
在静态散列中,如果我们插入一条记录,而桶没有足够的空间,就会发生( )。A.桶分裂B.数据丢失C.桶合并D.桶溢出
题目
A.桶分裂
B.数据丢失
C.桶合并
D.桶溢出
相似考题
参考答案和解析
更多“在静态散列中,如果我们插入一条记录,而桶没有足够的空间,就会发生( )。 ”相关问题
-
第1题:
散列是一种快速查找的技术,以下关于散列说法错误的是______。
A.文件可以组织为散列文件
B.散列函数的输入为文件记录的查找码值
C.散列函数的输出可以是桶号
D.桶可以是磁盘块,但不可以是比磁盘块大的空间
正确答案:D
解析:桶可以是磁盘块,也可以是比磁盘块大的空间。 -
第2题:
散列文件组织将文件的物理空间划分为一系列的桶,每个桶的空间大小是固定的,可以容纳的文件记录也是固定的,如果某个桶内已经装满记录.又有新的记录插入就会产生桶溢出,产生桶溢出的2个主要原因为 (12) 和 (13) 。
12.
正确答案:文件初始设计时为文件记录预留存储空间不足预留的桶数过少
文件初始设计时,为文件记录预留存储空间不足,预留的桶数过少 -
第3题:
阅读以下函数说明、图和C代码,将应填入(n)处的字句写在对应栏内。
【说明】
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如:设散列函数为Hash(Key)=Key mod 7,记录的关键字序列为15,14,21,87,96, 293,35,24,149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图5-3所示。
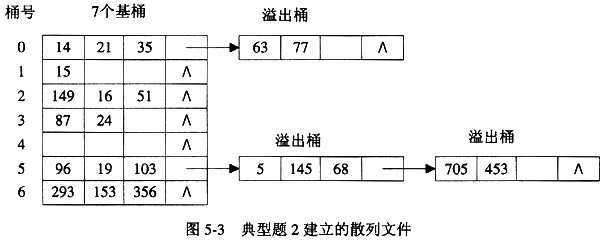
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是;若新元素NewElemKey正确插入散列文件中,则返回值1;否则返回值0。
采用的散列函数为Hash(NewElemKey)=NewElemKey % P,其中P为设定的基桶数目。
函数中使用的预定义符号如下:
define NULLKEY-1 /*散列桶的空闲单元标识*/
define P 7 /*散列文件中基桶的数目*/
define ITEMS 3 /*基桶和溢出桶的容量*/
typedef struet BucketNode{ /*基桶和溢出桶的类型定义*/
int KeyData[ITEMS];
struct BucketNode *Link;
}BUCKET;
BUCKET Bucket[P]; /*基桶空间定义*/
【函数5-3】
int InsertToHashTable(int NewElemKey){
/*将元素NewElemKey插入散列桶中,若插入成功则返回0,否则返回-1*/
/*设插入第一个元素前基桶的所有KeyData[],Link域已分别初始化为NULLKEY、NULL*/
int Index; /*基桶编号*/
int i,k'
BUCKET *s,*front,*t;
(1);
for(i=0;i<ITEMS;i++) /*在基桶查找空闲单元,若找到则将元素存入*/
if(Bucket[Index].KeyData[i]==NULLKEY){
Bucket[Index].KeyData[i]=NewElemKey;
break;
}
if((2))return 0;
/* 若基桶已满,则在溢出桶中查找空闲单元,若找不到则申请新的溢出桶*/
(3);
t=Bucket[Index].Link;
if(t!=NULL){ /*有溢出桶*/
while(t!=NULL){
for(k=0;k<ITEMS;k++)
if(t->KeyData[k]==NULLKEY){/* 在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey;
break;
}/*if*/
front=t;
if((4))t=t->Link;
else break;
}/*while*/
}/*if*/
if((5)){ /* 申请新溢出桶并将元素存入*/
s=(BUCKET *)malloc(sizeof(BUCKET));
if(!s)retum -1;
s->Link=NULL;
for(k=0;k<ITEMS;k++)
s->KeyData[k]=NULLKEY;
s->KeyData[0]=NewElemKey;
(6);
}/*if*/
return 0;
}/*InsertToHashTable*/
正确答案:(1) Index=Hash(NewElemKey)或Index=NewElemKey%P (2) iITEMS (3) front=&Bucket[Index]或front=Bucket+Index (4) k==ITEMS或k>=ITEMS (5) t==NULL (6) front->Link=s
(1) Index=Hash(NewElemKey),或Index=NewElemKey%P (2) iITEMS (3) front=&Bucket[Index],或front=Bucket+Index (4) k==ITEMS,或k>=ITEMS (5) t==NULL (6) front->Link=s 解析:本题考查链式存储的插入算法。
根据题意,空(1)比较简单,应为计算散列值,并将关键字NewElemKey对应的散列值赋给表示基桶编号的变量Index,故空(1)应填Index=Hash(NewElemKey)。
接下来进行插入操作,分3种情况进行处理:基桶未满、基桶已满但溢出桶未满、基桶和溢出桶(若有)都已满。基桶未满时,直接将关键字插入到基桶中即可;若基桶已满但溢出桶未满,则找到未满的溢出桶,将关键字插入;若基桶和溢出桶(若有)均已满,则新建溢出桶,并将关键字插入到新建的溢出桶中。
空(1)之后的for语句在基桶中查找空闲单元,若找到则进行插入,如条件空(2)成立,返回0,表示插入成功,可见空(2)表示基桶未满,关键字已经成功插入。故空(2)应填iITEMS。注意break语句,若基桶只剩最后一个单元,即i=ITEMS-1时才进行插入操作,由于有break语句,跳出for循环后,i值仍为ITEMS-1,而不会被加1。所以填成i=ITEMS是错误的。
接着处理基桶已满的情况。空(3)应该是某个变量的初始化,不过暂时无法确定。
首先处理有溢出桶的情况。既然基桶已满,就只能在溢出桶中查找空闲单元,若找到则进行插入。注意赋值语句“front=t”。空(4)条件成立时继续查找下一个溢出桶,即表示当前溢出桶中已经没有空闲单元了,因此空(4)应填k==ITEMS。这样结束while循环对应两种情况:已经成功插入(对应t不为NULL,front不确定)和所有溢出桶都没有空闲单元(对应 t为NULL,front指向最后一个溢出桶)。
接着处理基桶和溢出桶(若有)均已满的情况,此时需要新建溢出桶。空(5)即为“基桶和溢出桶(若有)均已满”对应的条件,此处有个特例,基桶已满但没有溢出桶,此时对应 t==NULL。根据上面的分析并结合特例可得空(5)应该为t==NULL。新建溢出桶并将关键字插入后,还需要将溢出桶链接到正确位置。故空(6)应填front->link=s。
注意,对于特例(基桶己满但没有溢出桶,对应t==NULL),front并未赋值,此时front应该指向相应的基桶。由此可得空(3)应填front=&Bucket[Index]。 -
第4题:
阅读下列函数说明、图和C代码,将应填入(n)处的字句。
[说明]
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有 m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如:设散列函数为Hash(Key)=Key mod 7,记录的关键字序列为15,14,21,87,97,293,35,24,149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图4-1所示。
[图4-1]
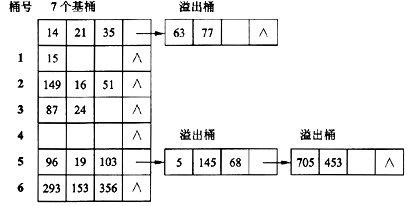
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是:将元素NewEIemKey插入散列桶中,若插入成功则返回0,否则返回-1。
采用的散列函数为Hash(NewElemKey)=NewElemKey % P,其中P为设定的基桶数目。
函数中使用的预定义符号如下:
define NULLKEY -1 /*散列桶的空闲单元标识*/
define P 7 /*散列文件中基桶的数目*/
define ITEMS 3 /*基桶和溢出桶的容量*/
typedef struct BucketNode{ /*基桶和溢出桶的类型定义*/
int KcyData[ITEMS];
struct BucketNode *Link;
}BUCKET;
BUCKET Bucket[P]; /*基桶空间定义*/
[函数]
int lnsertToHashTable(int NewElemKey){
/*将元素NewElemKey插入散列桶中,若插入成功则返回0,否则返回-1*/
/*设插入第一个元素前基桶的所有KeyData[]、Link域已分别初始化为NULLKEY、
NULL*/
int Index; /*基桶编号*/
int i,k;
BUCKET *s,*front,*t;
(1) ;
for(i=0; i<ITEMS;i++)/*在基桶查找空闲单元,若找到则将元素存入*/
if(Bucket[Index].KeyData[i]=NULLKEY){
Bucket[Index].KeyData[i]=NewElemKey; break;
}
if( (2) ) return 0;
/*若基桶已满,则在溢出桶中查找空闲单元,若找不到则申请新的溢出桶*/
(3) ; t=Bucket[Index].Link;
if(t!=NULL) {/*有溢出桶*/
while (t!=NULL){
for(k=0; k<ITEMS; k++)
if(t->KeyData[k]=NULLKEY){/*在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey; break;
}/*if*/
front=t;
if( (4) )t=t->Link;
else break;
}/*while*/
}/*if*/
if( (5) ) {/*申请新溢出桶并将元素存入*/
s=(BUCKET*)malloe(sizeof(BUCKET));
if(!s) return-1;
s->Link=NULL;
for(k=0; k<ITEMS; k++)
s->KeyData[k]=NULLKEY;
s->KeyData[0]=NewElemKey;
(6) ;
}/*if*/
return 0;
}/*InsertToHashTable*/
正确答案:(1) Index=NewElemKey % P (2) iITEMS (3) front=&Bucket[Index] (4) k==ITEMS (5) t==NULL或!t (6) front->Link=s
(1) Index=NewElemKey % P (2) iITEMS (3) front=&Bucket[Index] (4) k==ITEMS (5) t==NULL,或!t (6) front->Link=s 解析:本题考查元素的散列存储。
元素作散列存储时,首先用设定的散列函数计算元素的存储位置。在本题中,将元素存储在预先设定的基桶或根据需要申请的溢出桶中,只要基桶中有空闲单元,就将新元素NewElemKey插入在基桶中,若基桶中无空闲单元,则看是否存在溢出桶,若存在,则在溢出桶中查找空闲单元,若不存在溢出桶或溢出桶中无空闲单元,则申请一个溢出桶并存入新元素。
在基桶查找空闲单元时使用的桶号为Index,可知空(1)处应填入“Index= NewElemKey % P”。显然,一旦在基桶中找到空闲单元,即“Bucket[Index].KeyData[i]== NULLKEY”(0≤iITEMS),则可将元素NewElemKey放入Bucket[Index].KeyData[i],至此元素已经插入散列桶中,函数可返回,因此空(2)处应填入“iITEMS”;反之,若在基桶中没有找到空闲单元,则需查找溢出桶。“t=Bucket[Index].Link”,指针t首先指向桶号Index的第一个溢出桶。下面的代码即为在溢出桶中查找空闲单元。
if(t!=NULL){/*有溢出桶*/
while(t!=NULL){
for(k=0; kITEMS;k++)
if(t->KeyData[k]==NULLKEY){/*在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey; break;
}/*if*/
front=t;
if((4))t=t->Link;
else break;
}/*while*/
}/*if*/
由于每个溢出桶都可以存储ITEMS个元素,所以在溢出桶中查找空闲单元与在基桶中的查找过程相同,代码如下。
for(k=0;kITEMS;k++)
if(t->KcyData[k]==NULLKEY){/*在溢出桶链表中找到空闲单元*/
t->KeyData[k]=NewElemKey;break;
}/*if*/
若在指针t指向的溢出桶中找到空闲单元则插入元素,否则,由“t=t->Link”得到下一个溢出桶的指针,因此“kITEMS”可作为是否在当前溢出桶中找到空闲单元的判定条件。
显然,在桶号Index的基桶和其所有溢出桶都已满的情况下,t的值为空指针。此时才需要申请新的溢出桶并建立链接关系,因此在上面查找溢出桶中空闲单元时,进行指针t的后移“t=t->Link”前应先用front记录t的值,以便于后面建立链接关系。所以空(3)处应给front置初值,即“front=&Bucket[Index]”,空(4)填入“k==ITEMS”,空(5)填入“t=NULL”。空(6)处建立新申请溢出桶的链接关系“front->Link=s”。 -
第5题:
阅读以下函数说明、图和C程序代码,将C程序段中(1)~(6)空缺处的语句填写完整。
[说明]
散列文件的存储单位称为桶(BUCKET)。假如一个桶能存放m个记录,当桶中已有m个同义词(散列函数值相同)的记录时,存放第m+1个同义词会发生“溢出”。此时需要将第m+1个同义词存放到另一个称为“溢出桶”的桶中。相对地,称存放前m个同义词的桶为“基桶”。溢出桶和基桶大小相同,用指针链接。查找指定元素记录时,首先在基桶中查找。若找到,则成功返回,否则沿指针到溢出桶中进行查找。
例如,设散列函数为Hash(Key)=Key mod7,记录的关键字序列为15,14,21,87,96,293,35,24, 149,19,63,16,103,77,5,153,145,356,51,68,705,453,建立的散列文件内容如图2-27所示。
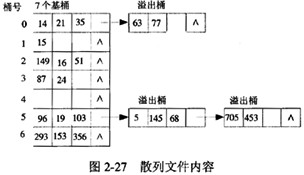
为简化起见,散列文件的存储单位以内存单元表示。
函数InsertToHashTable(int NewElemKey)的功能是:若新元素NewElemKey正确插入散列文件中,则返回值0;否则返回值-1。
采用的散列函数为Hash(NewElemKey)=NewElemKey%P,其中P设定基桶的数目。
函数中使用的预定义符号如下。
 正确答案:这是一道要求读者掌握如何在散列文件中插入一个新的数据元素的编程题。本题的解答思路如下。 在散列文件中插入一个新的数据元素的基本思路是首先将要插入的元素代入到散列函数中从而计算出该元素的散列地址。然后按照散列地址在基桶中查找空闲单元若找到则将元素插入若基桶已满则在溢出桶中查找空闲单元。若溢出桶中也查找不到则申请新的溢出桶然后将元素存入。 在散列文件中查找一个元素的基本思路是查找指定元素记录时首先在基桶中查找若找到则成功返回否则沿指针到溢出桶中进行查找。 在本试题中将元素存储在预先设定的基桶或根据需要申请的溢出桶中只要基桶中有空闲单元就将新元素NewElemkey插入在基桶中若基桶中无空闲单元则看是否存在溢出桶若存在则在溢出桶中查找空闲单元若不存在溢出桶或溢出桶中无空闲单元则申请一个溢出桶并存入新元素。 在基桶查找空闲单元时使用的桶号为Index由此可知(1)空缺处所填写的内容是“Index=NewElemKey%P”或“Index=Hash(NewElemKey)”等其他等价形式。 一旦在基桶中找到空闲单元即“Bucket[1ndex].keyData[i]==NULLKEY”(0≤iITEMS)则可将元素NewElemkey放入Bucket[Index].keyData[i]至此元素已经插入散列桶中函数可返回因此(2)空缺处所填写的内容是“iITEMS”。反之 若在基桶中没有找到空闲单元则需查找溢出桶。“t=Bucket[Index].Link”指针t首先指向桶号Index的第一个溢出桶。以下的代码完成在溢出桶中查找空闲单元的功能。
正确答案:这是一道要求读者掌握如何在散列文件中插入一个新的数据元素的编程题。本题的解答思路如下。 在散列文件中插入一个新的数据元素的基本思路是首先将要插入的元素代入到散列函数中从而计算出该元素的散列地址。然后按照散列地址在基桶中查找空闲单元若找到则将元素插入若基桶已满则在溢出桶中查找空闲单元。若溢出桶中也查找不到则申请新的溢出桶然后将元素存入。 在散列文件中查找一个元素的基本思路是查找指定元素记录时首先在基桶中查找若找到则成功返回否则沿指针到溢出桶中进行查找。 在本试题中将元素存储在预先设定的基桶或根据需要申请的溢出桶中只要基桶中有空闲单元就将新元素NewElemkey插入在基桶中若基桶中无空闲单元则看是否存在溢出桶若存在则在溢出桶中查找空闲单元若不存在溢出桶或溢出桶中无空闲单元则申请一个溢出桶并存入新元素。 在基桶查找空闲单元时使用的桶号为Index由此可知(1)空缺处所填写的内容是“Index=NewElemKey%P”或“Index=Hash(NewElemKey)”等其他等价形式。 一旦在基桶中找到空闲单元即“Bucket[1ndex].keyData[i]==NULLKEY”(0≤iITEMS)则可将元素NewElemkey放入Bucket[Index].keyData[i]至此元素已经插入散列桶中函数可返回因此(2)空缺处所填写的内容是“iITEMS”。反之 若在基桶中没有找到空闲单元则需查找溢出桶。“t=Bucket[Index].Link”指针t首先指向桶号Index的第一个溢出桶。以下的代码完成在溢出桶中查找空闲单元的功能。 由于每个溢出桶都可以存储ITEMS个元素因此在溢出桶中查找空闲单元与在基桶中的查找过程相同代码如下。
由于每个溢出桶都可以存储ITEMS个元素因此在溢出桶中查找空闲单元与在基桶中的查找过程相同代码如下。
 若在指针t指向的溢出桶中找到空闲单元则插入元素否则由“t=t->Link”得到下一个溢出桶的指针因此“kITEMS”可作为是否在当前溢出桶中找到空闲单元的判定条件。显然在桶号Index的基桶和其所有溢出桶都已满的情况下t的值为空指针。此时才需要申请新的溢出桶并建立链接关系因此在上面查找溢出桶中空闲单元时进行指针t的后移“t=t->Link'’前应先用front记录t的值以便于后面建立链接关系。所以(3)空缺处应给front置初值即所填写的内容是“front=&Bucket[Index]”或“front=Bucket+Index”等其他等价形式。
(4)空缺处用于判断该溢出桶是否已满即所填写的内容是“k=ITEMS(或k>=ITEMS)”。如果该溢出桶已满则继续查找下一个溢出桶直到查找到空闲单元为止。
若所有溢出桶都不存在空闲单元(即t==NULL)则申请新的溢出桶并将新的溢出桶的首地址保存在原有的最后一个溢出桶的Link域中(即front->Link=s)。因此(5)空缺处所填写的内容是“t==NULL” (6)空缺处用于建立新申请溢出桶的链接关系——“front->Link=s”。
若在指针t指向的溢出桶中找到空闲单元则插入元素否则由“t=t->Link”得到下一个溢出桶的指针因此“kITEMS”可作为是否在当前溢出桶中找到空闲单元的判定条件。显然在桶号Index的基桶和其所有溢出桶都已满的情况下t的值为空指针。此时才需要申请新的溢出桶并建立链接关系因此在上面查找溢出桶中空闲单元时进行指针t的后移“t=t->Link'’前应先用front记录t的值以便于后面建立链接关系。所以(3)空缺处应给front置初值即所填写的内容是“front=&Bucket[Index]”或“front=Bucket+Index”等其他等价形式。
(4)空缺处用于判断该溢出桶是否已满即所填写的内容是“k=ITEMS(或k>=ITEMS)”。如果该溢出桶已满则继续查找下一个溢出桶直到查找到空闲单元为止。
若所有溢出桶都不存在空闲单元(即t==NULL)则申请新的溢出桶并将新的溢出桶的首地址保存在原有的最后一个溢出桶的Link域中(即front->Link=s)。因此(5)空缺处所填写的内容是“t==NULL” (6)空缺处用于建立新申请溢出桶的链接关系——“front->Link=s”。
这是一道要求读者掌握如何在散列文件中插入一个新的数据元素的编程题。本题的解答思路如下。 在散列文件中插入一个新的数据元素的基本思路是,首先将要插入的元素代入到散列函数中,从而计算出该元素的散列地址。然后按照散列地址,在基桶中查找空闲单元,若找到,则将元素插入,若基桶已满,则在溢出桶中查找空闲单元。若溢出桶中也查找不到,则申请新的溢出桶,然后将元素存入。 在散列文件中查找一个元素的基本思路是,查找指定元素记录时,首先在基桶中查找,若找到,则成功返回,否则沿指针到溢出桶中进行查找。 在本试题中,将元素存储在预先设定的基桶或根据需要申请的溢出桶中,只要基桶中有空闲单元,就将新元素NewElemkey插入在基桶中,若基桶中无空闲单元,则看是否存在溢出桶,若存在,则在溢出桶中查找空闲单元,若不存在溢出桶或溢出桶中无空闲单元,则申请一个溢出桶并存入新元素。 在基桶查找空闲单元时,使用的桶号为Index,由此可知(1)空缺处所填写的内容是“Index=NewElemKey%P”,或“Index=Hash(NewElemKey)”等其他等价形式。 一旦在基桶中找到空闲单元,即“Bucket[1ndex].keyData[i]==NULLKEY”(0≤iITEMS),则可将元素NewElemkey放入Bucket[Index].keyData[i],至此元素已经插入散列桶中,函数可返回,因此(2)空缺处所填写的内容是“iITEMS”。反之, 若在基桶中没有找到空闲单元,则需查找溢出桶。“t=Bucket[Index].Link”,指针t首先指向桶号Index的第一个溢出桶。以下的代码完成在溢出桶中查找空闲单元的功能。
由于每个溢出桶都可以存储ITEMS个元素,因此在溢出桶中查找空闲单元与在基桶中的查找过程相同,代码如下。
若在指针t指向的溢出桶中找到空闲单元则插入元素,否则,由“t=t->Link”得到下一个溢出桶的指针,因此“kITEMS”可作为是否在当前溢出桶中找到空闲单元的判定条件。显然,在桶号Index的基桶和其所有溢出桶都已满的情况下,t的值为空指针。此时才需要申请新的溢出桶并建立链接关系,因此在上面查找溢出桶中空闲单元时,进行指针t的后移“t=t->Link'’前应先用front记录t的值,以便于后面建立链接关系。所以(3)空缺处应给front置初值,即所填写的内容是“front=&Bucket[Index]”,或“front=Bucket+Index”等其他等价形式。
(4)空缺处用于判断该溢出桶是否已满,即所填写的内容是“k=ITEMS(或k>=ITEMS)”。如果该溢出桶已满,则继续查找下一个溢出桶,直到查找到空闲单元为止。
若所有溢出桶都不存在空闲单元(即t==NULL),则申请新的溢出桶,并将新的溢出桶的首地址保存在原有的最后一个溢出桶的Link域中(即front->Link=s)。因此(5)空缺处所填写的内容是“t==NULL”, (6)空缺处用于建立新申请溢出桶的链接关系——“front->Link=s”。