
阅读下列说明和流程图,将应填入(n)处。[流程图说明]流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符之间的空白。例如,原字符串“ File Name ”,处理后变成“File Name”。流程图1-2、流程图1-3、流程图1-4分别详细描述了流程图1-1中的框A,B,C。假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1),ch(2),…,ch(n)中,字符常量KB表示空白字符。流程图1-1的处理过程是:先从头开始找出该字符串中的第一个非空白
题目
阅读下列说明和流程图,将应填入(n)处。
[流程图说明]
流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符之间的空白。例如,原字符串“ File Name ”,处理后变成“File Name”。流程图1-2、流程图1-3、流程图1-4分别详细描述了流程图1-1中的框A,B,C。
假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1),ch(2),…,ch(n)中,字符常量KB表示空白字符。
流程图1-1的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i),…,ch(j)依次送入 ch(1),ch(2),…中。如果原字符串中没有字符或全是空白字符,则输出相应的说明。在流程图中,strlen是取字符串长度函数。

[问题]在流程图1-1中,判断框P中的条件可表示为:
i>(5)
相似考题
更多“ 阅读下列说明和流程图,将应填入(n)处。[流程图说明]流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符之间的空白。例如,原字符串“ File Name ”,处理后”相关问题
-
第1题:
阅读以下说明,回答问题,将解答填入对应的解答栏内。
. [说明] 请完成流程图以描述在数据A(1)至A(10)中求最大数和次大数的程序的算法。并将此改成PAD图。该算法的流程图如下图:
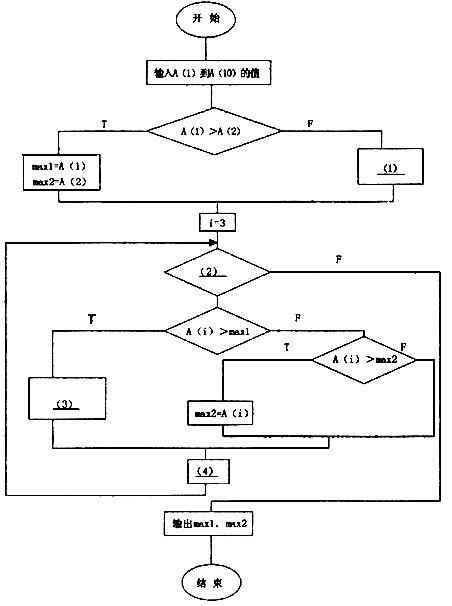 正确答案:(1)max2 =A(1) mex1 =A(2) (2)i< =10 (3)max1 =A(i)1 max2 = max1 (4)i=i+1
正确答案:(1)max2 =A(1) mex1 =A(2) (2)i< =10 (3)max1 =A(i)1 max2 = max1 (4)i=i+1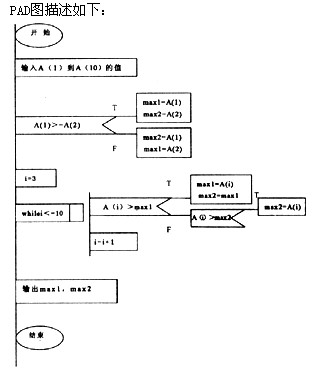
(1)max2 =A(1) mex1 =A(2) (2)i< =10 (3)max1 =A(i)1 max2 = max1 (4)i=i+1 解析:本题的算法思想是:先输入A(1)到A(10)的值,然后判断前两个数的大小。用变量max1存储最大数,用变量max2.存储次大数。然后逐个读入数据,分别和max1,max2比较,保证最大的存入max1,次大的存入max2。
-
第2题:
试题一(共15 分 )
阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。
【 说明 】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B 的下标,k为指定关键词出现的次数。
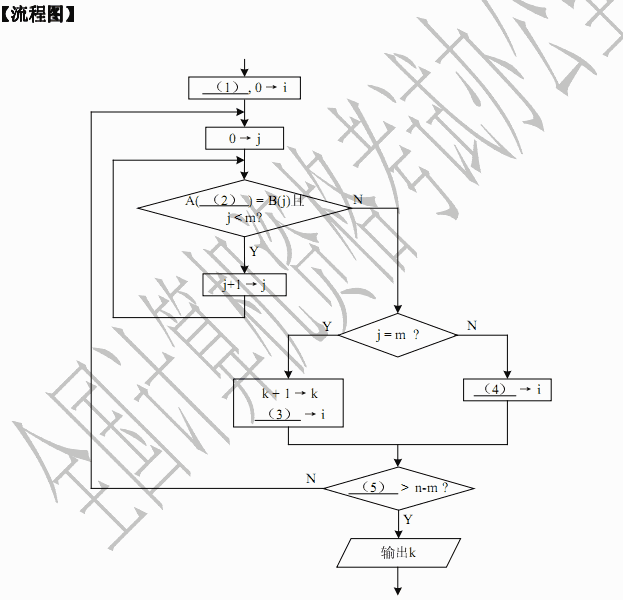 正确答案:
正确答案:
试题一参考答案(15分)注意:此题解答中的字母不区分大小写1,0→k,或k←0,或k=0,或等价形式3分2,i+j,或等价形式3分3,i+m或i+j,或等价形式3分4,i+1,或等价形式3分5,i3分 -
第3题:
阅读以下说明和流程图,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在"aaaa"中只出现两次"aa"。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
【流程图】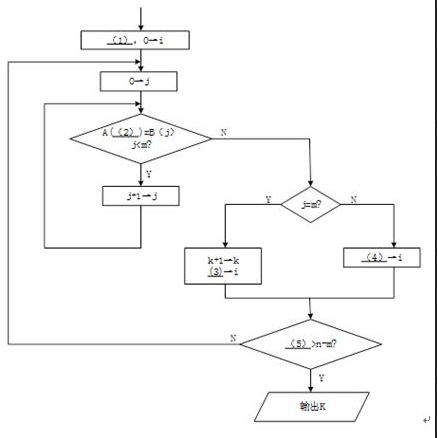 答案:解析:
答案:解析: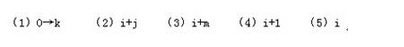
【解析】
本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果 k就是文章字符串 A中出现关键词字符串 B的次数。显然,流程图开始时应将 k赋值 0,以后每找到一处出现该关键词,就执行增1操作 k=k+1。因此(1)处应填0→k。
字符串 A和 B的下标都是从 0开始的。所以在流程图执行的开始处,需要给它们赋值 0。接下来执行的第一个小循环就是判断 A(i),A(i+1),…,A(i+j一1)是否完全等于 B(0),B(1),…,B(m一1),其循环变量j=0,l ,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是 A(i+j)=B(j)且j许多考生在(2)处填 i,当j 增 1 变化后,仍然使用 A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在 j=0,1 ,…,m-1 时全都成立 A(i+j)=B(j)(找到了一处关键词),直到j=m 时才结束小循环;二是在 j对于 j=m,己找到一处关键词的情况,显然应该执行 k=k+1,对关键词出现次数的变量 k进行增 1计算。同时,为了继续进行以后的判断,应将字符串 A 的下标 i右移 m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写 i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的 j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就 使关键词的出现有可能发生部分重叠的现象。
流程图中,对于 j在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对 A(n-m),A(n-m+1),… ,A(n一1)的判断。下标 n-m来自从 n-1 倒数 m个数。可以先试验写出A(n-m),A(n-m+1),… ,A(n一1),再判断其个数是否为m。经检查,个数为 (n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。 既然最后一次判断关键词应该是对A(n-m),A(n-m+1),… ,A(n一1)的判断,即对 i=n-m进行的小循环判断,所以当 i>n-m 时就应该停止大循环,停止再查找关键词了。 -
第4题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
[说明]
下面的流程图用于计算一个英文句子中最长单词的长度(即单词中字母个数)MAX。假设该英文句子中只含字母、空格和句点“.”,其中句点表示结尾,空格之间连续的字母串称为单词。
[流程图]
 正确答案:(1)MAX←0 (2)←L+1 (3)MAX←L (4)≠ (5)L←0
正确答案:(1)MAX←0 (2)←L+1 (3)MAX←L (4)≠ (5)L←0
(1)MAX←0 (2)←L+1 (3)MAX←L (4)≠ (5)L←0 解析:本题用到的三个变量及其作用分别为:A,存放输入的一个字符;MAX,存放当前为止最长单词的长度;L,存放当前单同的长度。
(1)使用变量MAX应先赋予初值,由上下文知其初值为0;
(2)读取当前单词时,每读人一个字母,单词长度值L应增1;
(3)当前单词长度L比MAX时,应更新MAX的值;
(4)若当前字符不是句点,应当继续读取字符;
(5)读取下一个单词前,应当重置L的值。 -
第5题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
下面流程图的功能是:在给定的两个字符串中查找最长的公共子串,输出该公共子串的长度L及其在各字符串中的起始位置(L=0时不存在公共字串)。例如,字符串"The light is not bright tonight"与"Tonight the light is not bright"的最长公共子串为"he light is not bright",长度为22,起始位置分别为2和10。
设A[1:M]表示由M个字符A[1],A[2],…,A[M]依次组成的字符串;B[1:N]表示由N个字符B[1],B[2],…,B[N]依次组成的字符串,M≥N≥1。
本流程图采用的算法是:从最大可能的公共子串长度值开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串,即在A、B字符串中分别顺序取出长度为L的子串后,调用过程判断两个长度为L的指定字符串是否完全相同(该过程的流程略)。
[流程图]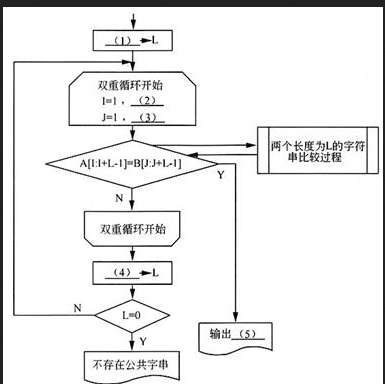 答案:解析:N或rnin(M,N)
答案:解析:N或rnin(M,N)
M-L+1
N-L+1
L-1
L,I,J
【解析】
本题考查对算法流程图的理解和绘制能力。这是程序员必须具有的技能。
本题的算法可用来检查某论文是否有大段抄袭了另一论文。"The light is not bright tonight"是著名的英语绕口令,它与"Tonight the light is not bright"大同小异。
由于字符串A和B的长度分别为M和N,而且M≥N≥1,所以它们的公共子串长度L必然小于或等于N。题中采用的算法是,从最大可能的公共子串长度值L开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串。因此,初始时,应将min(M,N)送L,或直接将N送L。(1)处应填写N或min(M,N),或其他等价形式。
对每个可能的L值,为查看A、B串中是否存在长度为L的公共子串,显然需要执行双重循环。A串中,长度为L的子串起始下标可以从l开始直到M-L+1(可以用实例来检查其正确性);B串中,长度为L的子串起始下标可以从1开始直到N-L+1。因此双重循环的始值和终值就可以这样确定,即(2)处应填M-L+1,或等价形式;(3)处应填N-L+1或等价形式(注意循环的终值应是最右端子串的下标起始值)。
A串中从下标I开始长度为L的子串可以描述为A[I:I+L-1];B串中从下标J开始长度为L的子串可以描述为A[J:J+L-1]。因此,双重循环体内,需要比较这两个子串(题中采用调用专门的函数过程或子程序来实现)。
如果这两个子串比较的结果相同,那么就已经发现了A、B串中最大长度为L的公共子串,此时,应该输出公共子串的长度值L、在A串中的起始下标I、在B串中的起始下标J。因此,(5)处应填L,I,J(可不计顺序)。
如果这两个子串比较的结果不匹配,那么就需要继续执行循环。如果直到循环结束仍然没有发现匹配子串时,就需要将L减少1((4)处填L-1或其等价形式)。只要L非0,则还可以继续对新的L值执行双重循环。如果直到L=0,仍没有发现子串匹配,则表示A、B两串没有公共子串。