
12、对于随机缺失情况下的缺失值填充,以下说法不正确的是A.缺失值填充是一种加分手段,可以修复缺失的信息。B.可以指定用众数填充缺失值C.可以指定用均值填充缺失值D.可以用邻近值填充缺失值
题目
12、对于随机缺失情况下的缺失值填充,以下说法不正确的是
A.缺失值填充是一种加分手段,可以修复缺失的信息。
B.可以指定用众数填充缺失值
C.可以指定用均值填充缺失值
D.可以用邻近值填充缺失值
相似考题
更多“12、对于随机缺失情况下的缺失值填充,以下说法不正确的是”相关问题
-
第1题:
对于脱落/缺失数据的应对,以下说法错误的是()。A、在方案或者SAP中提前考虑缺失数据的处理
B、医学监查,数据审核,统计师参与判断受试者,能否进入最终的分析集
C、在统计分析时候,根据缺失数据的缺失机制,考虑数据的填补规则
D、基于原方案的设计,揭盲后评价追加样本量
答案:C
-
第2题:
缺失值处理的方法有( )。
A. 就近插值
B. 删除对应记录
C. 随机插值
D.分类插值
参考答案ABCD
-
第3题:
在余留牙条件正常的情况下,设计双端固定桥,下列哪一种选择是不正确的A.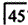 缺失,
缺失, 为基牙
为基牙
B. 缺失,
缺失,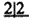 为基牙
为基牙
C.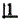 缺失,
缺失,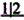 为基牙
为基牙
D. 缺失,
缺失, 为基牙
为基牙
E.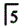 缺失,
缺失, 为基牙答案:B解析:
为基牙答案:B解析: -
第4题:
A.下颌63|78缺失
B.下颌21|12缺失
C.上颌651|456缺失
D.下颌8763|678缺失属于Kennedy第四类的是答案:B解析: -
第5题:
在余留牙条件正常的情况下,设计双端固定桥,下列哪一种选择是不正确的A.上颌 缺失,
缺失,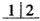 为基牙
为基牙
B.上颌 缺失,
缺失,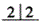 为基牙
为基牙
C.上颌 缺失,
缺失, 为基牙
为基牙
D.下颌 缺失,
缺失,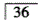 为基牙
为基牙
E.下颌 缺失,
缺失,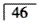 为基牙答案:B解析:
为基牙答案:B解析: -
第6题:
在对回收后的调查问卷进行数据处理时,处理缺失值的办法主要是()。
- A、用一个样本统计量的值代替缺失值
- B、用从一个统计模型计算出来的值去代替缺失值
- C、将有缺失值的个案删除
- D、将有缺失值的个案保留,仅在相应的分析中做必要的删除
正确答案:A,B,C,D -
第7题:
缺失值的处理方法有哪些?()
- A、用平均值填充
- B、忽略缺失记录
- C、以任意数据填充
- D、用默认值填充
正确答案:A,B,D -
第8题:
在余留牙条件正常的情况下,设计双端固定桥,下列哪一种选择是不正确的()
- A、上颌21缺失,11,22为基牙
- B、上颌11,21缺失,12,22为基牙
- C、上颌26缺失,25,27为基牙
- D、下颌34,35缺失,33,36为基牙
- E、下颌34缺失,33,35为基牙
正确答案:B -
第9题:
单选题当一个连续变量的缺失值占比在85%左右时,以下哪种方式最合理()A直接使用该变量
B根据是否缺失,生成指示变量,仅使用指示变量作为解释变量
C使用多重插补的方法进行缺失值填补
D直接删除该变量
正确答案: A解析: 暂无解析 -
第10题:
多选题缺失值的处理方法有哪些?()A用平均值填充
B忽略缺失记录
C以任意数据填充
D用默认值填充
正确答案: B,C解析: 暂无解析 -
第11题:
单选题在余留牙条件正常的情况下,设计双端固定桥,下列哪一种选择是不正确的?( )A上颌/1缺失,1/2为基牙
B上颌1/1缺失,2/2为基牙
C上颌/6缺失,/57为基牙
D下颌/45缺失,/36为基牙
E下颌/4缺失,/35为基牙
正确答案: C解析: 暂无解析 -
第12题:
多选题在对回收后的调查问卷进行数据处理时,处理缺失值的办法主要是()。A用一个样本统计量的值代替缺失值
B用从一个统计模型计算出来的值去代替缺失值
C将有缺失值的个案删除
D将有缺失值的个案保留,仅在相应的分析中做必要的删除
正确答案: B,A解析: 暂无解析 -
第13题:
处理缺失值的方法有()。A.人工添加方法
B.用样本统计量的值去代替缺失值
C.只排除有缺失值的项目问题,但保留个案
D.将有缺失值的个案整个删除
E.用统计模型估计值去代替缺失值
参考答案:DE
-
第14题:
在余留牙条件正常的情况下,设计双端固定桥,下列哪一种选择是不正确的( )A.上颌21缺失,11,22为基牙
B.上颌11,21缺失,12,22为基牙
C.上颌26缺失,25,27为基牙
D.下颌34,35缺失,33,36为基牙
E.下颌34缺失,33,35为基牙答案:B解析: -
第15题:
A.下颌63|78缺失
B.下颌21|12缺失
C.上颌651|456缺失
D.下颌8763|678缺失属于Kennedy第二类二亚类的是答案:A解析: -
第16题:
在以下五副活动义齿模型中,需用蜡确定上下颌模型的颌位关系的是A.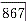 缺失
缺失
B.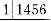 缺失
缺失
C.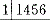 和
和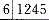 缺失
缺失
D.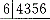 缺失
缺失
E. 缺失答案:A解析:游离端缺失义齿,需要确定颌位关系。
缺失答案:A解析:游离端缺失义齿,需要确定颌位关系。 -
第17题:
以下属于数据预处理的是()
- A、缺失值填充
- B、噪声数据剔除
- C、异常值识别
- D、数据可视化
正确答案:A,B,C -
第18题:
按Kennedy分类法;上颌8721 12678缺失为();上颌8721 12缺失为();上颌62 1245缺失为();右上1缺失为();上颌8764 124缺失为();上颌45 4578缺失为();上颌54321 126缺失为()。
正确答案:第一类第一亚类;第二类第一亚类;第三类第二亚类;第四类;第二类第三亚类;第二类第二亚类;第三类第一亚类 -
第19题:
当一个连续变量的缺失值占比在85%左右时,以下哪种方式最合理()
- A、直接使用该变量
- B、根据是否缺失,生成指示变量,仅使用指示变量作为解释变量
- C、使用多重插补的方法进行缺失值填补
- D、直接删除该变量
正确答案:B -
第20题:
以下可以设计单端固定桥的是()
- A、上颌中切牙缺失
- B、上颌尖牙缺失
- C、第二、三磨牙缺失
- D、上颌侧切牙缺失,缺牙间隙小
- E、间隔缺失
正确答案:D -
第21题:
多选题以下属于数据预处理的是()A缺失值填充
B噪声数据剔除
C异常值识别
D数据可视化
正确答案: B,C解析: 暂无解析 -
第22题:
单选题在余留牙条件正常的情况下,设计双端固定桥,下列哪一种选择是不正确的()A上颌21缺失,11,22为基牙
B上颌11,21缺失,12,22为基牙
C上颌26缺失,25,27为基牙
D下颌34,35缺失,33,36为基牙
E下颌34缺失,33,35为基牙
正确答案: C解析: 暂无解析 -
第23题:
多选题以下有关随机森林算法的说法正确的是()A随机森林算法的分类精度不会随着决策树数量的增加而提高
B随机森林算法对异常值和缺失值不敏感
C随机森林算法不需要考虑过拟合问题
D决策树之间相关系数越低、每棵决策树分类精度越高的随机森林模型的分类效果越好
正确答案: A,D解析: 暂无解析 -
第24题:
填空题按Kennedy分类法;上颌8721 12678缺失为();上颌8721 12缺失为();上颌62 1245缺失为();右上1缺失为();上颌8764 124缺失为();上颌45 4578缺失为();上颌54321 126缺失为()。正确答案: 第一类第一亚类,第二类第一亚类,第三类第二亚类,第四类,第二类第三亚类,第二类第二亚类,第三类第一亚类解析: 暂无解析