
在霍夫曼编码中,若编码长度只允许小于等于4,则除了两个字符已编码为0和10外,还可以最多对______个字符编码。A.4B.5C.6D.7
题目
在霍夫曼编码中,若编码长度只允许小于等于4,则除了两个字符已编码为0和10外,还可以最多对______个字符编码。
A.4
B.5
C.6
D.7
相似考题
更多“在霍夫曼编码中,若编码长度只允许小于等于4,则除了两个字符已编码为0和10外,还可以最多对______ ”相关问题
-
第1题:
霍夫曼编码将频繁出现的字符采用短编码,出现频率较低的字符采用长编码。具体的操作过程为:i)以每个字符的出现频率作为关键字构建最小优先级队列;ii)取出关键字最小的两个结点生成子树,根节点的关键字为孩子节点关键字之和,并将根节点插入到最小优先级队列中,直至得到一颗最优编码树。霍夫曼编码方案是基于(64)策略的。用该方案对包含a到f六个字符的文件进行编码,文件包含100000个字符,每个字符的出现频率(用百分比表示)如下表所示,则与固定长度编码相比,

A.分治
B.贪心
C.动态规划
D.回溯
正确答案:B
根据题目对霍夫曼编码的描述,我们不难知道,每次都是选择当前最小的情况,这符合贪心算法总是找当前看来最优的情况,因此属于贪心策略。如果对包含100,000个字符,且这些字符都属于a到f。那么如果采用固定长度的编码,针对于每个字符需要3位来编码(因为有6个不同的字符,至少需要3位才能表示6种不同的变化)。那么对100000个字符编码,其编码长度为300000。如果采用霍夫曼编码,那么首先我们就要根据字符出现的频率构造出其霍夫曼树。首先选择出现频率最低的4和8,生成子树,其父节点为12,然后放入出现频率队列中,后面的采用同样的道理,以此类推。构造出的霍夫曼树如下图所示:由图可以知道,a的编码为00,b的编码为11,c的编码为0100,d的编码为0101,e的编码为011,f的编码为10。因此总的编码长度为(2*18%+2*32%+4*4%+4*8%+3*12%+2*26%)*100000=23600,因此节省的存储空间大小为30000-23600=6400。因此节省的存储空间为比例为6400/30000=21%。 -
第2题:
下表为某文件中字符的出现频率,采用霍夫曼编码对下列字符编码,则字符序列“bee”的编码为( 62 );编码::“110001001101”的对应的字符序列( 63 )

A.10111011101
B.10111001100
C.001100100
D.110011011
正确答案:A
-
第3题:
已知一个文件中出现的各个字符及其对应的频率如下表所示。若采用定长编码,则该文件中字符的码长应为 ( ) 。若采用Huffman编码,则字符序列"face"的编码应为 (请作答此空) 。 A.110001001101
A.110001001101
B.001110110011
C.101000010100
D.010111101011答案:A解析:① 有6个不同字母,需要采用3位二进制进行编码。
② Huffman编码,即哈夫曼静态编码,它对需要编码的数据进行两遍扫描:第一遍统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并必须把树的信息保存起来,即把字符0~255(28=256)的频率值以2~4Bytes的长度顺序存储起来,(用4Bytes的长度存储频率值,频率值的表示范围为0~232-1,这已足够表示大文件中字符出现的频率了。)以便解压时创建同样的哈夫曼树进行解压;第二遍则根据第一遍扫描得到的哈夫曼树进行编码,并把编码后得到的码字存储起来。 -
第4题:
已知一个文件中出现的各个字符及其对应的频率如下表所示。若采用定长编码,则该文件中字符的码长应为(64)。若采用Huffman编码,则字符序列“face”的编码应为(65)。
 A.2
A.2
B.3
C.4
D.5答案:B解析:①有6个不同字母,需要采用3位二进制进行编码。
②哈夫曼静态编码:它对需要编码的数据进行两遍扫描:第一遍统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并必须把树的信息保存起来,即把字符0~255(28=256)的频率值以2~4BYTES的长度顺序存储起来,(用4Bytes的长度存储频率值,频率值的表示范围为0~232-1,这已足够表示大文件中字符出现的频率了。)以便解压时创建同样的哈夫曼树进行解压;第二遍则根据第一遍扫描得到的哈夫曼树进行编码,并把编码后得到的码字存储起来。 -
第5题:
下表为某文件中字符的出现频率,采用霍夫曼编码对下列字符编码,编码“110001001101”的对应的字符序列为( )。 A.bad
A.bad
B.bee
C.face
D.bace答案:C解析:110001001101 中:f(1100) a(0) c(100) e(1101)。
-
第6题:
已知某文档包含5个字符。每个字符出现的频率如下表所示。采用霍夫曼编码对该文档压缩存储,则单词“cade”的编码为( ),文档的压缩比为(请作答此空) A.20%
A.20%
B.25%
C.27%
D.30%答案:B解析:压缩前,属于定长编码,每个字符用3位编码,压缩后编码长度是:1*40%+3*10%+3*20%+3*16%+3*14%=2.2,压缩率:(3-2.2)/3=27% -
第7题:
在税控发票开票软件(金税盘版)V2,0中设置客户编码时,客户编码采用变长分级编码方案,最大长度是()位字符。
- A、16
- B、19
- C、12
- D、14
正确答案:A -
第8题:
若一离散无记忆信源的信源熵H(X)等于2.5,对信源进行等长的无失真二进制编码,则编码长度至少为()。
正确答案:3 -
第9题:
以下关于霍夫曼编码的说明中,正确的是()。
- A、出现频率越高的符号,编码越短
- B、出现频率越高的符号,编码越长
- C、霍夫曼编码是一种等长编码
- D、霍夫曼编码是一种基于字典的编码
正确答案:A -
第10题:
单选题以下编码中,与使用频率的有关的编码是()。A算术编码
BLZW编码
CJPEG编码
D霍夫曼编码
正确答案: B解析: 暂无解析 -
第11题:
填空题若一离散无记忆信源的信源熵H(X)等于2.5,对信源进行等长的无失真二进制编码,则编码长度至少为()。正确答案: 3解析: 暂无解析 -
第12题:
单选题以下压缩算法中()属于有损压缩。A游程长度编码
B霍夫曼编码
CLcmpcl Ziv编码
DMPEG
正确答案: C解析: 暂无解析 -
第13题:
在哈夫曼编码中,若编码长度只允许小于等于4,则除了两个字符已编码为0和10外,还可以最多对______个字符编码。
A.4
B.5
C.6
D.7
请帮忙给出正确答案和分析,谢谢!
正确答案:A
-
第14题:
已知一个文件中出现的各字符及其对应的频率如下表所示。若采用定长编码,则该文件中字符的码长应为 (64) 。若采用Huffman编码,则字符序列“face”的编码应为 (65) 。

A.2
B.3
C.4
D.5
正确答案:B
本题考查Huffman编码的相关知识。字符在计算机中是用二进制表示的,每个字符用不同的二进制编码来表示。码的长度影响存储空间和传输效率。若是定长编码方法,用2位码长,只能表示4个字符,即00、01、10和11;若用3位码长,则可以表示8个字符,即000、001、010、O11、100、101、110、111。对于题中给出的例子,一共有6个字符,因此采用3位码长的编码可以表示这些字符。Huffman编码是一种最优的不定长编码方法,可以有效的压缩数据。要使用Huffman编码,除了知道文件中出现的字符之外,还需要知道每个字符出现的频率。下图(a)是题干中给出对应的编码树,可以看到,每个字符及其对应编码为图(b),因此字符序列“face”的编码应为110001001101,即65选择A。 -
第15题:
已知一个文件中出现的各个字符及其对应的频率如下表所示。若采用定长编码,则该文件中字符的码长应为 (请作答此空) 。若采用Huffman编码,则字符序列"face"的编码应为 ( ) 。 A.2
A.2
B.3
C.4
D.5答案:B解析:① 有6个不同字母,需要采用3位二进制进行编码。
② Huffman编码,即哈夫曼静态编码,它对需要编码的数据进行两遍扫描:第一遍统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并必须把树的信息保存起来,即把字符0~255(28=256)的频率值以2~4Bytes的长度顺序存储起来,(用4Bytes的长度存储频率值,频率值的表示范围为0~232-1,这已足够表示大文件中字符出现的频率了。)以便解压时创建同样的哈夫曼树进行解压;第二遍则根据第一遍扫描得到的哈夫曼树进行编码,并把编码后得到的码字存储起来。 -
第16题:
下表为某文件中字符的出现频率,采用霍夫曼编码对下列字符编码,则字符序列“bee”的编码为( ) A.10111011101
A.10111011101
B.10111001100
C.001100100
D.110011011答案:A解析:110001001101 中:f(1100) a(0) c(100) e(1101)。 -
第17题:
已知某文档包含5个字符。每个字符出现的频率如下表所示。采用霍夫曼编码对该文档压缩存储,则单词“cade”的编码为(请作答此空),文档的压缩比为( ) A.1110110101
A.1110110101
B.1100111101
C.1110110100
D.1100111100答案:A解析:根据题意构造哈夫曼树如下。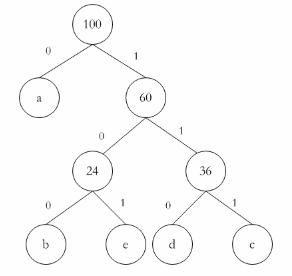
a的编码:0,b的编码100,c的编码111,d的编码110,e的编码:101。单词“cade”的编码就是“1110110101”。 -
第18题:
对于扫描结果:aaaabbbccdeeeeefffffff,若对其进行霍夫曼编码之后的结果是:f=01e=11a=10b=001c=0001d=0000。若使用行程编码和霍夫曼编码的混合编码,压缩率是否能够比单纯使用行程编码有所提高?
正确答案:原始扫描结果所占空间为:22*8=176(bits)单纯行程编码的结果是:4a3b2c1d5e7f,共占6(3+8)=66(bits),压缩比为:176:66
Hufman与行程编码混合:41030012000110000511701,共占3+2+3+3+3+4+3+4+3+2+3+2=35(bits),压缩比为176:35.即故压缩比有所提高。 -
第19题:
以下压缩算法中()属于有损压缩。
- A、游程长度编码
- B、霍夫曼编码
- C、Lcmpcl Ziv编码
- D、MPEG
正确答案:D -
第20题:
以下编码中,与使用频率的有关的编码是()。
- A、算术编码
- B、LZW编码
- C、JPEG编码
- D、霍夫曼编码
正确答案:D -
第21题:
关于信号的编码正确的是:()
- A、模拟信号经过抽样和量化后在时间和幅值上都变成了离散的数字信号,把多电平码转换成二进制码的过程称为编码。
- B、抽样值在时间上是离散的,所以可以直接对抽样值进行编码
- C、在PCM系统中抽样量化值为0则相应的编码值为0
- D、编码可分为线性编码和非线性编码
正确答案:A -
第22题:
单选题以下关于霍夫曼编码的说明中,正确的是()。A出现频率越高的符号,编码越短
B出现频率越高的符号,编码越长
C霍夫曼编码是一种等长编码
D霍夫曼编码是一种基于字典的编码
正确答案: A解析: 暂无解析 -
第23题:
问答题对于扫描结果:aaaabbbccdeeeeefffffff,若对其进行霍夫曼编码之后的结果是:f=01e=11a=10b=001c=0001d=0000。若使用行程编码和霍夫曼编码的混合编码,压缩率是否能够比单纯使用行程编码有所提高?正确答案: 原始扫描结果所占空间为:22*8=176(bits)单纯行程编码的结果是:4a3b2c1d5e7f,共占6(3+8)=66(bits),压缩比为:176:66
Hufman与行程编码混合:41030012000110000511701,共占3+2+3+3+3+4+3+4+3+2+3+2=35(bits),压缩比为176:35.即故压缩比有所提高。解析: 暂无解析