
计算机网络中的结点(NODE)是指()。A.网络工作站B.在通讯线路与主机之间设置的通信线路控制处理机C.为延长传输距离而设立的中继站D.传输介质的连接点
题目
A.网络工作站
B.在通讯线路与主机之间设置的通信线路控制处理机
C.为延长传输距离而设立的中继站
D.传输介质的连接点
相似考题
更多“计算机网络中的结点(NODE)是指()。 ”相关问题
-
第1题:
在C语言中,可以用typedef声明新的类型名来代替已有的类型名,比如有学生链表结点: typedef struct node{ int data; struct node * link; }NODE, * LinkList; 下述说法正确的是______。
A.NODE是结构体struct node的别名
B.* LinkList也是结构体struct node的别名
C.LinkList也是结构体struct node的别名
D.LinkList等价于node*
正确答案:A
解析:其实题中的定义相当于下述两个定义:typedefstructnode{intdata;structnode*link;}NODE;typedefstructnode{intdata;structnode*link;)*LinkList;前者给structnode取了个新名字NODE,即structnode和NODE是等价的;后者把structnode*命名为LinkList。 -
第2题:
阅读以下说明和C语言函数,将应填入(n)处的字句写在对应栏内。
【说明】
函数sort (NODE *head)的功能是;用冒泡排序法对单链表中的元素进行非递减排序。对于两个相邻结点中的元素,若较小的元素在前面,则交换这两个结点中的元素值。其中,head指向链表的头结点。排序时,为了避免每趟都扫描到链表的尾结点,设置一个指针endptr,使其指向下趟扫描需要到达的最后一个结点。例如,对于图4-1(a)的链表进行一趟冒泡排序后,得到图4-1(b)所示的链表。

链表的结点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
} NODE;
【C语言函数】
void sort (NODE *head)
{ NODE *ptr,*preptr, *endptr;
int tempdata;
ptr = head -> next;
while ((1)) /*查找表尾结点*/
ptr = ptr -> next;
endptr = ptr; /*令endptr指向表尾结点*/
ptr =(2);
while(ptr != endptr) {
while((3)) {
if (ptr->data > ptr->next->data){
tempdata = ptr->data; /*交换相邻结点的数据*/
ptr->data = ptr->next->data;
ptr->next->data = tempdata;
}
preptr =(4); ptr = ptr -> next;
}
endptr =(5); ptr = head->next;
}
}
正确答案:(1)ptr -> next (2)head->next (3)ptr !=endptr或其等价形式 (4)ptr (5)preptr
(1)ptr -> next (2)head->next (3)ptr !=endptr,或其等价形式 (4)ptr (5)preptr 解析:本题考查链表运算能力。
从题目中的以下代码可知,ptr最后应指向表尾结点。
ptr = head -> next;
while((1))/*查找表尾结点*/
ptr = ptr -> next;
endptr = ptr; /*令endptr指向表尾结点*/
显然,空(1)处应填入“ptr->next”,这样循环结束时,ptr指向表尾结点。若填入“ptr”,则循环结束时,ptr为空指针。
进行冒泡排序时,从头至尾依次比较逻辑上相邻的两个结点的数据,如果小元素在前大元素在后,则交换。这样,经过一趟扫描,就将最大元素交换到了表的最后。下一趟可将次大元素交换到最大元素之前。显然,空(2)处应填入“head->next”。
由于程序设置的endptr用于指示出每趟扫描需到达的最后一个结点,ptr用于依次扫描链表中的结点,因此空(3)处的循环条件为“ptr != endptr”。
显然,指针preptr起的作用是指向ptr的前驱结点,因此,ptr每向后修改一次,相应地preptr就要修改一次,空(4)处应填入“ptr”。本趟循环结束后,下一趟扫描也就确定了,因此在空(5)处填入“preptr”。 -
第3题:
链表题:一个链表的结点结构
struct Node
{
int data ;
Node *next ;
};
typedef struct Node Node ;
(1)已知链表的头结点head,写一个函数把这个链表
逆序( Intel)
正确答案:
Node * ReverseList(Node *head) //链表逆序
{
if ( head == NULL || head->next == NULL )
return head;
Node *p1 = head ;
Node *p2 = p1->next ;
Node *p3 = p2->next ;
p1->next = NULL ;
while ( p3 != NULL )
{
p2->next = p1 ;
p1 = p2 ;
p2 = p3 ;
p3 = p3->next ;
}
p2->next = p1 ;
head = p2 ;
return head ;
} -
第4题:
以下程序中函数fun的功能是:构成—个如图所示的带头结点的单向链表,在结点的数据域中放入了具有两个字符的字符串。函数disp的功能是显示输出该单向链表中所有结点中的字符串。请填空完成函数disp。

include<stdio.h>
typedef struct node /*链表结点结构*/
{ char sub[3];
struct node *next;
}Node;
Node fun(char s) /* 建立链表*/
{ ...... }
void disp(Node *h)
{ Node *p;
p=h->next;
while([ ])
{printf("%s\n",p->sub);p=[ ];}
}
main()
{ Node *hd;
hd=fun(); disp(hd);printf("\n");
}
正确答案:p!=NULL 或 p 或 p!=0 或 p!='0' p->next 或 (*P).next
p!=NULL 或 p 或 p!=0 或 p!='0' p->next 或 (*P).next 解析:此题主要考核的是用指针处理链表。自定义结构体类型名为Node,并定义一个指向结点类型的指针next。用Node来定义头结点指针变量h,并定义另—个指针变量p指向了第—个结点,在满足p未指向最后—个结点的空指针时,输出p所指向结点的字符串,所以第—个空填p!=NULL或p或p!=0或p!='\0',然后将p指向下一个非空结点,所以第二个空填p->next或与其等效的形式,反复执行直到所有的结点都输出,即遇到p的值为NULL。 -
第5题:
试题四(共 15 分)
阅读以下说明和 C 语言函数,将应填入 (n) 处的字句写在答题纸的对应栏内。
[说明]
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图4-1(a)、(b)是经函数 compress()处理前后的链表结构示例图。
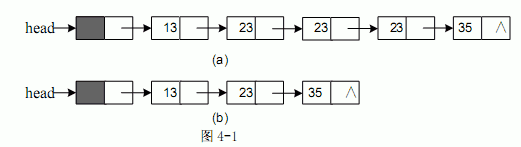
链表的结点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
}NODE;
[C 语言函数]
void compress(NODE *head)
{ NODE *ptr,*q;
ptr = (1) ; /* 取得第一个元素结点的指针 */
while ( (2) && ptr -> next) {
q = ptr -> next;
while(q && (3) ) { /* 处理重复元素 */
(4) = q -> next;
free(q);
q = ptr -> next;
}
(5) = ptr -> next;
}/* end of while */
}/* end of compress */
正确答案:
-
第6题:
决策树中不包含一下哪种结点()
- A、根结点(root node)
- B、内部结点(internal node)
- C、外部结点(external node)
- D、叶结点(leaf node)
正确答案:C -
第7题:
网络(network)由若干结点(node)和连接这些结点的链路(link)组成。
正确答案:正确 -
第8题:
如果设treeView1=new TreeView(),TreeNode node=new TreeNode("根结点"),则treeView1.Nodes.Add(node)返回的是一个类型的值。()
- A、TreeNode;
- B、int;
- C、string;
- D、TreeView;
正确答案:B -
第9题:
问答题下列给定程序是建立一个带头结点的单向链表,并用随机函数为各结点赋值。函数fun()的功能是:将单向链表结点(不包括头结点)数据域为偶数的值累加起来,并作为函数值返回。 请改正函数fun中的错误,使它能得出正确的结果。 注意:部分源程序在文件MODII.C中,不要改动main函数,不得增行或删行,也不得更改程序的结构! 试题程序:#include#include #include typedef struct aa{ int data; struct aa *next;}NODE;int fun(NODE *h){ int sum=0; NODE *p; p=h->next; /*********found*********/ while(p->next) { if(p->data%2==0) sum+=p->data; /*********found*********/ p=h->next; } return sum;}NODE *creatlink(int n){ NODE *h,*p,*s; int i; h=p=(NODE *)malloc(sizeof(NODE)); for(i=1;i 正确答案:
(1)错误:while(p->next)
正确:while(p)或while(p!=NULL)
(2)错误:p=h->next;
正确:p= p ->next;解析:
错误1:执行p=p->next后,p指针已经指向链表第一个包含数据域的结点。fun函数的while循环判断当前指针p指向的结点是否存在,若存在则对该结点数据域进行判断操作,而不是判断p指针的指针域是否为空。
错误2:fun函数的while循环中判断结束后指针指向下一个结点,操作为p=p->next。 -
第10题:
问答题设某带头结头的单链表的结点结构说明如下:typedef struct nodel{int data struct nodel*next;}node;试设计一个算法:void copy(node*headl,node*head2),将以head1为头指针的单链表复制到一个不带有头结点且以head2为头指针的单链表中。正确答案: 一边遍历,一边申请新结点,链接到head2序列中。解析: 暂无解析 -
第11题:
单选题计算机网络中的结点(NODE)是指()。A网络工作站
B在通讯线路与主机之间设置的通信线路控制处理机
C为延长传输距离而设立的中继站
D传输介质的连接点
正确答案: B解析: 暂无解析 -
第12题:
问答题设有一个不带头结点的单向链表,头指针为head,结点类型为NODE,每个结点包含一个数据域data和一个指针域next,该链表有两个结点,p指向第二个结点(尾结点),按以下要求写出相应语句。已知p1指向另一个新结点,把它插入到p所指结点和尾结点之间。正确答案: P1->next=p->next;
P->next=p1;解析: 暂无解析 -
第13题:
函数min()的功能是:在带头结点的单链表中查找数据域中值最小的结点。请填空includestruc 函数min()的功能是:在带头结点的单链表中查找数据域中值最小的结点。请填空
include <stdio.h>
struct node
{ int data;
struct node *next;
};
int min(struct node *first)/*指针first为链表头指针*/
{ struct node *p; int m;
p=first->next; re=p->data; p=p->next;
for( ;p!=NULL;p=【 】)
if(p->data<m ) re=p->data;
return m;
}
正确答案:p->next
p->next 解析:本题考查的知识点是:链表的筛选。题目要求筛选出链表中最小的值,所以需要先定义一个临时变量,并将第1个值赋给该变量,就好像本题程序中定义的变量 m。然后遍历整个链表,拿链表中的每一个值跟m比较,如果找到比m小的值,就让m等于该值,这样遍历结束后,m中就是该链表的最小值了。题目中的空位于for循环的第3个表达式处,这里的for循环就是用来遍历整个链表的,所以该表达式需要完成的任务是:将循环变量p指向当前结点的下一个结点。故不难得知应填p->next。 -
第14题:
阅读以下说明和C语言函数,将应填入(n)。
【说明】
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
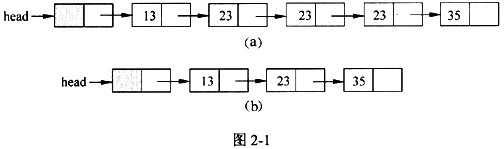
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}NODE;
【C语言函数】
void compress(NODE *head)
{ NODE *ptr,*q;
ptr= (1); /*取得第一个元素结点的指针*/
while( (2)&& ptr->next) {
q=ptr->next;
while(q&&(3)) { /*处理重复元素*/
(4)q->next;
free(q);
q=ptr->next;
}
(5) ptr->next;
}/*end of while */
}/*end of compress*/
正确答案:(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data或其等价表示 (4)ptr->next (5)ptr
(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data,或其等价表示 (4)ptr->next (5)ptr 解析:本题考查基本程序设计能力。
链表上的查找、插入和删除运算是常见的考点。本题要求去掉链表中的重复元素,使得链表中的元素互不相同,显然是对链表进行查找和删除操作。
对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以采用两种思路。
1.顺序地遍历链表,对于逻辑上相邻的两个元素,比较它们是否相同,若相同,则删除后一个元素的结点,直到表尾。代码如下:
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){ /*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data){/*处理重复元素*/
ptr->next=q->next;/*将结点从链表中删除*/
free(q);
q=ptr->next; /*继续扫描后继元素*/
}
ptr=ptr->next;
}
2.对于每一组重复元素,先找到其中的第一个结点,然后向后查找,直到出现一个相异元素时为止,此时保留重复元素的第一个结点,其余结点则从链表中删除。
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){/*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data) /*查找重复元素*/
q=q->next;
s=ptr->next; /*需要删除的第一个结点*/
ptr->next=q; /*保留重复序列的第一个结点,将其余结点从链表中删除*/
while(s && s!=q}{/*逐个释放被删除结点的空间*/
t = s->next;free(s);s = t;
}
ptr=ptr->next;
}
题目中采用的是第一种思路。 -
第15题:
阅读以下说明,Java代码将应填入(n)处的字句写在对应栏内。
【说明】
链表和栈对象的共同特征是:在数据上执行的操作与在每个对象中实体存储的基本类型无关。例如,一个栈存储实体后,只要保证最后存储的项最先用,最先存储的项最后用,则栈的操作可以从链表的操作中派生得到。程序6-1实现了链表的操作,程序6-2实现了栈操作。
import java.io.*;
class Node //定义结点
{ private String m_content;
private Node m_next;
Node(String str)
{ m_content=str;
m_next=null; }
Node(String str,Node next)
{ m_content=str;
m_next=next; }
String getData() //获取结点数据域
{ return m_content;}
void setNext(Node next] //设置下一个结点值
{ m_next=next; }
Node getNext() //返回下一个结点
{ return m_next; )
}
【程序6-1】
class List
{ Node Head;
List()
{ Head=null; }
void insert(String str) //将数据str的结点插入在整个链表前面
{ if(Head==null)
Head=new Node(str);
else
(1)
}
void append(String str) //将数据str的结点插入在整个链表尾部
{ Node tempnode=Head;
it(tempnode==null)
Heed=new Node(str);
else
{ white(tempnode.getNext()!=null)
(2)
(3) }
}
String get() //移出链表第一个结点,并返回该结点的数据域
{ Srting temp=new String();
if(Head==null)
{ System.out.println("Errow! from empty list!")
System.exit(0); }
else
{ temp=Head.getData();
(4) }
return temp;
}
}
【程序6-2】
class Stack extends List
{ void push(String str) //进栈
{ (5) }
String pop() //出栈
{ return get();}
}
正确答案:(1)Head=new Node(strHead); (2)tempnode=tempnode.getNext(); (3)tempnode.setNext(new Node(strtempnode.getNext())); (4)Head=Head.getNext(); (5)insert(str);
(1)Head=new Node(str,Head); (2)tempnode=tempnode.getNext(); (3)tempnode.setNext(new Node(str,tempnode.getNext())); (4)Head=Head.getNext(); (5)insert(str); 解析:本题考查链表和栈的基本特征在Java中的实现。
在对链表进行表头插入时,首先要判断该链表是否为空,如果为空,直接插入结点;如果非空,在插入结点时把该结点的指针域改成能指向下一个结点的地址。在队尾插入时,同样要判断该链表是否为空,如果为空,直接插入结点;如果非空,在插入结点时把上一个结点的指针域改成能指向该结点的地址。
下面来具体分析代码,首先定义了一个结点类,类中有两个不同的构造函数和三个函数,分别用于获取结点数据域,设置下一个结点值和返回下一个结点值。第(1)空是函数insert()里面的代码,函数要实现的功能是将数据str的结点插入在整个链表前面。结合整个函数看,此空处要实现的功能是在非空链表的前面插入结点,需要指针域来存放下一个结点的地址,而下一个结点的地址就是Head,因此,此处应该填Head=new Node(str,Head)。
第(2)空和第(3)空一起考虑,它们都是函数append()里面的内容。函数要实现的功能是将数据str的结点插入在整个链表尾部。这两空要实现的功能是在非空链表的尾部插入结点。这需要调用返回下一个结点值函数和设置下一个结点值函数,因此,第 (2)空和第(3)空的答案分别为tempnode=tempnode.getNext()和tempnode.setNext(new Node(str,tempnode.getNext()))。
第(4)空是函数get()里面的内容,此函数的功能是移出链表第一个结点,并返回该结点的数据域,从整个函数来看,此空处的功能是让链表的地址Head指向下一个结点。因此,答案为Head=Head.getNext()。
第(5)空就比较简单了,要实现的功能就是让数据进栈,而进栈操作是在栈顶进行插入的,因此,只要调用函数insert()即可,其参数是str,此空答案为insert(str)。 -
第16题:
以下程序的功能是:建立一个带有头结点的单向链表,并将存储在数组中的字符依次转存到链表的各个结点中,请填空。 #include <stdlib.h> stuct node { char data; struet node * next; }; stntct node * CreatList(char * s) { struet node *h,*p,*q; h = (struct node * ) malloc(sizeof(struct node) ); p=q=h; while( * s! ='\0') { p = (struct node *) malloc ( sizeof(struct node) ); p - > data = ( ) q- >next=p; q=p; a++; p- > next ='\0'; return h; } main( ) { char str[ ]= "link list"; struet node * head; head = CreatList(str);
A.*s
B.s
C.*s++
D.(*s)++
正确答案:A
解析:本题要求建立一个stmctnode类型的数据链表,函数CreatList将字符串"linklist"的首地址传给指针变量s,可以推断建立的链表一定与"linklist",有关,由CreatList(char*s)函数中所定义的变量及其他语句可知,h,p,q用于建立的链表,h表示头指针,p用于记录开辟的新结点,而q用作将新结点与已建立的链表相连的中间变量,所建立链表各个结点的data依次存放的是”linklist",中的各个字符,所以应填空*s。 -
第17题:
设链表中的结点是NODE类型的结构体变量,且有NODE*p;为了申请一个新结点,并由p指向该结点,可用以下语句()。
Ap=(NODE*)malloc(sizeof(p));
Bp=(*NODE)malloc(sizeof(NODE));
Cp=(NODE)malloc(sizeof(p));
Dp=(NODE*)malloc(sizeof(NODE));
D
略 -
第18题:
node结点
正确答案: 一个路由器或一台与网络连接的计算机使用的非正式术语,来自于图论。 -
第19题:
设有一个不带头结点的单向链表,头指针为head,结点类型为NODE,每个结点包含一个数据域data和一个指针域next,该链表有两个结点,p指向第二个结点(尾结点),按以下要求写出相应语句。已知p1指向另一个新结点,把它插入到p所指结点和尾结点之间。
正确答案: P1->next=p->next;
P->next=p1; -
第20题:
计算机网络中的结点(NODE)是指()。
- A、网络工作站
- B、在通讯线路与主机之间设置的通信线路控制处理机
- C、为延长传输距离而设立的中继站
- D、传输介质的连接点
正确答案:B -
第21题:
名词解释题node结点正确答案: 一个路由器或一台与网络连接的计算机使用的非正式术语,来自于图论。解析: 暂无解析 -
第22题:
单选题设链表中的结点是NODE类型的结构体变量,且有NODE*p;为了申请一个新结点,并由p指向该结点,可用以下语句()。Ap=(NODE*)malloc(sizeof(p));
Bp=(*NODE)malloc(sizeof(NODE));
Cp=(NODE)malloc(sizeof(p));
Dp=(NODE*)malloc(sizeof(NODE));
正确答案: D解析: 暂无解析 -
第23题:
判断题网络(network)由若干结点(node)和连接这些结点的链路(link)组成。A对
B错
正确答案: 错解析: 暂无解析