
在对某商场的顾客进行流失预测分析时,先取得一个顾客样本集S,其模式为(id,a1,a2,…,an,c),其中id为顾客的唯一标识,ai(i=1,2,…,n)为顾客的属性,如年龄、性别、消费时间间隔等,c的取值为{流失,未流失}。现有算法A对样本S进行处理,输出结果为P,P能根据该样本集外的顾客u的n个属性,确定u的c属性值,以对顾客的流失作出预测。那么,A和P分别是( )。A.聚类算法,聚类工具B.分类算法,分类器C.关联规则算法,规则集D.多维分析算法,OLAP工具
题目
在对某商场的顾客进行流失预测分析时,先取得一个顾客样本集S,其模式为(id,a1,a2,…,an,c),其中id为顾客的唯一标识,ai(i=1,2,…,n)为顾客的属性,如年龄、性别、消费时间间隔等,c的取值为{流失,未流失}。现有算法A对样本S进行处理,输出结果为P,P能根据该样本集外的顾客u的n个属性,确定u的c属性值,以对顾客的流失作出预测。那么,A和P分别是( )。
A.聚类算法,聚类工具
B.分类算法,分类器
C.关联规则算法,规则集
D.多维分析算法,OLAP工具
相似考题
参考答案和解析
正确答案:B
由于有样本集和测试集之分,又有已有的类别标签,所以属于监督学习。分类:通过学习得到一个目标函数f,把每个属性集x映射到一个预先定义的类标号y。分类属于监督学习。聚类:根据在数据中发现的描述对象及其关系的信息,将数据对象分组,组内的对象相互之间是相似的,而不同组中的对象则不同。组内的相似性越大,组间差别越大,聚类就越好,属于无监督学习。关联规则挖掘:发现隐藏在大型数据集中的有意义的联系。多维分析是指各级管理决策人员从不同的角度、快速灵活地对数据仓库中的数据进行复杂查询多维分析处理。根据题意显然是符合分类。所以选B。
由于有样本集和测试集之分,又有已有的类别标签,所以属于监督学习。分类:通过学习得到一个目标函数f,把每个属性集x映射到一个预先定义的类标号y。分类属于监督学习。聚类:根据在数据中发现的描述对象及其关系的信息,将数据对象分组,组内的对象相互之间是相似的,而不同组中的对象则不同。组内的相似性越大,组间差别越大,聚类就越好,属于无监督学习。关联规则挖掘:发现隐藏在大型数据集中的有意义的联系。多维分析是指各级管理决策人员从不同的角度、快速灵活地对数据仓库中的数据进行复杂查询多维分析处理。根据题意显然是符合分类。所以选B。
更多“在对某商场的顾客进行流失预测分析时,先取得一个顾客样本集S,其模式为(id,a1,a2,…,an,c),其中id ”相关问题
-
第1题:
设某数据库中有一个用户样本集S,其模式为(a1,a2…an,c),其中ai(i=1…n)为用户的普通属性,属性c的取值范围为{高级用户,中级用户,普通用户}。现有算法A,对S进行处理,输出结果为P,P能根据新出现的用户U的n个普通属性的取值确定u的用户级别。则A和P分别是
A.聚类算法,聚类工具
B.多维分析算法,OLAP工具
C.预测模型,预测工具
D.分类算法,分类器
正确答案:D
解析:分类的目的是学会一个分类函数或分类模型(也常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类和回归都可用于预测。 -
第2题:
某商场为了了解顾客对商场服务的满意程度,随机抽选了n名顾客进行调查,结果有65%的顾客对商场服务满意。在95.45%的置信度下顾客对该商场服务的满意度的置信区间为( )
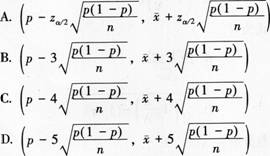 答案:A解析:
答案:A解析: -
第3题:
某商场为了解顾客对商场服务的满意程度,随机抽选了400名顾客进行调查,结果有65%的顾客对商场服务满意。试以95.45%的置信度估计顾客对该商场的满意度。答案:解析:n=400,p=65%,np=260≥5,n(1-p)=140≥5当1-a=95.45%时,查表得za/2=2
即得

即在95.45%的置信度下顾客对该商场服务的满意度的置信区间为(60.23%,69.77%)。 -
第4题:
某商场为了了解顾客对商场服务的满意称度,随机抽选了n名顾客进行调查结果有65%的顾客对商场服务满意。在95.45%置信度下顾客对该商场服务的满意度的置信区间为( )。
 答案:A解析:
答案:A解析: -
第5题:
某商场为了了解顾客对商场服务的满意程度,随机抽选了n名顾客进行调查,结果有65%的顾客对商场服务满意。在95.45%的置信度下顾客对该商场服务的满意度的置信区间为()。
 答案:A解析:
答案:A解析: