
假如我们使用 Lasso 回归来拟合数据集,该数据集输入特征有 100 个(X1,X2,...,X100)。现在,我们把其中一个特征值扩大 10 倍(例如是特征 X1),然后用相同的正则化参数对 Lasso 回归进行修正。 那么,下列说法正确的是?A.特征 X1 很可能被排除在模型之外B.特征 X1 很可能还包含在模型之中C.无法确定特征 X1 是否被舍弃D.都不对
题目
假如我们使用 Lasso 回归来拟合数据集,该数据集输入特征有 100 个(X1,X2,...,X100)。现在,我们把其中一个特征值扩大 10 倍(例如是特征 X1),然后用相同的正则化参数对 Lasso 回归进行修正。 那么,下列说法正确的是?
A.特征 X1 很可能被排除在模型之外
B.特征 X1 很可能还包含在模型之中
C.无法确定特征 X1 是否被舍弃
D.都不对
相似考题
更多“假如我们使用 Lasso 回归来拟合数据集,该数据集输入特征有 100 个(X1,X2,...,X100)。现在,我们把其中一个特征值扩大 10 倍(例如是特征 X1),然后用相同的正则化参数对 Lasso 回归进行修正。 那么,下列说法正确的是?”相关问题
-
第1题:
设数据x1,x2的绝对误差限分别为0.05和0.005,那么两数的乘积x1x2的绝对误差限E(x1x2)=
A、0.005|X2|+0.005|X1|
B、0.05|X2|+0.005|X1|
C、0.05|X1|+0.005|X2|
D、0.005|X1|+0.005|X2|
参考答案:B
-
第2题:
我们想要减少数据集中的特征数,即降维.选择以下适合的方案:( )A.使用前向特征选择方法
B.使用后向特征排除方法
C.我们先把所有特征都使用,去训练一个模型,得到测试集上的表现.然后我们去掉一个特征,再去训练,用交叉验证看看测试集上的表现.如果表现比原来还要好,我们可以去除这个特征.
D.查看相关性表,去除相关性最高的一些特征
答案:ABCD
-
第3题:
已知样本x1,x2,…,xn,其中μ未知。下列表达式中,不是统计量的是()。
A. X1 +X2 B. max(x1,x2,…,xn)
C. X1 +X2 -2μ D. (X1 -μ)/σ
E. X1 +μ答案:C,D,E解析:不含未知参数的样本函数称为统计量。CDE三项都含有未知数μ,不是统计量。 -
第4题:
二次型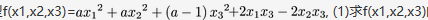 , (1)求f(x1,x2,x3)的矩阵的特征值. (2)设f(x1,x2,x3)的规范形为
, (1)求f(x1,x2,x3)的矩阵的特征值. (2)设f(x1,x2,x3)的规范形为 . 求a答案:解析:
. 求a答案:解析:
-
第5题:
响应变量Y与两个自变量(原始数据)X1及X2建立的回归方程为y=2.2+30000x1+0.0003x2由此方程可以得到的结论是:()
- A、X1对Y的影响比X2对Y的影响要显著得多
- B、X1对Y的影响与X2对Y的影响相同
- C、X2对Y的影响比X1对Y的影响要显著得多
- D、仅由此方程不能对X1及X2对Y的影响大小做出判断
正确答案:D -
第6题:
我们把一个程序在一个数据集上的一次执行称为一个()
正确答案:进程 -
第7题:
设事故树的最小径集为{X1,X4}、{X1,X2,X5,X6}、{X2,X3,X4},求事故树的最小割集。
正确答案: T=(X1+X4)(X1+X2+X5+X6)(X2+X3+X4)=X1X2+X1X3+X1X4+X2X4+X4X5+X4X6
最小径集:{X1,X2},{X1,X3},{X1,X4},{X2,X4},{X4,X5},{X4,X6} -
第8题:
以下关于回归的说法中,不正确的是()。
- A、回归是一种预测建模任务
- B、回归的目标属性是离散的
- C、回归是根据历史数据拟合以函数将属性集映射到相应的值集
- D、回归也是一种分类
正确答案:B -
第9题:
设X1,X2,…,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,…,Xn),不依赖于任何未知参数,则函数T(X1,X2,…,Xn)是一个()
正确答案:统计量 -
第10题:
单选题以下关于回归的说法中,不正确的是()。A回归是一种预测建模任务
B回归的目标属性是离散的
C回归是根据历史数据拟合以函数将属性集映射到相应的值集
D回归也是一种分类
正确答案: D解析: 暂无解析 -
第11题:
问答题设某客观现象可用X=(x1,x2,x3)′来描述,在因子分析时,从约相关阵出发计算出特征值为λ1=1.754,λ2=1,λ3=0.255,由于(λ1+λ2)/(λ1+λ2+λ3)≥85%,所以找前两个特征值所对应的公共因子即可,又知λ1,λ2对应的正则化特征向量分别为(0.707,-0.316,0.632)’及(0,0.899,0.4470)’,要求:计算第一公因子对X 的“贡献”。正确答案: 因为是从约相关阵计算的特征值,所以公共因子对X的“贡献”为g12=λ1=1.754.解析: 暂无解析 -
第12题:
单选题响应变量Y与两个自变量(原始数据)X1及X2建立的回归方程为:Y=2.1X1+2.3X2,由此方程可以得到结论是()AX1对Y的影响比X2对Y的影响要显著得多
BX1对Y的影响比X2对Y的影响相同
CX2对Y的影响比X1对Y的影响要显著得多
D仅由此方程不能对X1及X2对Y影响大小作出判定
正确答案: C解析: 暂无解析 -
第13题:
某故障树割集有5个,分别为{X1,X2,X3},{X1,X2,X4},{X1,X4},{ X2,X4},{ X2,X3 },该故障树的最小割集数个数有( )。A.2
B.3
C.4
D.5
答案:B
-
第14题:
设X1,X2,…,Xn是一个样本,样本的观测值分别为x1,x2,…,xn,则样本方差s2的计算公式正确的有( )。
 正确答案:ACD
正确答案:ACD
解析: -
第15题:
设某元件的使用寿命X的概率密度为f(x;θ)=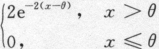 ,其中θ>0为未知参数,又设(x1,x2,…,xn)是样本(X1,X2,…,Xn)的观察值,求参数θ的最大似然估计值.答案:解析:
,其中θ>0为未知参数,又设(x1,x2,…,xn)是样本(X1,X2,…,Xn)的观察值,求参数θ的最大似然估计值.答案:解析:
-
第16题:
设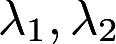 为n阶方阵A的两个互不相等的特征值,与之对应的特征向量分别为X1,X2,证明X1,X2不是矩阵A的特征向量。答案:解析:
为n阶方阵A的两个互不相等的特征值,与之对应的特征向量分别为X1,X2,证明X1,X2不是矩阵A的特征向量。答案:解析:
-
第17题:
有一个数据库X1,要求创建一个与X1库结构完全相同且不带任何记录的数据库X2,假定X1已打开,最便捷的操作应为()。
- A、COPY TO X2
- B、CREATE X2
- C、SORT ON<字段名>TO X2
- D、COPY STRU TO X2
正确答案:D -
第18题:
我们感兴趣的元素的特征称为()。
- A、样本
- B、数据集
- C、变量
- D、都不是
正确答案:C -
第19题:
响应变量Y与两个自变量(原始数据)X1及X2建立的回归方程为:Y=2.1X1+2.3X2,由此方程可以得到结论是()
- A、X1对Y的影响比X2对Y的影响要显著得多
- B、X1对Y的影响比X2对Y的影响相同
- C、X2对Y的影响比X1对Y的影响要显著得多
- D、仅由此方程不能对X1及X2对Y影响大小作出判定
正确答案:D -
第20题:
变压器的其它条件不变,若原副边的匝数同时减少10℅,则X1,X2及Xm的大小将()。
- A、X1和X2同时减少10,Xm增大
- B、X1和X2同时减少到0.81倍,Xm减少
- C、X1和X2同时减少到0.81倍,Xm增加
- D、X1和X2同时减少10℅,Xm减少
正确答案:B -
第21题:
单选题响应变量Y与两个自变量(原始数据)X1及X2建立的回归方程为y=2.2+30000x1+0.0003x2由此方程可以得到的结论是:()AX1对Y的影响比X2对Y的影响要显著得多
BX1对Y的影响与X2对Y的影响相同
CX2对Y的影响比X1对Y的影响要显著得多
D仅由此方程不能对X1及X2对Y的影响大小做出判断
正确答案: B解析: 暂无解析 -
第22题:
单选题六西格玛团队分析了历史上本车间产量(Y)与温度(X1)及反应时间(X2)的记录。建立了Y对于X1及X2的线性回归方程,并进行了ANOVA、回归系数显著性检验、相关系数计算等,证明我们选择的模型是有意义的,各项回归系数也都是显著的。下面应该进行().A结束回归分析,将选定的回归方程用于预报等
B进行残差分析,以确认数据与模型拟合得是否很好,看能否进一步改进模型
C进行响应曲面设计,选择使产量达到最大的温度及反应时间
D进行因子试验设计,看是否还有其它变量也对产量有影响,扩大因子选择的范围
正确答案: A解析: 暂无解析 -
第23题:
问答题设事故树的最小径集为{X1,X4}、{X1,X2,X5,X6}、{X2,X3,X4},求事故树的最小割集。正确答案: T=(X1+X4)(X1+X2+X5+X6)(X2+X3+X4)=X1X2+X1X3+X1X4+X2X4+X4X5+X4X6
最小径集:{X1,X2},{X1,X3},{X1,X4},{X2,X4},{X4,X5},{X4,X6}解析: 暂无解析 -
第24题:
填空题我们把一个程序在一个数据集上的一次执行称为一个()正确答案: 进程解析: 暂无解析