
(33)如果对关系 emp(eno, ename, salary)成功执行下面的SQL语句:CREATE CLUSTER INDEX name_index ON emp(salary)其结果是A)在 emp表上按sal娜升序创建了一个聚簇索引B)在 emp表上按salary降序创建了一个聚簇索引C)在 emp表上按salary升序创建了一个唯一索引D)在 emp表上按salary降序创建了一个唯一索引
题目
(33)如果对关系 emp(eno, ename, salary)成功执行下面的SQL语句:
CREATE CLUSTER INDEX name_index ON emp(salary)
其结果是
A)在 emp表上按sal娜升序创建了一个聚簇索引
B)在 emp表上按salary降序创建了一个聚簇索引
C)在 emp表上按salary升序创建了一个唯一索引
D)在 emp表上按salary降序创建了一个唯一索引
相似考题
更多“(33)如果对关系 emp(eno, ename, salary)成功执行下面的SQL语句: CREATE CLUSTER INDEX name_ind ”相关问题
-
第1题:
如果对关系emp(eno,ename,salary)成功执行下面的SQ[.语句:
CREATE CLUSTER INDEX name_index 0N emp(salary)
对此结果的正确描述是
A.在emp表上按salary升序创建了一个唯一索引
B.在emp表上按salary降序创建了一个唯一索引
C.在emp表上按salary升序创建了一个聚簇索引
D.在emp表上按salary降序创建了一个聚簇索引
正确答案:C
解析:在SQL语言中,创建索引使用CREATE INDEX语句,其一般格式为:CREATE[UNIQUE][cUSTER]INDEX<索引名>
ON<表名>(<列名>[<顺序>[,<列名>[<顺序>]]…]);
每个<列名>后面还可以用<顺序>指定索引值的排列顺序,包括ASC(升序)和I)ESC(降序)两种,默认是升序。UNIQUE表示此索引的每一个索引值只对应唯一的数据。CLUSTER表示要建立的索引是聚簇索引。 -
第2题:
The EMP table has these columns:ENAME VARCHAR2(35)SALARY NUMBER(8,2)HIRE_DATE DATEManagement wants a list of names of employees who have been with the company for more than five years. Which SQL statement displays the required results? ()
A. SELECT ENAME FROM EMP WHERE SYSDATE-HIRE_DATE >5;
B. SELECT ENAME FROM EMP WHERE HIRE_DATE-SYSDATE >5;
C. SELECT ENAME FROM EMP WHERE (SYSDATE_HIRE_DATE)/365 >5;
D. SELECT ENAME FROM EMP WHERE (SYSDATE_HIRE_DATE)*/365 >5;
参考答案:C
-
第3题:
如果对关系emp(eno, ename, salary)成功执行下而的SQL语句:
CREATE CLUSTER INDEX name_index ON emp(salary)
其结果是( )。
A) 在emp表上按salary升序创建了一个聚簇索引
B) 在emp表上按salary降序创建了一个聚簇索引
C) 在emp表上按salary升序创建了一个惟一索引
D) 在emp表上按salary降序创建了一个惟一索引
A.
B.
C.
D.
正确答案:A
-
第4题:
● 设有职工表emp(Eno,Ename,Sex,Age)(Eno为职工号,Ename为职工姓名,Sex为性别,Age为年龄)和salary(Eno,Hour,Month,Wage)(Hour为工作时长为多少小时,Month表示几月份,Wage为薪水),建立一个视图V-Salary(Eno,Ename,Hour,Month,Wage),并按Eno升序排序的SQL语句为:
(1)CREATE ( )
AS SELECT emp.Eno,emp.Ename ,salary.Hour,salary.Month,salary.Wage
FROM emp, salary
WHERE emp.Eno=salary.Eno
ORDER BY ENO
在此视图上查均月工资在3000以上的职工工资情况的SQL语句为:
SELECT Eno,Ename,AVG(Wage)
FROM V-Salary
GROUP BY ( )
HAVING AVG(Wage)>3000
( )
A. CREATE TABLE V-Salary(emp.Eno,emp.Ename,salary.Hour,salary.Month,salary.Wage)
B. CREATE VIEW V-Salary(Eno,Ename,Hour,Month,Wage)
C. CREATE TABLE V-Salary(Eno,Ename,Hour,Month,Wage)
D. CREATE INDEX V-Salary(Eno,Ename,Hour,Month,Wage)
( )
A. Eno B.Ename
C.Month D.Wage
正确答案:B,A
此题第一空容易,考查考生是否了解建立视图的语法规则。第二空也比较明显,在salary中有字段Month,用于标识当前记录是哪个月的工资记录,这就意味着在数据表中,一个Eno对应着多个工资记录,要计算平均值,可以先按Eno进行分组,再求工资平均值,所以第2空填A。 -
第5题:
下面所列条目中,( )不是标准的SQL语句。A.DELETE INDEX B.CREATE INDEXC.DELETE FROM D.CREATE UNIQUE CLUSTER INDEX
正确答案:A
删除索引的标准语句应为:DROP DELETE. -
第6题:
对于第7题的两个基本表,有一个SQL语句: SELECT ENO, ENAME FROM EMP WHERE DNO NOT IN (SELECT DNO FROM DEPT WHERE DNAME='金工车间');其等价的关系代数表达式是:______。
A.πENO,ENAME(σDNAME≠'金工车间'(EMP
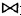 DEPT))
DEPT))B.πENO,ENAME

C.πENO,ENAME(EMP)-πENO,ENAME (σDNAME='金工车间'(EMP
DEPT))D.πENO,ENAME (EMP)-πENO,ENAME (σDNAME≠'金工车间'(EMP
DEPT))正确答案:C
-
第7题:
设有职工基本表:EMP(ENO,ENAME,AGE,SEX,SALARY),其属性分别表示职工号、姓.名、年龄、性别、工资.为每个工资低于1800元的男职工加薪300元,试写出这个操作的SQL语句.
正确答案:
UPDATE EMP
SET SALARY=SALARY+300
WHERE SALAEY<1800
AND SEX=‘男’; -
第8题:
对于:表EMP(ENO,ENAME,SALARY,DNO),其属性表示职工的工号、姓名、工资和所在部门的编号。表DEPT(DNO,DNAME),其属性表示部门的编号和部门名。有以下SQL语句:SELECT COUNT(DISTINCT DNO)FROM EMP其等价的查询语句是()。
- A、统计职工的总人数
- B、统计每一部门的职工人数
- C、统计职工服务的部门数目
- D、统计每一职工服务的部门数目
正确答案:C -
第9题:
Which SQL statement defines the FOREIGN KEY constraint on the DEPTNO column of the EMP table? ()
- A、CREATE TABLE EMP (empno NUMBER(4), ename VARCNAR2(35), deptno NUMBER(7,2) NOT NULL CONSTRAINT emp_deptno_fk FOREIGN KEY deptno REFERENCES dept deptno);
- B、CREATE TABLE EMP (empno NUMBER(4), ename VARCNAR2(35), deptno NUMBER(7,2) CONSTRAINT emp_deptno_fk REFERENCES dept (deptno));
- C、CREATE TABLE EMP (empno NUMBER(4) ename VARCHAR2(35), deptno NUMBER(7,2) NOT NULL, CONSTRAINT emp_deptno_fk REFERENCES dept (deptno) FOREIGN KEY (deptno));
- D、CREATE TABLE EMP (empno NUMBER(4), ename VARCNAR2(35), deptno NUMBER(7,2) FOREIGN KEY CONSTRAINT emp deptno fk REFERENCES dept (deptno));
正确答案:B -
第10题:
单选题在PL/SQL中定义一个可以存放雇员表(EMP)的员工名称(ENAME)的PL/SQL表类型,应该()Atype array arr_type[emp.ename%type] index by binary_integer;
Btype table arr_type[emp.ename%type] index by binary_integer;
Ctype arr_type is table of emp.ename%type index by binary_integer;
Dtype arr_type is pl_sql table of emp.ename%type index by binary_integer;
正确答案: D解析: 暂无解析 -
第11题:
单选题Which SQL statement generates the alias Annual Salary for the calculated column SALARY*12?()ASELECT ename, salary*12 ‘Annual Salary’ FROM employees;
BSELECT ename, salary*12 “Annual Salary” FROM employees;
CSELECT ename, salary*12 AS Annual Salary FROM employees;
DSELECT ename, salary*12 AS INITCAP(“ANNUAL SALARY”) FROM employees
正确答案: A解析: 暂无解析 -
第12题:
单选题对于:表EMP(ENO,ENAME,SALARY,DNO),其属性表示职工的工号、姓名、工资和所在部门的编号。表DEPT(DNO,DNAME),其属性表示部门的编号和部门名。有以下SQL语句:SELECT COUNT(DISTINCT DNO)FROM EMP其等价的查询语句是()。A统计职工的总人数
B统计每一部门的职工人数
C统计职工服务的部门数目
D统计每一职工服务的部门数目
正确答案: D解析: 暂无解析 -
第13题:
根据SQL标准,要创建唯一索引该使用下面哪种语句?()
A CREATE UNIQUE INDEX
B CREATE CLUSTER INDEX
C CREATE ONLY INDEX
D CREATE PRIMARY INDEX
参考答案A -
第14题:
对于基本表EMP(ENO,ENAME,SALARY,DNO),其属性表示职工的工号、姓名、工资和所在部门的编号。基本表DEPT(DNO,DNAME)其属性表示部门的编号和部门名。有一SQL语句: SELECT COUNT (DI STINCT DNO)FROM EMP;其等价的查询语句是______。
A.统计职工的总人数
B.统计每一部门的职工人数
C.统计职工服务的部门数目
D.统计每一职工服务的部门数目
正确答案:C
-
第15题:
如果对关系emp(eno,ename,salary)成功执行下面的SQL语句: CREATE CLUSTER INDEXname_index ON emp(salary)对此结果的正确描述是
A.在emp表上按salary升序创建了一个聚簇索引
B.在emp表上按salary降序创建了一个聚簇索引
C.在emp表上按salary升序创建了一个唯一索引
D.在emp表上按salary降序创建了一个唯一索引
正确答案:A
解析:通过CREATEINDEXname_indexONemp(salary)判断语句要在emp表上按salary创建索引nameindex,CLUSTER表示要建立的索引是聚簇索引,索引排列顺序的缺省值为ASC(升序)。因此本题的答案为A。 -
第16题:
如果对关系S(number,name,score)成功执行下列SQL语句: CREATE CLUSTER INDEX name_index ON S(score) 对此结果的正确描述是( )。
A.在S表上按salary升序创建了一个唯一索引
B.在S表上按salary降序创建了一个唯一索引
C.在S表上按salary升序创建了一个聚簇索引
D.在S表上按salary降序创建了一个聚簇索引
正确答案:C
解析:SQL用CREATE INDEX语句创建索引。其一般格式为:
CREATE [UNIQUE][CLUSTER]INDEX<索引名>
ON<表名>(<列名>[<顺序>[,<列名>[顺序]]……]);
<顺序>指定索引的排列顺序,包括ASC(升序)和DESC(降序)两种,缺省值为ASC。UNIQUE表示此索引的每一个索引值只对应唯一的数据记录。CLUSTER表示要建立的是聚簇索引。
-
第17题:
设有职工关系Emp (Eno,Ename,Esex,EDno)和部门关系Dept (Dno,Dname, Daddr),创建这两个关系的SQL语句如下:
CREATE TABLE Emp (
Eno CHAR(4),
Ename CHAR(8),
Esex CHAR(1) CHECK(Esex IN ('M','F')),
EDno CHAR(4) REFERENCES Dept (Dno),
PRIMARY KEY (Eno)
);
CREATE TABLE Dept (
Dno CHAR(4) NOT NULL UNIQUE,
Dname CHAR(20),
Daddr CHAR(30)
);
直接运行该语句,DBMS会报错,原因是(53)。若经过修改,上述两个表创建完毕之后(尚无数据),则下述语句中能被执行的是(54)。
A.创建表Dept时没有指定主码
B.创建表Dept时没有指定外码
C.创建表Emp时,被参照表Dept尚未创建
D.表Emp的外码EDno与被参照表Dept的主码Dno不同名
正确答案:C
解析:本题考查对完整性约束的掌握。本题中,职工关系Emp为参照关系,其属性EDno参照部门关系Dept中的Dno,在创建Emp关系时,系统会根据参照约束查找被参照关系,因此,被参照关系就先于参照关系而建立。约束一旦建立,更新数据必须满足约束条件才可正确执行,表Emp有主码约束和参照约束,故Eno不能取空值,EDno列因为被参照关系Dept尚无记录,故只能取空值。 -
第18题:
在PL/SQL中定义一个可以存放雇员表(EMP)的员工名称(ENAME)的PL/SQL表类型,应该()A.type array arr_type[emp.ename%type] index by binary_integer;
B.type table arr_type[emp.ename%type] index by binary_integer;
C.type arr_type is table of emp.ename%type index by binary_integer;
D.type arr_type is pl_sql table of emp.ename%type index by binary_integer;
参考答案:C
-
第19题:
阅读下列说明,回答问题。【说明】某大型集团公司的数据库的部分关系模式如下:员工表:EMP(Eno,Ename,Age,Sex, Title),各属性分别表示员工工号、姓名、年龄、性别和职称级别,其中性别取值为"男""女";公司表:COMPANY(Cno,Cname,City),各属性分别表示公司编号、名称和所在城市;工作表:WORKS(Eno.Cno,Salary),各属性分别表示职工工号、工作的公司编号和工资。有关关系模式的属性及相关说明如下:(1)允许一个员工在多家公司工作,使用身份证号作为工号值。(2)工资不能低于1500元。 【问题1】请将下面创建工作关系的SQL语句的空缺部分补充完整,要求指定关系的主码、外码,以及工资不能低于1500元的约束。CREATE TABLE WORKS(Eno CHAR(10)( a ), Cno CHAR(4)( b ), Salary int( c ), PRIMARY KEY( d ));【问题2】请将下面SQL语句的空缺部分补充完整。(1)创建女员工信息的视图FemaleEMP.属性有Eno、Ename、Cno、Cname和Salary,请将下面SQL语句的空缺部分补充完整。 CREATE( e )AS SELECT EMP.Eno, Ename, COMPANY.Cno, Cname, SalaryFROM EMP, COMPANY, WORKSWHERE( f );(2)员工的工资由职称级别的修改自动调整,需要用触发器来实现员工工资的自动维护,函数float Salary_value(char(10) Eno)依据员工号计算员工新的工资。请将下面SQL语句的空缺部分补充完整。CREATE( g )Salary_TRG AFTER( h )ON EMPREFERENCING new row AS nrowFOR EACH ROWBEGINUPDATE WORKS SET ( i ) WHERE( j );END【问题3】请将下面SQL语句的空缺部分补充完整。(1)查询员工最多的公司编号和公司名称。SELECT COMPANY.Cno, CnameFROM COMPANY, WORKSWHERE COMPANY.Cno=WORKS.CnoGROUP BY( k )HAVING( l ) (SELECT COUNT( * )FROM WORKS GROUP BY Cno) ;(2) 查询所有不在"中国银行北京分行"工作的员工工号和姓名。。SELECT Eno, EnameFROM EMPWHERE Eno( m ) ( SELECT EnoFROM( n )WHERE( o )AND Cname='中国银行北京分行' );答案:解析:【问题1】本题考查SQL语句的应用。此类题目要求考生掌握SQL语句的基本语法和结构,认真阅读题目给出的关系模式,针对题目的要求具体分析并解答。本试题已经给出了3个关系模式,需要分析每个实体的属性特征及实体之间的联系,补充完整SQL语句。由题目说明可知,Eno和Cno两个属性组合是WORKS关系表的主键,所以在PRIMARYKEY后填的应该是(Eno,Cno)组合;Eno和Cno分别作为外键引用到EMP和COMPANY关系表的主键,因此需要用REFERENCES对这两个属性进行外键约束;由"工资不能低于1500元"的要求,可知需要限制账户余额属性值的范围,通过CHECK约束来实现。从上述分析可知,完整的SQL语句如下:

【问题2】 (1) 创建视图需要通过CREATEVIEW语句来实现,由题目可知视图的属性有(Eno,Ename,Cno,Cname,Salary);通过公共属性列Eno和Cno对使用的三个基本表进行连接;由于只创建女员工的试图,所以还要在WHERE后加入"Sex='女'"的条件。从上分析可见,完整的SQL语句如下:

(2) 创建触发器可通过CREATETRIGGER语句实现,要求考生掌握触发器的基本语法结构。按照问题要求,在工资关系中更新职工职称级别时触发器应自动执行,故需要创建基于UPDATE类型的触发器,其触发条件是更新职工职称级别;最后添加表连接条件。完整的触发器实现的方案如下:

【问题3】SQL查询通过SELECT语句实现。(1)根据问题要求,可通过子查询实现"查询员工最多的公司编号和公司名称"的查询;对COUNT函数计算的结果应通过HAVING条件语句进行约束;通过Cno和Cname的组合来进行分组查询。完整的SQL语句如下:

(2) 根据问题要求,需要使用嵌套查询。先将WORKS和COMPANY表进行连接,查找出所有在"中国银行北京分行"工作的员工;然后在雇员表中使用"NOTIN"或者"<>ANY"查询不在前述结果里面的员工即可。完整的SQL语句如下:

-
第20题:
SQL中使用()语句创建索引。
- A、CREATE PROC
- B、CREATE VIEW
- C、CREATE TABLE
- D、CREATE INDEX
正确答案:D -
第21题:
单选题Evaluate this SQL statement: SELECT ename, sal, 12* sal+100 FROM emp; The SAL column stores the monthly salary of the employee. Which change must be made to the above syntax to calculate the annual compensation as "monthly salary plus a monthly bonus of $100, multiplied by 12"?()ANo change is required to achieve the desired results.
BSELECT ename, sal, 12* (sal+100) FROM emp;
CSELECT ename, sal, (12* sal)+100 FROM emp;
DSELECT ename, sal +100,*12 FROM emp;
正确答案: B解析: 暂无解析 -
第22题:
单选题如果对关系emp(eno,ename,salary)成功执行下面的SQL语句:CREATECLUSTERINDEXname_indexONemp(salary),其结果是()A在emp表上按salary升序创建了一个聚簇索引
B在emp表上按salary降序创建了一个聚簇索引
C在emp表上按salary升序创建了一个唯一索引
D在emp表上按salary降序创建了一个唯一索引
正确答案: B解析: 通过CREATE INDEX name_index ON emp(salary)判断语句要在emp表上按salary创建索引name index,CLUSTER表示要建立的索引是聚簇索引,索引排列顺序的缺省值为ASC(升序)。因此本题的答案为A。 -
第23题:
单选题The EMP table has these columns: ENAME VARCHAR2(35) SALARY NUMBER(8,2) HIRE_DATE DATE Management wants a list of names of employees who have been with the company for more than five years. Which SQL statement displays the required results? ()ASELECT ENAME FROM EMP WHERE SYSDATE-HIRE_DATE >5;
BSELECT ENAME FROM EMP WHERE HIRE_DATE-SYSDATE >5;
CSELECT ENAME FROM EMP WHERE (SYSDATE_HIRE_DATE)/365 >5;
DSELECT ENAME FROM EMP WHERE (SYSDATE_HIRE_DATE)*/365 >5;
正确答案: C解析: 暂无解析