
2、某带头结点的非空单链表L中所有元素为整数,结点类型定义如下: typedef struct node { int data; struct node *next; } LinkNode; 设计一个尽可能高效的算法,将所有小于零的结点移到所有大于等于零的结点的前面。
题目
2、某带头结点的非空单链表L中所有元素为整数,结点类型定义如下: typedef struct node { int data; struct node *next; } LinkNode; 设计一个尽可能高效的算法,将所有小于零的结点移到所有大于等于零的结点的前面。
相似考题
更多“2、某带头结点的非空单链表L中所有元素为整数,结点类型定义如下: typedef struct node { int data; struct node *next; } LinkNode; 设计一个尽可能高效的算法,将所有小于零的结点移到所有大于等于零的结点的前面。”相关问题
-
第1题:
设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B、C,其中B表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零整数,要求B、C表利用A表的结点)。参考答案:
B表的头结点使用原来A表的头结点,为C表新申请一个头结点。从A表的第一个结点开始,依次取其每个结点p,判断结点p的值是否小于0,利用前插法,将小于0的结点插入B表,大于等于0的结点插入C表。
[算法描述]
void DisCompose(LinkedList A)
{ B=A;
B->next= NULL; ∥B表初始化
C=new LNode;∥为C申请结点空间
C->next=NULL; ∥C初始化为空表
p=A->next; ∥p为工作指针
while(p!= NULL)
{ r=p->next; ∥暂存p的后继
if(p->data<0)
{p->next=B->next; B->next=p; }∥将小于0的结点链入B表,前插法
else {p->next=C->next; C->next=p; }∥将大于等于0的结点链入C表,前插法
p=r;∥p指向新的待处理结点。
}
}
-
第2题:
在C语言中,可以用typedef声明新的类型名来代替已有的类型名,比如有学生链表结点: typedef struct node{ int data; struct node * link; }NODE, * LinkList; 下述说法正确的是______。
A.NODE是结构体struct node的别名
B.* LinkList也是结构体struct node的别名
C.LinkList也是结构体struct node的别名
D.LinkList等价于node*
正确答案:A
解析:其实题中的定义相当于下述两个定义:typedefstructnode{intdata;structnode*link;}NODE;typedefstructnode{intdata;structnode*link;)*LinkList;前者给structnode取了个新名字NODE,即structnode和NODE是等价的;后者把structnode*命名为LinkList。 -
第3题:
阅读以下说明和C语言函数,将应填入(n)处的字句写在对应栏内。
【说明】
函数sort (NODE *head)的功能是;用冒泡排序法对单链表中的元素进行非递减排序。对于两个相邻结点中的元素,若较小的元素在前面,则交换这两个结点中的元素值。其中,head指向链表的头结点。排序时,为了避免每趟都扫描到链表的尾结点,设置一个指针endptr,使其指向下趟扫描需要到达的最后一个结点。例如,对于图4-1(a)的链表进行一趟冒泡排序后,得到图4-1(b)所示的链表。

链表的结点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
} NODE;
【C语言函数】
void sort (NODE *head)
{ NODE *ptr,*preptr, *endptr;
int tempdata;
ptr = head -> next;
while ((1)) /*查找表尾结点*/
ptr = ptr -> next;
endptr = ptr; /*令endptr指向表尾结点*/
ptr =(2);
while(ptr != endptr) {
while((3)) {
if (ptr->data > ptr->next->data){
tempdata = ptr->data; /*交换相邻结点的数据*/
ptr->data = ptr->next->data;
ptr->next->data = tempdata;
}
preptr =(4); ptr = ptr -> next;
}
endptr =(5); ptr = head->next;
}
}
正确答案:(1)ptr -> next (2)head->next (3)ptr !=endptr或其等价形式 (4)ptr (5)preptr
(1)ptr -> next (2)head->next (3)ptr !=endptr,或其等价形式 (4)ptr (5)preptr 解析:本题考查链表运算能力。
从题目中的以下代码可知,ptr最后应指向表尾结点。
ptr = head -> next;
while((1))/*查找表尾结点*/
ptr = ptr -> next;
endptr = ptr; /*令endptr指向表尾结点*/
显然,空(1)处应填入“ptr->next”,这样循环结束时,ptr指向表尾结点。若填入“ptr”,则循环结束时,ptr为空指针。
进行冒泡排序时,从头至尾依次比较逻辑上相邻的两个结点的数据,如果小元素在前大元素在后,则交换。这样,经过一趟扫描,就将最大元素交换到了表的最后。下一趟可将次大元素交换到最大元素之前。显然,空(2)处应填入“head->next”。
由于程序设置的endptr用于指示出每趟扫描需到达的最后一个结点,ptr用于依次扫描链表中的结点,因此空(3)处的循环条件为“ptr != endptr”。
显然,指针preptr起的作用是指向ptr的前驱结点,因此,ptr每向后修改一次,相应地preptr就要修改一次,空(4)处应填入“ptr”。本趟循环结束后,下一趟扫描也就确定了,因此在空(5)处填入“preptr”。 -
第4题:
以下程序的功能是:建立一个带有头结点的甲—向链表,并将存储在数组中的字符依次转存到链表的各个结点中,请从与下划线处号码对应的一组选项中选择出正确的选项。
#include <stdlib.h>
struct node
{ char data; struct node *next: };
(1) CreatList(char *s)
{
struct node *h,*p,*q;
h = (struct node *)malloc sizeof(struct node));
p=q=h;
while(*s! ='\0')
{
p = (struct node *)malloc(sizeof (struct node));
p->data = (2) ;
q->next = p;
q - (3) ;
S++;
}
p->next='\0';
return h;
}
main()
{
char str[]="link list";
struct node *head;
head = CreatList(str);
}
(1)
A.char*
B.struct node
C.struct node*
D.char
正确答案:C
-
第5题:
阅读以下说明和C语言函数,将应填入(n)。
【说明】
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
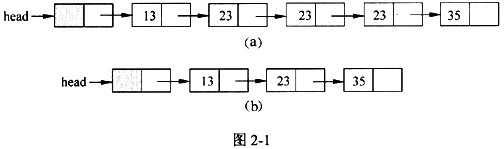
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}NODE;
【C语言函数】
void compress(NODE *head)
{ NODE *ptr,*q;
ptr= (1); /*取得第一个元素结点的指针*/
while( (2)&& ptr->next) {
q=ptr->next;
while(q&&(3)) { /*处理重复元素*/
(4)q->next;
free(q);
q=ptr->next;
}
(5) ptr->next;
}/*end of while */
}/*end of compress*/
正确答案:(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data或其等价表示 (4)ptr->next (5)ptr
(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data,或其等价表示 (4)ptr->next (5)ptr 解析:本题考查基本程序设计能力。
链表上的查找、插入和删除运算是常见的考点。本题要求去掉链表中的重复元素,使得链表中的元素互不相同,显然是对链表进行查找和删除操作。
对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以采用两种思路。
1.顺序地遍历链表,对于逻辑上相邻的两个元素,比较它们是否相同,若相同,则删除后一个元素的结点,直到表尾。代码如下:
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){ /*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data){/*处理重复元素*/
ptr->next=q->next;/*将结点从链表中删除*/
free(q);
q=ptr->next; /*继续扫描后继元素*/
}
ptr=ptr->next;
}
2.对于每一组重复元素,先找到其中的第一个结点,然后向后查找,直到出现一个相异元素时为止,此时保留重复元素的第一个结点,其余结点则从链表中删除。
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){/*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data) /*查找重复元素*/
q=q->next;
s=ptr->next; /*需要删除的第一个结点*/
ptr->next=q; /*保留重复序列的第一个结点,将其余结点从链表中删除*/
while(s && s!=q}{/*逐个释放被删除结点的空间*/
t = s->next;free(s);s = t;
}
ptr=ptr->next;
}
题目中采用的是第一种思路。 -
第6题:
以下程序中函数fun的功能是:构成—个如图所示的带头结点的单向链表,在结点的数据域中放入了具有两个字符的字符串。函数disp的功能是显示输出该单向链表中所有结点中的字符串。请填空完成函数disp。

include<stdio.h>
typedef struct node /*链表结点结构*/
{ char sub[3];
struct node *next;
}Node;
Node fun(char s) /* 建立链表*/
{ ...... }
void disp(Node *h)
{ Node *p;
p=h->next;
while([ ])
{printf("%s\n",p->sub);p=[ ];}
}
main()
{ Node *hd;
hd=fun(); disp(hd);printf("\n");
}
正确答案:p!=NULL 或 p 或 p!=0 或 p!='0' p->next 或 (*P).next
p!=NULL 或 p 或 p!=0 或 p!='0' p->next 或 (*P).next 解析:此题主要考核的是用指针处理链表。自定义结构体类型名为Node,并定义一个指向结点类型的指针next。用Node来定义头结点指针变量h,并定义另—个指针变量p指向了第—个结点,在满足p未指向最后—个结点的空指针时,输出p所指向结点的字符串,所以第—个空填p!=NULL或p或p!=0或p!='\0',然后将p指向下一个非空结点,所以第二个空填p->next或与其等效的形式,反复执行直到所有的结点都输出,即遇到p的值为NULL。 -
第7题:
下面正确定义了仅包含一个数据成员info的单链表的结点类型。struct node { int info;struct node next;} ()此题为判断题(对,错)。
正确答案:错误
-
第8题:
阅读以下说明和 C 代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 函数 GetListElemPtr(LinkList L,int i)的功能是查找含头结点单链表的第i个元素。若找到,则返回指向该结点的指针,否则返回空指针。 函数DelListElem(LinkList L,int i,ElemType *e) 的功能是删除含头结点单链表的第 i个元素结点,若成功则返回 SUCCESS ,并由参数e 带回被删除元素的值,否则返回ERROR 。 例如,某含头结点单链表 L 如图 4-1 (a) 所示,删除第 3 个元素结点后的单链表如 图 4-1 (b) 所示。
 图4-1
图4-1define SUCCESS 0 define ERROR -1 typedef int Status; typedef int ElemType; 链表的结点类型定义如下: typedef struct Node{ ElemType data; struct Node *next; }Node ,*LinkList; 【C 代码】 LinkList GetListElemPtr(LinkList L ,int i) { /* L是含头结点的单链表的头指针,在该单链表中查找第i个元素结点: 若找到,则返回该元素结点的指针,否则返回NULL */ LinkList p; int k; /*用于元素结点计数*/ if (i<1 ∣∣ !L ∣∣ !L->next) return NULL; k = 1; P = L->next; / *令p指向第1个元素所在结点*/ while (p && (1) ) { /*查找第i个元素所在结点*/ (2) ; ++k; } return p; } Status DelListElem(LinkList L ,int i ,ElemType *e) { /*在含头结点的单链表L中,删除第i个元素,并由e带回其值*/ LinkList p,q; /*令p指向第i个元素的前驱结点*/ if (i==1) (3) ; else p = GetListElemPtr(L ,i-1); if (!p ∣∣ !p->next) return ERROR; /*不存在第i个元素*/ q = (4) ; /*令q指向待删除的结点*/ p->next = q->next; /*从链表中删除结点*/ (5) ; /*通过参数e带回被删除结点的数据*/ free(q); return SUCCESS; }
正确答案:(1) k<i
(2) p = p->next
(3) p=L
(4) p->next
(5) *e = q->data
-
第9题:
试题四(共 15 分)
阅读以下说明和 C 语言函数,将应填入 (n) 处的字句写在答题纸的对应栏内。
[说明]
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图4-1(a)、(b)是经函数 compress()处理前后的链表结构示例图。
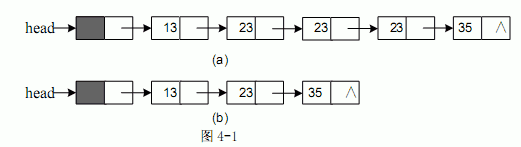
链表的结点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
}NODE;
[C 语言函数]
void compress(NODE *head)
{ NODE *ptr,*q;
ptr = (1) ; /* 取得第一个元素结点的指针 */
while ( (2) && ptr -> next) {
q = ptr -> next;
while(q && (3) ) { /* 处理重复元素 */
(4) = q -> next;
free(q);
q = ptr -> next;
}
(5) = ptr -> next;
}/* end of while */
}/* end of compress */
正确答案:
-
第10题:
阅读以下说明和C函数,填补代码中的空缺,将解答填入答题纸的对应栏内。
[说明]
函数ReverseList(LinkList headptr)的功能是将含有头结点的单链表就地逆置。处理思路是将链表中的指针逆转,即将原链表看成由两部分组成:已经完成逆置的部分和未完成逆置的部分,令s指向未逆置部分的第一个结点,并将该结点插入已完成部分的表头(头结点之后),直到全部结点的指针域都修改完成为止。
例如,某单链表如图1所示,逆置过程中指针s的变化情况如图2所示。
链表结点类型定义如下:
typedef struct Node{ int data; Struct Node *next; }Node,*LinkList; [C函数] void ReverseList(LinkList headptr) { //含头结点的单链表就地逆置,headptr为头指针 LinkList p,s; if(______) return; //空链表(仅有头结点)时无需处理 P=______; //令P指向第一个元素结点 if(!P->next) return; //链表中仅有一个元素结点时无需处理 s=p->next; //s指向第二个元素结点 ______ =NULL; //设置第一个元素结点的指针域为空 while(s){ p=s; //令p指向未处理链表的第一个结点 s= ______; p->next=headptr->next; //将p所指结点插入已完成部分的表头 headptr->next= ______; } }答案:解析:!headptr->next,或!headptr||!headptr->next,或其等价形式
headptr->next
headptr->next->next,或p->next,或其等价形式
s->next,或p->next, 或其等价形式
p -
第11题:
假定一个链表中结点的结构类型为“struct AA{int data, struct AA *next;};”,则next数据成员的类型为()。
Astruct AA
Bstruct AA*
CAA
Dint
B
略 -
第12题:
问答题设某带头结头的单链表的结点结构说明如下:typedef struct nodel{int data struct nodel*next;}node;试设计一个算法:void copy(node*headl,node*head2),将以head1为头指针的单链表复制到一个不带有头结点且以head2为头指针的单链表中。正确答案: 一边遍历,一边申请新结点,链接到head2序列中。解析: 暂无解析 -
第13题:
以下程序中函数fun的功能是:构成一个如图所示的带头结点的单词链表,在结点的数据域中放入了具有两个字符的字符串。函数disp的功能是显示输出该单链表中所有结点中的字符串。请填空完成函数disp。[*]
include<stdio.h>
typedef struct node /*链表结点结构*/
{char sub[3];
struct node *next;
}Node;
Node fun(char s) /*建立链表*/
{ … }
void disp(Node *h)
{ Node *
正确答案:
-
第14题:
函数min()的功能是:在带头结点的单链表中查找数据域中值最小的结点。请填空includestruc 函数min()的功能是:在带头结点的单链表中查找数据域中值最小的结点。请填空
include <stdio.h>
struct node
{ int data;
struct node *next;
};
int min(struct node *first)/*指针first为链表头指针*/
{ struct node *p; int m;
p=first->next; re=p->data; p=p->next;
for( ;p!=NULL;p=【 】)
if(p->data<m ) re=p->data;
return m;
}
正确答案:p->next
p->next 解析:本题考查的知识点是:链表的筛选。题目要求筛选出链表中最小的值,所以需要先定义一个临时变量,并将第1个值赋给该变量,就好像本题程序中定义的变量 m。然后遍历整个链表,拿链表中的每一个值跟m比较,如果找到比m小的值,就让m等于该值,这样遍历结束后,m中就是该链表的最小值了。题目中的空位于for循环的第3个表达式处,这里的for循环就是用来遍历整个链表的,所以该表达式需要完成的任务是:将循环变量p指向当前结点的下一个结点。故不难得知应填p->next。 -
第15题:
以下程序的功能是建立—个带有头结点的单向链表,链表结点中的数据通过键盘输入,当输入数据为-1时,表示输入结束(链表头结点的data域不放数据,表空的条件是ph->next==NULL),请填空。
include<stdio.h>
struct list { int data;struct list *next;};
struct list * creatlist()
{ struct list *p,*q,*ph;int a;ph=(struct list *)malloc(sizeof(struct
正确答案:
解析: 本题考查的是链表这一数据结构对结构体变量中数据的引用。链表的特点是结构体变量中有两个域,一个是数据,另一个是指向该结构体变量类型的指针,用以指明链表的下一个结点。 -
第16题:
以下程序把三个NODEIYPE型的变量链接成—个简单的链表,并在while循环中输出链表结点数据域中的数据。请填空。
include<stdio.h>
struct node
{ int data;struct node*next;);
typedef struct node NODETYPE;
main()
{ NODETYPEa,b,c,*h,*p;
a.data=10;b.data=20;c.data=30;h=&a;
anext=&b;b.next=&c;c,next='\0';
p=h;
while(p){printf("%d,",p->data):【 】;}
printf("\n");
}
正确答案:P++
P++ 解析:本题主要考查的是将NODETYPE型的变量链接成—个简单的链表,利用typedef把NODETYPE变成struct node的别名,当执行while循环时,首先判断是否到了最后—个链表结点,如果没有则引用结构体中的成员data,然后指向下—个链表结点,继续判断,因此,此处应填的是p++指向下—个链表结点。 -
第17题:
链表题:一个链表的结点结构
struct Node
{
int data ;
Node *next ;
};
typedef struct Node Node ;
(1)已知链表的头结点head,写一个函数把这个链表
逆序( Intel)
正确答案:
Node * ReverseList(Node *head) //链表逆序
{
if ( head == NULL || head->next == NULL )
return head;
Node *p1 = head ;
Node *p2 = p1->next ;
Node *p3 = p2->next ;
p1->next = NULL ;
while ( p3 != NULL )
{
p2->next = p1 ;
p1 = p2 ;
p2 = p3 ;
p3 = p3->next ;
}
p2->next = p1 ;
head = p2 ;
return head ;
} -
第18题:
有以下结构说明和变量定义,指针p、q、r分别指向链表中的3个连续结点。 struct node { int data;struct node*next;)*p,*q,*r; 现要将q所指结点从链表中删除,同时要保持链表的连续,以下不能按要求完成操作的语句是( )。
A.p->next=q->next;
B.P-next=P->next->next;
C.p->next=r;
D.p=q->next;
正确答案:D
本题考查链表结点的删除,q一>next中存放的是r所指结点的首地址,将r所指结点的首地址存于p--next中,则实现删除q所指点的功能,并保持链表连续,P所指点与r所指结点相连。 -
第19题:
以下程序的功能是:建立一个带有头结点的单向链表,并将存储在数组中的字符依次转存到链表的各个结点中,请填空。 #include <stdlib.h> stuct node { char data; struet node * next; }; stntct node * CreatList(char * s) { struet node *h,*p,*q; h = (struct node * ) malloc(sizeof(struct node) ); p=q=h; while( * s! ='\0') { p = (struct node *) malloc ( sizeof(struct node) ); p - > data = ( ) q- >next=p; q=p; a++; p- > next ='\0'; return h; } main( ) { char str[ ]= "link list"; struet node * head; head = CreatList(str);
A.*s
B.s
C.*s++
D.(*s)++
正确答案:A
解析:本题要求建立一个stmctnode类型的数据链表,函数CreatList将字符串"linklist"的首地址传给指针变量s,可以推断建立的链表一定与"linklist",有关,由CreatList(char*s)函数中所定义的变量及其他语句可知,h,p,q用于建立的链表,h表示头指针,p用于记录开辟的新结点,而q用作将新结点与已建立的链表相连的中间变量,所建立链表各个结点的data依次存放的是”linklist",中的各个字符,所以应填空*s。 -
第20题:
阅读以下说明和 C 函数,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 函数 Combine(LinkList La,LinkList Lb)的功能是:将元素呈递减排列的两个含头结 点单链表合并为元素值呈递增(或非递减)方式排列的单链表,并返回合并所得单链表 的头指针。例如,元素递减排列的单链表 La 和 Lb 如图 4-1 所示,合并所得的单链表如图 4-2 所示。
 图 4-1 合并前的两个链表示意图
图 4-1 合并前的两个链表示意图 图 4-2 合并后所得链表示意图
图 4-2 合并后所得链表示意图设链表结点类型定义如下: typedef struct Node{ int data; struct Node *next; }Node ,*LinkList; 【C 函数】 LinkList Combine(LinkList La ,LinkList Lb) { //La 和 Lb 为含头结点且元素呈递减排列的单链表的头指针 //函数返回值是将 La 和 Lb 合并所得单链表的头指针 //且合并所得链表的元素值呈递增(或非递减)方式排列 (1) Lc ,tp ,pa ,pb;; //Lc 为结果链表的头指针 ,其他为临时指针 if (!La) return NULL; pa = La->next; //pa 指向 La 链表的第一个元素结点 if (!La) return NULL; pa = La->next; //pb 指向 Lb 链表的第一个元素结点 Lc = La; //取 La 链表的头结点为合并所得链表的头结点 Lc->next = NULL; while ( (2) ){ //pa 和 pb 所指结点均存在(即两个链表都没有到达表尾) //令tp指向 pa 和 pb 所指结点中的较大者 if (pa->data > pb->data) { tp = pa; pa = pa->next; } else{ tp = pb; pb = pb->next; } (3) = Lc->next; //tp 所指结点插入 Lc 链表的头结点之后 Lc->next = (4) ; } tp = (pa)? pa : pb; //设置 tp 为剩余结点所形成链表的头指针 //将剩余的结点合并入结果链表中, pa 作为临时指针使用 while (tp) { pa = tp->next; tp->next = Lc->next; Lc->next = tp; (5) ; } return Lc; }
正确答案:(1) LinkList
(2) pa&&pb
(3) tp->next
(4) tp
(5) tp=pa
-
第21题:
阅读以下说明和C代码,填补代码中的空缺,将解答填入答题纸的对应栏内。
[说明]
函数GetListElemPtr(LinkList L,int i)的功能是查找含头结点单链表的第i个元素。若找到,则返回指向该结点的指针,否则返回空指针。
函数DelListElem(LinkList L,int i,ElemType *e)的功能是删除含头结点单链表的第i个元素结点,若成功则返回SUCCESS,并由参数e带回被删除元素的值,否则返回ERROR。
例如,某含头结点单链表L如下图(a)所示,删除第3个元素结点后的单链表如下图(b)所示。
1.jpg
#define SUCCESS 0 #define ERROR -1 typedef intStatus; typedef intElemType;
链表的结点类型定义如下:
typedef struct Node{ ElemType data; struct Node *next; }Node,*LinkList; [C代码] LinkListGetListElemPtr(LinkList L,int i) { /*L是含头结点的单链表的头指针,在该单链表中查找第i个元素结点; 若找到,则返回该元素结点的指针,否则返回NULL */ LinkList p; int k; /*用于元素结点计数*/ if(i<1 || !L || !L->next) return NULL; k=1; p=L->next; /*令p指向第1个元素所在结点*/ while(p &&______){ /*查找第i个元素所在结点*/ ______; ++k; } return p; } StatusDelListElem(LinkList L,int i,ElemType *e) { /*在含头结点的单链表L中,删除第i个元素,并由e带回其值*/ LinkList p,q; /*令P指向第i个元素的前驱结点*/ if(i==1) ______; else p=GetListElemPtr(L,i-1); if(!P || !p->next) return ERROR; /*不存在第i个元素*/ q=______; /*令q指向待删除的结点*/ p->next=q->next; //从链表中删除结点*/ ______; /*通过参数e带回被删除结点的数据*/ free(q); return SUCCESS; }答案:解析:k<i
p=p->next
p=L
p->next
*e=q->data
【解析】
本题考查C语言的指针应用和运算逻辑。
本问题的图和代码中的注释可提供完成操作的主要信息,在充分理解链表概念的基础上填充空缺的代码。
函数GetListElemPtr(LinkList L,int i)的功能是在L为头指针的链表中查找第i个元素,若找到,则返回指向该结点的指针,否则返回空指针。描述查找过程的代码如下,其中k用于对元素结点进行计数。
k=1; p=L->next; /*令p指向第1个元素所在结点*/
-
第22题:
阅读以下说明和C函数,填补代码中的空缺,将解答填入答题纸的对应栏内。
[说明]
函数Combine(LinkList La,LinkList Lb)的功能是:将元素呈递减排列的两个含头结点单链表合并为元素值呈递增(或非递减)方式排列的单链表,并返回合并所得单链表的头指针。例如,元素递减排列的单链表La和Lb如图1所示,合并所得的单链表如图2所示。
设链表结点类型定义如下:
typedef Struct Node{ int data; struct Node*next; }Node,*LinkList; [C函数] LinkListCombine(LinkList La,LinkList Lb) { //La和Lb为含头结点且元素呈递减排列的单链表的头指针 //函数返回值是将La和Lb合并所得单链表的头指针 //且合并所得链表的元素值呈递增(或非递减)方式排列 ______Lc,tp,pa,pb; //Lc为结果链表的头指针,其他为临时指针 if(!La)returnNULL; pa=La->next; //pa指向La链表的第一个元素结点 if(!Lb) returnNULL; pb=Lb->next; //pb指向Lb链表的第一个元素结点 Lc=La; //取La链表的头结点为合并所得链表的头结点 Lc->next=NULL; while(______) { //pa和pb所指结点均存在(即两个链表都没有到达表尾) //令tp指向pa和pb所指结点中的较大者 if(pa->data>pb->data){ tp=pa; pa=pa->next; } else{ tp=pb; pb=pb->next; } ______ =Lc->next; //tp所指结点插入Lc链表的头结点之后 Lc->next=______; } tp=(pa)?pa:pb; //设置tp为剩余结点所形成链表的头指针 //将剩余的结点合并入结果链表中,pa作为临时指针使用 while (tp) { pa=tp->next; tp->next=Lc->next; Lc->next=tp; ______; } return Lc; }答案:解析:LinkList
pa&&pb
tp->next
tp
tp=pa
【解析】
本题考查数据结构应用及C语言实现。链表运算是C程序设计题中常见的考点,需熟练掌握。考生需认真阅读题目中的说明,以便理解问题并确定代码的运算逻辑,在阅读代码时,还需注意各变量的作用。 -
第23题:
问答题下列给定程序是建立一个带头结点的单向链表,并用随机函数为各结点赋值。函数fun()的功能是:将单向链表结点(不包括头结点)数据域为偶数的值累加起来,并作为函数值返回。 请改正函数fun中的错误,使它能得出正确的结果。 注意:部分源程序在文件MODII.C中,不要改动main函数,不得增行或删行,也不得更改程序的结构! 试题程序:#include#include #include typedef struct aa{ int data; struct aa *next;}NODE;int fun(NODE *h){ int sum=0; NODE *p; p=h->next; /*********found*********/ while(p->next) { if(p->data%2==0) sum+=p->data; /*********found*********/ p=h->next; } return sum;}NODE *creatlink(int n){ NODE *h,*p,*s; int i; h=p=(NODE *)malloc(sizeof(NODE)); for(i=1;i 正确答案:
(1)错误:while(p->next)
正确:while(p)或while(p!=NULL)
(2)错误:p=h->next;
正确:p= p ->next;解析:
错误1:执行p=p->next后,p指针已经指向链表第一个包含数据域的结点。fun函数的while循环判断当前指针p指向的结点是否存在,若存在则对该结点数据域进行判断操作,而不是判断p指针的指针域是否为空。
错误2:fun函数的while循环中判断结束后指针指向下一个结点,操作为p=p->next。 -
第24题:
填空题设线性链表的存储结构如下: struct node {ELEMTP data; /*数据域*/ struct node *next; /*指针域*/ } 试完成下列在链表中值为x的结点前插入一个值为y的新结点。如果x值不存在,则把新结点插在表尾的算法。 void inserty(struct node *head,ELEMTP x,ELEMTP y) {s=(struct node *)malloc(sizeof(struct node)); (); if(){s->nexr=head;head=s;} else { q=head;p=q->next; while(p->dqta!=x&&p->next!=NULL){q=p;()} if(p->data= = x){q->next=s;s->next=p;} else{p->next=s;s->next=NULL;} } }正确答案: s->data=y,head->data= =x,p=p->next解析: 暂无解析