 p,q,r:一个子数组的位置从p到q,另一个子数组的位置从q+1到r begin,end:待排序数组的起止位置 left,right:临时存放待合并的两个子数组 n1,n2:两个子数组的长度 i,j,k:循环变量 mid:临时变量 【C代码】
inciude<stdio.h> inciude<stdlib.h> define MAX 65536 void merge(int arr[],int p,int q,int r) { int *left, *right; int n1,n2,i,j,k; n1=q-p+1; n2=r-q; if((left=(int*)malloc((n1+1)*sizeof(int)))=NULL) { perror("malloc error"); exit(1); } if((right=(int*)malloc((n2+1)*sizeof(int)))=NULL) { perror("malloc error"); exit(1); } for(i=0;i<n1;i++){ left[i]=arr[p+i]; } left[i]=MAX; for(i=0; i<n2; i++){ right[i]=arr[q+i+1] } right[i]=MAX; i=0; j=0; for(k=p; (1) ; k++) { if(left[i]> right[j]) { (2) ; j++; }else { arr[k]=left[i]; i++; } } } void mergeSort(int arr[],int begin,int end){ int mid; if( (3) ){ mid=(begin+end)/2; mergeSort(arr,begin,mid); (4) ; merge(arr,begin,mid,end); } }
【问题1】 根据以上说明和C代码,填充1-4。 【问题2】 根据题干说明和以上C代码,算法采用了(5)算法设计策略。 分析时间复杂度时,列出其递归式位(6),解出渐进时间复杂度为(7)(用O符号表示)。空间复杂度为(8)(用O符号表示)。 【问题3】 两个长度分别为n1和n2的已经排好序的子数组进行归并,根据上述C代码,则元素之间比较次数为(9)。
正确答案:【问题1】(8分)
(1)k<=r
(2)arr[k]=right[j]
(3)begin<end
(4)mergeSort(arr,mid+1,end)【问题2】(5分)
(5)分治
(6)T(n)=2T(n/2)+O(n)
(7)O(nlogn)
(8)O(n)【问题3】(2分)
(9)n1+n2
-
第9题:
●试题二
阅读下列说明、流程图和算法,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
下面的流程图(如图3所示)用N-S盒图形式描述了数组A中的元素被划分的过程。其划分方法是:以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于A[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。例如,对数组(4,2,8,3,6),以4为基准数的划分过程如下:
【流程图】
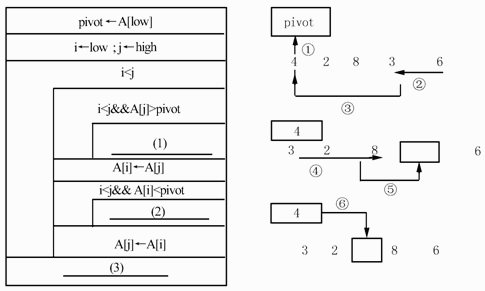
图3流程图
【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int A[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组A中的下标。递归函数void sort(int A[],int L,int H)的功能是实现数组A中元素的递增排序。
【算法】
void sort (int A[], int 1,int H){
if ( L<H){
k=p(A,L,R);//p()返回基准数在数组A中的下标
sort( (4) );//小于基准数的元素排序
sort( (5) );//大于基准数的元素排序
}
}
正确答案:
●试题二【答案】(1)j--(2)i++(3)A[i]←pivot或[j]←pivot(4)A,L,k-1或A,L,k(5)A,k+I,H或A,k,H【解析】题目考查快速排序算法。快速排序采用了一种分治的策略,通常称为分治法。其基本思想是:将原问题分解为若干个规模更小,但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。快速排序的具体过程为:第一步,在待排序的n个记录中任取一个记录,以该记录的排序码为基准,将所有记录分成2组,第一组各记录的排序码都小于等于该排序码,第二组各记录的排序码都大于该排序码,并把该记录排在这2组中间,这个过程称为一次划分。第二步,采用同样的方法,对划分出来的2组元素分别进行快速排序,直到所有记录都排到相应的位置为止。在进行一次划分时,若选定以第一个元素为基准,就可将第一个元素备份在变量pivot中,如图中的第①步所示。这样基准元素在数组中占据的位置就空闲出来了,因此下一步就从后向前扫描。如图中的第②步所示,找到一个比基准元素小的元素时为止,将其前移,如图中的第③步所示。然后再从前向后扫描,如图中的第④步所示,找到一个比基准元素大的元素时为止,将其后移,如图中的第⑤步所示。这样,从后向前扫描和从前向后扫描交替进行,直到扫描到同一个位置为止,如图中的第⑥步所示。由题目中给出的流程图可知,以第一个元素作为基准数,并将A[low]备份至pivot,i用于从前向后扫描的位置指示器,其初值为low,j用于从后往前扫描的位置指示器,其初值为high。当i<j时进行循环:1)从后向前扫描数组A,在i<j的情况下,如果被扫描的元素A[j]>pivot,就继续向前扫描(j--);如果被扫描的元素A[i]<pivot就停止扫描,并将此元素的值赋给目前空闲着的A[i]。2)这时,再从前向后扫描,在i<j的情况下,如果被扫描的元素A[j]<pivot,就继续向后扫描(i++);如果被扫描的元素A[j]>pivot就停止扫描,并将此元素的值赋给目前空闲着的A[j]。3)这时又接第(1)步,直到i>j时退出循环。退出循环时,将pivot赋给当前的A[i](A[i]←pivot)。递归函数的目的是执行一系列调用,直到到达某一点时递归终止。为了保证递归函数正常执行,应该遵守下面的规则:1)每当一个递归函数被调用时,程序首先应该检查基本的条件是否满足,例如,某个参数的值等于0,如果是这种情形,函数应停止递归。2)每次当函数被递归调用时,传递给函数一个或多个参数,应该以某种方式变得"更简单",即这些参数应该逐渐靠近上述基本条件。例如,一个正整数在每次递归调用时会逐渐变小,以至最终其值到达0。本题中,递归函数sort(intA[],intL,intH)有3个参数,分别表示数组A及其下界和上界。根据流程图可知,这里的L相当于流程图中的i,这里的H相当于流程图中的j。因为P()返回基准数所在数组A中的下标,也就是流程图中最后的"A[i]←pivot"中的i。根据快速排序算法,在第一趟排序后找出了基准数所在数组A中的下标,然后以该基准数为界(基准数在数组中的下标为k),把数组A分成2组,分别是A[L,…,k-1]和A[k+l,…,H],最后对这2组中的元素再使用同样的方法进行快速排序。 -
第10题:
阅读以下说明和C代码,填补代码中的空缺,将解答填入答题纸的对应栏内。
[说明]
对一个整数序列进行快速排序的方法是:在待排序的整数序列中取第一个数作为基准值,然后根据基准值进行划分,从而将待排序列划分为不大于基准值者(称为左子序列)和大于基准值者(称为右子序列),然后再对左子序列和右子序列分别进行快速排序,最终得到非递减的有序序列。
函数quicksort(int a[],int n)实现了快速排序,其中,n个整数构成的待排序列保存在数组元素a[0]~a[n-1]中。
[C代码] #inclLade<stdi0.h> void quicksort(inta[], int n) { int i,j; int pivot=a[0]; //设置基准值 i=0; j=n-1; while (i<j){ while (i<1 && ______) j--; //大于基准值者保持在原位置 if (i<j) { a[i] =a[j]; i++;} while(i<j&& ______) i++; //不大于基准值者保持在原位置 if (i<1) { a[j] =a[i]; 1--;} } a[i]=pivot; //基准元素归位 if (i>1 ) ______; //递归地对左孔序列进行快速排序 if (n-i-1>1 ) ______; //递归地对右孔序列进行快速排序 } int main() { int i, arr[]={23,56,9,75,18,42,11,67}; quicksort(______); //调用quicksort对数组arr[]进行排序 for( i=0; i<sizeof(arr)/sizeof(int); i++ ) printf("%d\t",arr[i]); return 0; }答案:解析:a[j]>pivot 或 a[j]>=pivot 或等价形式
a[i]<=pivot 或 a[i]<pivot 或等价形式
quicksort(a,i) 或 quicksort(a,j) 或等价形式
quicksort(a+i+1,n-i-1) 或 quicksort(a+j+1,n-j-1) 或等价形式
注:a+i+1可表示为&a[i+1],a+j+1可表示为&a[j+1]
arrsizeof(arr)/sizeof(int)
注:sizeof(arr)/sizeof(int)可替换为8
【解析】
本题考查C程序设计基本技能及快速排序算法的实现。
题目要求在阅读理解代码说明的前提下完善代码,该题目中的主要考查点为运算逻辑和函数调用的参数处理。
程序中实现快速排序的函数为quicksort,根据该函数定义的首部,第一个参数为数组参数,其实质是指针,调用时应给出数组名或数组中某个元素的地址;第二个参数为整型参数,作用为说明数组中待排序列(或子序列)的长度。
快速排序主要通过划分来实现排序。根据说明,先设置待排序列(或子序列,存储在数组中)的第一个元素值为基准值。划分时首先从后往前扫描,即在序列后端找出比基准值小或相等的元素后将其移到前端,再从前往后扫描,即在序列前端找出比基准值大的元素后将其移动到后端,直到找出基准值在序列中的最终排序位置。再结合注释,空(1)处应填入"a[j]>pivot",使得比基准值大者保持在序列后端。空(2)处应填入"a[i]<=pivot",使得不大于基准值者保持在前端。
在完成1次划分后,基准元素被放入a[i],那么分出来的左子序列由a[0]~a[i-1]这i个元素构成,右子序列由a[i+1]~a[n-1]构成,接下来应递归地对左、右子序列进行快排。因此,结合注释,空(3)应填入"quicksort(a,i)"或其等价形式,以对左子序列的i个元素进行快排,也可以用&a[0]代替其中的a,它们是等价的,a与&a[0]都表示数组的起始地址。
空(4)所在代码实现对右子序列进行快排。右子序列由a[i+1]~a[n-1]构成,其元素个数为n-1-(i+1)+1,即n-i-1,显然元素a[i+1]的地址为&a[i+1]或a+i+1,所以空(4)应填入"quicksort(a+i+1,n-i-1)"或其等价形式。
在main函数中,空(5)所在代码首次调用函数quicksort对main函数中的数组arr进行快排,因此应填入"arr,sizeof(arr)/sizeof(int)"或其等价形式。 -
第11题:
阅读下列说明和C代码,回答下列问题。[说明]?? ?采用归并排序对n个元素进行递增排序时,首先将n个元素的数组分成各含n/2个元素的两个子数组,然后用归并排序对两个子数组进行递归排序,最后合并两个已经排序的子数组得到排序结果。?? ?下面的C代码是对上述归并算法的实现,其中的常量和变量说明如下:?? ?arr:待排序数组?? ?P,q,r:一个子数组的位置从P到q,另一个子数组的位置从q+1到r?? ?begin,end:待排序数组的起止位量?? ?left,right:临时存放待合并的两个子数组?? ?n1,n2:两个子数组的长度?? ?i,j,k:循环变量?? ?mid:临耐变量?? ?[C代码]?? ?#inciude<stdio, h>?? ?#include<stdlib, h>?? ?Define MAX 65536?? ?void merge(int arr [ ],int p,int q,int r) {?? ?int * left,* right;?? ?int n1,n2,I,j,k;?? ?n1=q-p+1;?? ?n2=r-q;?? ?If(left=(int *)malloc((n1+1) * sizeof(int)))=NULL) {?? ?Perror( "malloc error" );?? ?exit11?? ?}?? ?If((right = (int *)malloc((n2+1) * sizeof(int)))=NULL)?? ?Perror("malloc error");?? ?exit 11;?? ?}?? ?for(i=0;i<n1;i++){?? ?left[i]=arr [p+i];?? ?}?? ?left[i]=MAX;?? ?for(i=0;i<n2;i++){?? ?right[i]=arr[q+i+1]?? ?}?? ?right[i]=MAX;?? ?i=0;j=0;?? ?For(k=p;______;k++){?? ?If(left[i]>right[j] {?? ?______?? ?j++;?? ?}else{?? ?arr[k1]=left[i];?? ?i++;?? ?}?? ?}?? ?}?? ?Void merge Sort(int arr[ ], int begin, int end) {?? ?int mid;?? ?if(______){?? ?mid=(begin + end)/2;?? ?merge Sort(arr,begin,mid);?? ?______;?? ?Merge(arr,begin,mid,end);?? ?}?? ?}答案:解析:11、k<=r arr[k]=right[j] begin<end mergeSort(arr,mid+1,end)[解析] 首先,函数void merge(int arr[],int P,int q,int r)的意思是:对子数组arr[P…q]和子数组arr[q+L..r]进行合并。因此第一空为k<=q;由于是采用归并排序对n个元素进行递增排序,所以第二空是将left[i]和right[j]的小者存放到arr[k]中去,即arr[k]=right[j]:当数组长度为1时,停止递归,因为此时该数组有序,则第三空为begin<end,即数组至少有两个元素才进行递归。合并了begin到mid之间的元素,继续合并mid+1到end之间的元素,则第四空为mergeSort(arr,mid+1,end)。12、分治 T(n)=2T(n/2)+O(n) O(nlogn) O(n)[解析] 归并算法实际上就是将数组一直往下分割,直到分割到由一个元素组成的n个子数组,再往上两两归并。 将数组进行分割需要logN步,因为每次都是讲数组分割成两半(2x=N,x=logN)。 合并N个元素,需要进行N步,也就是O(N),则总的时间复杂度为O(NlogN)。 合并过程中,使用了”个中间变量存储,left=(int*)malloc((n1+1)*sizeof(int))。所以空间复杂度为O(n)。 推导递归式:假设n个元素进行归并排序需要T(n),可以将其分割成两个分别有n/2个元素的数组分别进行归并,也就是2T(n/2),在将这两个合并,需要O(n)的时间复杂度,则推导公式为T(n)=2T(n/2)+O(n)。13、n1+n2 -
第12题:
设m=ABCDEF,下列表达式不能得到DEF的是().
- A、Right$(m,3)
- B、Right$(Left$(m,6),3)
- C、Mid$(m,4)
- D、Left$(Right$(m,5),3)
正确答案:D -
第13题:
阅读下列函数说明和C代码,将应填入(n)处的字句写在对应栏内。
【说明】
函数QuickSort是在一维数组A[n]上进行快速排序的递归算法。
【函数】
void QuickSort( int A[ ],int s,int t)
{ int i=s,j=t+1,temp;
int x=A[s];
do{
do i ++ ;while (1);
do j -- ;while(A[j]>x);
if(i<j){temp=A[i];(2);(3);}
}while(i<j);
A[a] =A[j];A[j] =x;
if(s<i-1) (4);
if(j+1<t) (5);
}
正确答案:(1)A[i]x (2)A[i]=A[j] 3)A[j]=temp (4)QuickSort(Asj-1) (5)QuickSort(Aj+1t);
(1)A[i]x (2)A[i]=A[j] 3)A[j]=temp (4)QuickSort(A,s,j-1) (5)QuickSort(A,j+1,t); 解析:快速排序的思想是:任取待排序序列中的某个元素作为基准(一般取第一个元素),通过一趟排序,将待排元素分为左右两个子序列,左子序列元素的排序码均小于或等于基准元素的排序码,右子序列的排序码则大于基准元素的排序码,然后分别对两个子序列继续进行排序,直至整个序列有序。快速排序是对冒泡排序的一种改进方法,算法中元素的比较和交换是从两端向中间进行的,排序码较大的元素一次就能够交换到后面单元,排序码较小的记录一次就能够交换到前面单元,记录每次移动的距离较远,因而总的比较和移动次数较少。 -
第14题:
用SQL语句进行表的查询操作,使用 ()语句。如果要进行分组查询,应使用 ()子句;如果要对查询结果进行排序,要使用 () 子句;查询使用连接操作时,可以使用的外连接方式主要有左连接() ,右连接() ,全连接 () 等几种。
A UPDATE , ORDER BY, GROUP BY, LEFT JOIN, RIGHT JOIN, FULL JOIN
B SELECT , GROUP BY, ORDER BY, LEFT JOIN,RIGHT JOIN, FULL JOIN
C SELECT , ORDER BY , GROUP BY , LEFT JOIN, RIGHT JOIN,FULL JOIN
D SELECT ,GROUP BY , ORDER BY , RIGHT JOIN, LEFT JOIN, FULL JOIN
参考答案B
-
第15题:
阅读以下说明和C语言函数,将应填入(n)处的语句写在对应栏内。
【说明】
本程序从正文文件text.in中读入一篇英文短文,统计该短文中不同单词及出现次数,并按词典编辑顺序将单词及出现次数输出到正文文件word.out中。
程序用一棵有序二叉树存储这些单词及其出现的次数,边读入边建立,然后中序遍历该二叉树,将遍历经过的二叉树上的结点内容输出。
【函数】
include <stdio.h>
include <malloc.h>
include <ctype.h>
include <string.h>
define INF "text.in"
define OUTF "word.our'
typedef struct treenode {
char *word;
int count;
struct treenode *left, *right;
} BNODE;
int getword(FILE *fpt, char *word)
{ char c;
c=fgetc(tpt);
if (c==EOF)
return 0;
while(!(tolower(c)>= 'a' && tolower(c)<= 'z'))
{ c=fgetc(fpt);
if (c==EOF)
return 0;
} /* 跳过单词间的所有非字母字符 */
while(tolower(c)>= 'a' && tolower(c)<= 'z')
{ *word++=c;
c=fgetc(fpt);
}
*word='\0';
return 1;
}
void binary_tree(BNODE **t, char *word)
{ BNODE *ptr, *p; int compres;
p=NULL;
(1);
while (ptr) /* 寻找插入位置 */
{ compres=strcmp(word, ptr->word);/* 保存当前比较结果 */
if (!compres)
{ (2); return;}
else
{ p=ptr;
ptr=compres>0 ? ptr->right: ptr->left;
}
}
ptr=(BNODE *)malloc(sizeof(BNODE));
ptr->left=ptr->right=NULL;
ptr->word=(char *)malloc(strlen(word)+1);
strcpy(ptr->word, word);
(3);
if (p==NULL)
*t=ptr;
else if (compres>0)
p->right=ptr;
else
p->left=ptr;
}
void midorder(FILE *fpt, BNODE *t)
{ if (t==NULL)
return;
midorder(fpt,(4));
fprintf(fpt, "%s %d\n", t->word, t->count);
midorder(fpt, t->right);
}
void main()
{ FILE *fpt; char word[40];
BNODE *root=NULL;
if ((fpt=fopen(INF, "r"))==NULL)
{ printf("Can't open file %s\n", INF);
return;
}
while(getword(fpt, word)==1)
binary_tree((5));
fclose(fpt);
fpt=fopen(OUTF, "w");
if (fpt==NULL)
{ printf("Can't open fife %s\n", OUTF);
return;
}
midorder(fpt, root);
fclose(fpt);
}
正确答案:(1)ptr=*t (2)ptr->count++ (3)ptr->count=1 (4)t->left (5)&rootword
(1)ptr=*t (2)ptr->count++ (3)ptr->count=1 (4)t->left (5)&root,word 解析:本题考查在C语言中实现字母的统计和有序二叉树的建立及遍历。
题目要求统计一篇英文短文中不同单词及出现次数,并将这些单词及其出现的次数用一棵有序二叉树存储,然后中序遍历该二叉树,将遍历经过的二叉树上的结点的内容输出。内容的输出是按词典编辑顺序将单词及出现次数输出的,因此二叉树的排序是按单词在词典中编辑顺序进行的,并且有序二叉树是动态生成的。
本题目的关键是有序二叉树是动态生成的,我们先来看其生成的步骤:
(1)如果相同键值的结点已在二叉排序中,则不再插入,只需修改其count的值即可;
(2)如果二叉排序树为空树,则以新结点为根建立二叉排序树;
(3)根据要插入结点的键值与插入后父结点的键值比较,就能确定新结点是父结点的左子结点,还是右子结点,并作相应插入。
重复这几步,直到单词统计结束。
下面我们来分析代码。函数getword()已经完全实现了,用来统计短文中的单词,并返回1,说明此单词出现了一次。函数binary_tree()是用来生成有序二叉树的。函数 midorder()用来实现中序遍历。
第(1)空在函数binary_tree()中,结合程序不难看出,此空应该是赋初值,而且是给指针变量ptr赋值。函数binary_tree()的形参中有一个指针变量*t,用来传递待插入到有序二叉树中的结点地址,在这里是让指针变量ptr指向这个地址,因此答案为ptr=*t。
第(2)空在条件判断语句if(!compres)下,而compres存放的是上步的比较结果值,如果条件判断语句结果为真,说明word与ptr->word的值相等,即树中已经存在该字母结点,根据有序二叉树的生成步骤知道,不需要再插入,只需修改其count的值即可,因此,第(2)空答案为ptr->count++。
第(3)空在动态生成了新结点后面。生成了一个新结点后,自然要对新结点的几个域值进行赋初值,程序中对指针域都赋了空,对字符指针域也赋了值,剩下的只有count值没有被修改,那么此空应该是用来修改count的值。在一个字母对应的结点刚插入树中时,它肯定是第一次出现,因此,此空答案为ptr->count=1。
第(4)空在函数midorder()中,此函数的功能是实现对有序二叉树的中序遍历。它是用递归方法来实现的,如果树不为空,应该先对其左子树进行递归遍历,然后才是右子树,因此,第(4)空答案为t->left。
第(5)空是当主函数调用函数binary_tree()时,需要传递的参数。根据binary_tree()的定义,我们知道它的第一个参数是指向有序二叉树的二重指针,而第二个参数是指向当前需要处理的字母的指针。在主函数中,表明有序二叉树是一重指针root,而存放当前需要处理字母的是word数组。在一重指针与二重指针进行参数传递时,需要注意加取地址运算符“&”,因此,此空答案为&root,word。 -
第16题:
阅读下列程序说明和C程序,将应填入程序中(n)处的字句,写在对应栏内。
【程序说明】
本程序先从文件读人各考生的准考证号(设为整型数)及成绩,并将其存放在一棵检索二叉树上,二叉树结点的健值是成绩,每个结点带一链表,链表结点存放取得该成绩的考生的准考证号。然后,程序按中序遍历检索二叉树,从高分到低分输出结果,使每行输出成绩及其取得成绩的考生的准考证号。
【程序】
include < stdio. h >
typedef struet idnode {
int id;
struct idnode * next;
} ldNode;
typedef struct marknode I
int mark;
ldNode * head;
struct marknode * left, * right;
} MarkNode;
char fname [ ] = "sp07.dat";
main( )
{ int id, mark;
MarkNode * root = null;
FILE * fp = fopen(fname," r" );
if(!fp) {
printf("file%s open error, \n" , fname);
exit(0);
}
while (!feop(fp)) {
fscanf(fp," %d%d", &id, &mark);
btree(&root, id, mark);
}
fclose(fp);
print(root);
}
btree(MarkNod * * mpptr, int id, int mark)
{ ldNode * ip;
MarkNode *mp = * mpptr;
if (1) {
if (mark==p->mark) addldNODE ((2), id);
else if ( mark >mp -> mark) btree (&top -> left, id, mark);
else btree(&mp-> right, id, mark);
} else
Imp = ( marknode * ) malloc(sizeo (marknode) );
mp -> mark = mark;
mp -> left =mp -> right = NULL;
(3)
addldNode(&mp -> head, id);
(4);
}
}
addldNode(ldNode * * ipp, int id)
{ ldNode * ip = * ipp;
if ((5))addldNode ((6)), id;
else {
ip = (ldNode * )malloc(sizeof(ldNode) );
sp - > id = id;
ip -> next = NULL;
(7)
}
}
print(MarkNode * rap)
{ ldNode *ip, *ip0;
if (mp) {
print ( mp -> left);
printf(" %6d: \t" ,mp -> mark);
ip = mp -> head;
while(ip) {
printf(" %6d" ,ip -> id);
ip0 =ip;
ip = ip -> next;
free (ip0);
}
printf(" \n" ); printf( mp -> right); free(mp);
}
}
正确答案:(1)mp或mp!=NULL(2)mp->head或&(mp->head) (3)&mp->head=NULL(4)*mpptr=mp(5)ip或ip!=NULL (6)&ip->next或&(ip->next)(7)*ipp=ip
(1)mp或mp!=NULL(2)mp->head或&(mp->head) (3)&mp->head=NULL(4)*mpptr=mp(5)ip或ip!=NULL (6)&ip->next或&(ip->next)(7)*ipp=ip -
第17题:
阅读下列说明、流程图和算法,将应填入(n)处的字句写在对应栏内。
【流程图说明】
下图所示的流程图5.3用N-S盒图形式描述了数组Array中的元素被划分的过程。其划分方法;以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于Array[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。

【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int Array[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组Ar ray中的下标。递归函数void sort(int Array[],int L,int H)的功能是实现数组Array中元素的递增排序。
【算法】
void sort(int Array[],int L,int H){
if (L<H) {
k=p(Array,L,H);/*p()返回基准数在数组Array中的下标*/
sort((4));/*小于基准数的元素排序*/
sort((5));/*大于基准数的元素排序*/
}
}
正确答案:(1)j←j-1
(1)j←j-1 -
第18题:
阅读下列C程序和程序说明,将应填入(n)处的字句写在对应栏内。
【说明】本程序从正文文件text.in中读入一篇英文短文,统计该短文中不同单词及出现次数,并按词典编辑顺序将单词及出现次数输出到正文文件word.out中。
程序用一棵有序二叉树存储这些单词及其出现的次数,边读入边建立,然后中序遍历该二叉树,将遍历经过的二叉树上的结点的内容输出。
include <stdio.h>
include <malloc.h>
include <ctype.h>
include <string.h>
define INF "text.in"
define OUTF "wotd.out"
typedef struct treenode{
char *word;
int count;
struct treenode *left,*right;
}BNODE
int getword (FILE *fpt,char *word)
{ char c;
c=fgetc (fpt);
if ( c=EOF)
return 0;
while(!(tolower(c)>='a' && tolower(c)<='z'))
{ c=fgetc (fpt);
if ( c==EOF)
return 0;
} /*跳过单词间的所有非字母字符*/
while (tolower (c)>='a' && tolower (c)<='z')
{ *word++=c;
c=fgetc (fpt);
}
*word='\0';
return 1;
}
void binary_tree(BNODE **t,char *word)
{ BNODE *ptr,*p;int compres;
P=NULL; (1);
while (ptr) /*寻找插入位置*/
{ compres=strcmp (word, (2) );/*保存当前比较结果*/
if (!compres)
{ (3);return;}
else
{ (4);
ptr=compres>0? ptr->right:ptr->left;
}
}
ptr= (BNODE*) malloc (sizeof (BNODE)) ;
ptr->left = ptr->right = NULL;
ptr->word= (char*) malloc (strlen (word) +1) ;
strcpy (ptr->word, word);
ptr->count - 1;
if (p==NULL)
(5);
else if (compres > 0)
p->right = ptr;
else
p->left = ptr;
}
void midorder (FILE **fpt, BNODE *t)
{ if (t==NULL)
return;
midorder (fpt, t->left);
fprintf (fpt, "%s %d\n", t->word, t->count)
midorder (fpt, t->right);
}
void main()
{ FILE *fpt; char word[40];
BNODE *root=NULL;
if ((fpt=fopen (INF,"r")) ==NULL)
{ printf ("Can't open file %s\n", INF )
return;
}
while (getword (fpt, word) ==1 )
binary_tree (&root, word );
fclose (fpt);
fpt = fopen (OUTF, "w");
if (fpt==NULL)
{ printf ("Can't open file %s\n", OUTF)
return;
}
midorder (fpt, root);
fclose(fpt);
}
正确答案:(1)ptr=*t (2)ptr->word或 (*ptr).word 或ptr[0].word (3)ptr->count++ (4)p=ptr (5)*t=ptr
(1)ptr=*t (2)ptr->word或 (*ptr).word 或ptr[0].word (3)ptr->count++ (4)p=ptr (5)*t=ptr 解析:(1)ptr=*t
本处填空是函数binary_tree的开始处,进行初始化,应该是让指针ptr指向树的根结点*t。因此应该填入:ptr=*t。
(2)ptr->word或(*ptr).word或ptr[0].word
本处填空是将要插入的单词word与当前指针ptr所指的结点的word比较大小。
(3)ptr->count++
本处填空是当要插入的单词word与指针ptr所指的结点的word相同时的处理,必然是将指针ptr所指结点的计数器count加1。因此应该填入:ptr->count++。
(4)p=ptr
本处填空是当要插入的单词word与指针ptr所指结点的word不相同时的处理,必然是让p指向ptr,而ptr指向其左子树或右子树。因此应该填入:p=ptr。
(5)*t=ptr
本处填空是当p为空时的处理,应该是让树的根结点指针指向ptr以便返回。 -
第19题:
阅读以下说明和 C 代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 对一个整数序列进行快速排序的方法是:在待排序的整数序列中取第一个数作为基准值,然后根据基准值进行划分,从而将待排序列划分为不大于基准值者(称为左子序列)和大于基准值者(称为右子序列),然后再对左子序列和右子序列分别进行快速排序, 最终得到非递减的有序序列。 函数 quicksort(int a[],int n)实现了快速排序,其中,n 个整数构成的待排序列保存在数组元素 a[0]-a[n-1]中。
【C 代码】 include < stdio.h> void quicksort(int a[] ,int n) { int i ,j; int pivot = a[0]; //设置基准值 i =0; j = n-l; while (i< j) { while (i<j &&(1)) j-- //大于基准值者保持在原位置 if (i<j) { a[i]=a[j]; i++;} while (i,j &&(2)) i++; //不大于基准值者保持在原位置 if (i<j) { a[j]=a[i]; j--;} } a[i] = pivot; //基准元素归位 if ( i>1) (3) ; //递归地对左子序列进行快速排序 if ( n-i-1>1 ) (4) ; //递归地对右子序列进行快速排序 } int main () { int i,arr[ ] = {23,56,9,75,18,42,11,67}; quicksort ( (5) ); //调用 quicksort 对数组 arr[ ]进行排序 for( i=0; i<sizeof(arr) /sizeof(int); i++ ) printf(" %d\t" ,arr[i]) ; return 0; }
正确答案:
(1) a[j]> pivot 或 a[j]>= pivot 或等价形式
(2) a[i] <= pivot 或 a[i] < pivot 或等价形式
(3) quicksort(a ,i) 或 quicksort(a,j) 或等价形式
(4) quicksort(a+i+1,n-i-1) 或 quicksort(a+j+1,n-j -1) 或等价形式
注: a+i+1可表示为 &a[i+1] ,a+j+1可表示为 &a[j+1]
(5) arr,sizeof(arr)/sizeof(int)
注: sizeof(arr)/sizeoftint) 可替换为 8
-
第20题:
●试题一
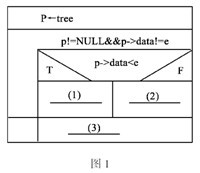
阅读下列说明和流程图,将应填入(n)的语句写在答题纸的对应栏内。
【流程图说明】
下面的流程(如图1所示)用N-S盒图形式描述了在一棵二叉树排序中查找元素的过程,节点有3个成员:data,left和right。其查找的方法是:首先与树的根节点的元素值进行比较:若相等则找到,返回此结点的地址;若要查找的元素小于根节点的元素值,则指针指向此结点的左子树,继续查找;若要查找的元素大于根节点的元素值,则指针指向此结点的右子树,继续查找。直到指针为空,表示此树中不存在所要查找的元素。
【算法说明】
【流程图】
将上题的排序二叉树中查找元素的过程用递归的方法实现。其中NODE是自定义类型:
typedef struct node{
int data;
struct node*left;
struct node*right;
}NODE;
【算法】
NODE*SearchSortTree(NODE*tree,int e)
{
if(tree!=NULL)
{
if(tree->data<e)
(4) ;∥小于查找左子树
else if(tree->data<e)
(5) ;∥大于查找左子树
else return tree;
}
return tree;
}
正确答案:
●试题一【答案】(1)p=p->left(2)ptr=p->right(3)returnP(4)returnSearchSortTree(tree->left)(5)returnSearchSortTree(tree->right)【解析】所谓二叉排序树,指的是一棵为空的二叉树,或者是一棵具有如下特性的非空二叉树:①若它的左子树非空,则左子树上所有结点的值均小于根结点的值。②若它的右子树非空,则右子树上所有结点的值均大于根结点的值。③左、右子树本身又各是一棵二叉排序树。先来分析流程图。在流程图中只使用一个变量p,并作为循环变量来控制循环,所以循环体中必须修改这个值。当进入循环时,首先判断p是不是为空和该结点是不是要找的结点,如果这两个条件有一个满足就退出循环,返回prt,(如果是空,则返回NULL,说明查询失败;否则返回键值所在结点的指针。)因此(3)空处应当填写"returnp"。如果两个条件都不满足,就用查找键值e与当前结点的关键字进行比较,小的话,将指针p指向左子树继续查找,大的话将指针p指向右子树继续查找。于是,(1)空处应当填写"p=p->left",(2)空处应当填写"p=p->right"。再来分析程序。虽然是递归算法,但实现思路和非递归是一样。首先用查找键值e与树根结点的关键字比较,如果值小的话,就在左子树中查找(即返回在左子树中查找结果);如果值大的话在右子树中查找(即返回在右子树中查找结果);如果相等的话就返回树根指针。因此(4)、(5)空分别应填写"returnSearchSortTree(tree->left)"和"returnSearchSortTree(tree->right)"。 -
第21题:
阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】下面的程序利用快速排序中划分的思想在整数序列中找出第 k 小的元素(即 将元素从小到大排序后,取第 k 个元素)。对一个整数序列进行快速排序的方法是:在待排序的整数序列中取第一个数 作为基准值,然后根据基准值进行划分,从而将待排序的序列划分为不大于基准 值者(称为左子序列)和大于基准值者(称为右子序列),然后再对左子序列和 右子序列分别进行快速排序,最终得到非递减的有序序列。例如,整数序列“19, 12, 30, 11,7,53, 78, 25"的第 3 小元素为 12。整数序列“19, 12,7,30, 11, 11,7,53. 78, 25, 7"的第 3 小元素为 7。函数 partition(int a[], int low,int high)以 a[low]的值为基准,对 a[low]、 a[low+l]、…、a[high]进行划分,最后将该基准值放入 a[i] (low≤i≤high),并 使得 a[low]、a[low+l]、,..、A[i-1]都小于或等于 a[i],而 a[i+l]、a[i+2]、..、 a[high]都大于 a[i]。函 教 findkthElem(int a[],int startIdx,int endIdx,inr k) 在 a[startIdx] 、 a[startIdx+1]、...、a[endIdx]中找出第 k 小的元素。【代码】#include#include
Int partition(int a [],int low, int high){//对 a[low..high]进行划分,使得 a[low..i]中的元素都不大于 a[i+1..high]中的 元素。int pivot=a[low]; //pivot 表示基准元素 Int i=low,j=high;while(( 1) ){While(i答案:解析:1) CountStr
2) p[i]
3) p[i]
4) num 3、
1、!i=j
2、a[i]=pivot
3、a[loc]
4、stratIdx,Loc-1
5、Loc+1,endIdx -
第22题:
设指针变量p指向双向链表中节点A,指针变量s指向被插入的节点X,则在节点A的后面插入节点X的操作序列为()A.p->right=s;s->left=p;p->right->left=s;s->right=p->right;
B.p->right=s;p->right->left=s;s->left=p;s->right=p->right;
C.s->left=p;s->right=p->right;p->right=s;p->right->left=s;
D.s->left=p;s->right=p->right;p->right->left=s;p->right=s;答案:D解析:为了防止在插入节点时链表断裂,在修改指针时,需要先使s的后继指针指向p原来的后继节点,然后修改p的后继指针。 -
第23题:
下面这段代码中,变量subString的结果是()。 Dim aString As String = "Left Center Right" Dim subString As String subString = Mid(aString, 13)
- A、"_Right"
- B、"Right_"
- C、"Right"
- D、"Left Center_"
- E、"Left Center"
- F、"_Left Center_"
- G、"Left Center R"
正确答案:C