
单选题在有n个无序无重复元素值的数组中查找第i小的数的算法描述如下:任意取一个元素r,用划分操作确定其在数组中的位置,假设元素r为第k小的数。若i等于k,则返回该元素值;若i小于k,则在划分的前半部分递归进行划分操作找第i小的数;否则在划分的后半部分递归进行划分操作找第k-i小的数。该算法是一种基于()策略的算法。A 分治B 动态规划C 贪心D 回溯
题目
分治
动态规划
贪心
回溯
相似考题
更多“单选题在有n个无序无重复元素值的数组中查找第i小的数的算法描述如下:任意取一个元素r,用划分操作确定其在数组中的位置,假设元素r为第k小的数。若i等于k,则返回该元素值;若i小于k,则在划分的前半部分递归进行划分操作找第i小的数;否则在划分的后半部分递归进行划分操作找第k-i小的数。该算法是一种基于()策略的算法。A 分治B 动态规划C 贪心D 回溯”相关问题
-
第1题:
阅读以下算法说明,根据要求回答问题1~问题3。
[说明]
快速排序是一种典型的分治算法。采用快速排序对数组A[p..r]排序的3个步骤如下。
1.分解:选择一个枢轴(pivot)元素划分数组。将数组A[p..r]划分为两个子数组(可能为空)A[p..q-1]和A[q+1..r],使得A[q]大于等于A[p..q-1]中的每个元素,小于A[q+1..r]中的每个元素。q的值在划分过程中计算。
2.递归求解:通过递归的调用快速排序,对子数组A[p..q-1]和A[q+1..r]分别排序。
3.合并:快速排序在原地排序,故无需合并操作。
下面是快速排序的伪代码,请将空缺处(1)~(3)的内容填写完整。伪代码中的主要变量说明如下。
A:待排序数组
p,r:数组元素下标,从p到r
q:划分的位置
x:枢轴元素
i:整型变量,用于描述数组下标。下标小于或等于i的元素的值,小于或等于枢轴元素的值
j:循环控制变量,表示数组元素下标
 正确答案:这是一道考查快速排序算法伪代码的分析题。快速排序是对冒泡排序的一种改进其基本思想是:通过一趟排序将要排序的数据分割成独立的两部分其中一部分的所有数据都比另外一部分的所有数据都要小然后再按此方法对这两部分数据分别进行快速排序整个排序过程可以递归进行以此达到整个数据变成有序序列。快速排序最核心的处理是进行划分即PARTITION操作:根据枢轴元素的值把一个较大的数组分成两个较小的子数组一个子数组的所有元素的值小于等于枢轴元素的值一个子数组的所有元素的值大于枢轴元素的值而子数组内的元素不排序。划分时以最后一个元素为枢轴元素从左到右依次访问数组的每一个元素判断其与枢轴元素的大小关系并进行元素的交换如图2-30所示。
正确答案:这是一道考查快速排序算法伪代码的分析题。快速排序是对冒泡排序的一种改进其基本思想是:通过一趟排序将要排序的数据分割成独立的两部分其中一部分的所有数据都比另外一部分的所有数据都要小然后再按此方法对这两部分数据分别进行快速排序整个排序过程可以递归进行以此达到整个数据变成有序序列。快速排序最核心的处理是进行划分即PARTITION操作:根据枢轴元素的值把一个较大的数组分成两个较小的子数组一个子数组的所有元素的值小于等于枢轴元素的值一个子数组的所有元素的值大于枢轴元素的值而子数组内的元素不排序。划分时以最后一个元素为枢轴元素从左到右依次访问数组的每一个元素判断其与枢轴元素的大小关系并进行元素的交换如图2-30所示。 在[问题1]所给出的伪代码中当for循环结束后A[p..i]中的值应小于等于枢轴元素值x而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素因此A[r]与A[i+1]进行交换得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置因此返回值为i+l。
在[问题1]所给出的伪代码中当for循环结束后A[p..i]中的值应小于等于枢轴元素值x而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素因此A[r]与A[i+1]进行交换得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置因此返回值为i+l。
这是一道考查快速排序算法伪代码的分析题。快速排序是对冒泡排序的一种改进,其基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。快速排序最核心的处理是进行划分,即PARTITION操作:根据枢轴元素的值,把一个较大的数组分成两个较小的子数组,一个子数组的所有元素的值小于等于枢轴元素的值,一个子数组的所有元素的值大于枢轴元素的值,而子数组内的元素不排序。划分时,以最后一个元素为枢轴元素,从左到右依次访问数组的每一个元素,判断其与枢轴元素的大小关系,并进行元素的交换,如图2-30所示。
在[问题1]所给出的伪代码中,当for循环结束后,A[p..i]中的值应小于等于枢轴元素值x,而A[i+1..r-1]中的值应大于枢轴元素值x。此时A[i+1]是第一个比A[r]大的元素,因此A[r]与A[i+1]进行交换,得到划分后的两个子数组。PARTITION操作返回枢轴元素的位置,因此返回值为i+l。
-
第2题:
阅读下列说明、流程图和算法,将应填入(n)处的字句写在对应栏内。
【流程图说明】
下图所示的流程图5.3用N-S盒图形式描述了数组Array中的元素被划分的过程。其划分方法;以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于Array[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。

【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int Array[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组Ar ray中的下标。递归函数void sort(int Array[],int L,int H)的功能是实现数组Array中元素的递增排序。
【算法】
void sort(int Array[],int L,int H){
if (L<H) {
k=p(Array,L,H);/*p()返回基准数在数组Array中的下标*/
sort((4));/*小于基准数的元素排序*/
sort((5));/*大于基准数的元素排序*/
}
}
正确答案:(1)j←j-1
(1)j←j-1 -
第3题:
阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。 【说明】 下面的程序利用快速排序中划分的思想在整数序列中找出第k小的元素(即将元素从小到大排序后,取第k个元素)。 对一个整数序列进行快速排序的方法是:在待排序的整数序列中取第一个数作为基准值,然后根据基准值进行划分,从而将待排序的序列划分为不大于基准值者(称为左子序列)和大于基准值者(称为右子序列),然后再对左子序列和右子序列分别进行快速排序,最终得到非递减的有序序列。 例如,整数序列“19, 12, 30, 11,7,53, 78, 25"的第3小元素为12。整数序列“19,12,7,30,11,11,7,53,78,25,7"的第3小元素为7。 函数partition(int a[ ], int low,int high)以a[low]的值为基准,对a[low]、a[low+1]、…、 a[high]进行划分,最后将该基准值放入a[i] (low≤i≤high),并使得a[low]、a[low+1]、,..、 A[i-1]都小于或等于a[i],而a[i+1]、a[i+2]、..、a[high]都大于a[i]。 函教findkthElem(int a[],int startIdx,int endIdx,inr k)在a[startIdx]、a[startIdx+1]、...、a[endIdx]中找出第k小的元素。
【代码】 include <stdio.h> include <stdlib.h> Int partition(int a [ ],int low, int high) {//对 a[low..high]进行划分,使得a[low..i]中的元素都不大于a[i+1..high]中的元素。 int pivot=a[low]; //pivot表示基准元素 Int i=low,j=high; while(( 1) ){ While(i<j&&a[j]>pivot)--j; a[i]=a[j] While(i<j&&a[i]<=pivot)++i; a[j]=a[i] } (2) ; //基准元素定位 return i; } Int findkthElem(int a[ ],int startIdx,int endIdx, int k) {//整数序列存储在a[startldx..endldx]中,查找并返回第k小的元素。 if (startldx<0 ||endIdx<0 || startIdx>endIdx || k<1 ||k-1>endIdx ||k-1<startIdx) Return-1; //参数错误 if(startIdx<endldx){ int loc=partition(a, startIdx, endldx); ∥进行划分,确定基准元素的位置 if (loc==k-1) ∥找到第k小的元素 return (3) ; if(k-1 <loc) //继续在基准元素之前查找 return findkthElem(a, (4) ,k); else //继续在基准元素之后查找 return findkthElem(a, (5) ,k); } return a[startIdx]; } int main() { int i, k; int n; int a[] = {19, 12, 7, 30, 11, 11, 7, 53, 78, 25, 7}; n= sizeof(a)/sizeof(int) //计算序列中的元素个数 for (k=1;k<n+1;k++){ for(i=0;i<n;i++){ printf(“%d/t”,a[i]); } printf(“\n”); printf(“elem %d=%d\n,k,findkthElem(a,0,n-1,k));//输出序列中第k小的元素 } return 0; }
正确答案:1、i!=j或者i<j
2、a[i]=pivot
3、a[loc]
4、startIdx,loc-1
5、loc+1,endIdx
-
第4题:
●试题二
阅读下列说明、流程图和算法,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
下面的流程图(如图3所示)用N-S盒图形式描述了数组A中的元素被划分的过程。其划分方法是:以数组中的第一个元素作为基准数,将小于基准数的元素向低下标端移动,而大于基准数的元素向高下标端移动。当划分结束时,基准数定位于A[i],并且数组中下标小于i的元素的值均小于基准数,下标大于i的元素的值均大于基准数。设数组A的下界为low,上界为high,数组中的元素互不相同。例如,对数组(4,2,8,3,6),以4为基准数的划分过程如下:
【流程图】
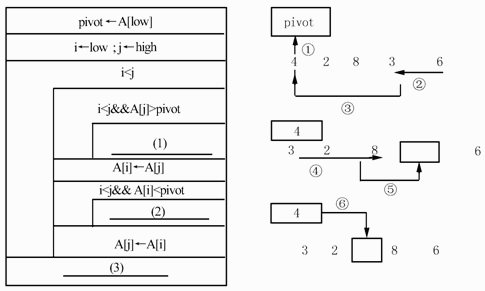
图3流程图
【算法说明】
将上述划分的思想进一步用于被划分出的数组的两部分,就可以对整个数组实现递增排序。设函数int p(int A[],int low,int high)实现了上述流程图的划分过程并返回基准数在数组A中的下标。递归函数void sort(int A[],int L,int H)的功能是实现数组A中元素的递增排序。
【算法】
void sort (int A[], int 1,int H){
if ( L<H){
k=p(A,L,R);//p()返回基准数在数组A中的下标
sort( (4) );//小于基准数的元素排序
sort( (5) );//大于基准数的元素排序
}
}
正确答案:
●试题二【答案】(1)j--(2)i++(3)A[i]←pivot或[j]←pivot(4)A,L,k-1或A,L,k(5)A,k+I,H或A,k,H【解析】题目考查快速排序算法。快速排序采用了一种分治的策略,通常称为分治法。其基本思想是:将原问题分解为若干个规模更小,但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。快速排序的具体过程为:第一步,在待排序的n个记录中任取一个记录,以该记录的排序码为基准,将所有记录分成2组,第一组各记录的排序码都小于等于该排序码,第二组各记录的排序码都大于该排序码,并把该记录排在这2组中间,这个过程称为一次划分。第二步,采用同样的方法,对划分出来的2组元素分别进行快速排序,直到所有记录都排到相应的位置为止。在进行一次划分时,若选定以第一个元素为基准,就可将第一个元素备份在变量pivot中,如图中的第①步所示。这样基准元素在数组中占据的位置就空闲出来了,因此下一步就从后向前扫描。如图中的第②步所示,找到一个比基准元素小的元素时为止,将其前移,如图中的第③步所示。然后再从前向后扫描,如图中的第④步所示,找到一个比基准元素大的元素时为止,将其后移,如图中的第⑤步所示。这样,从后向前扫描和从前向后扫描交替进行,直到扫描到同一个位置为止,如图中的第⑥步所示。由题目中给出的流程图可知,以第一个元素作为基准数,并将A[low]备份至pivot,i用于从前向后扫描的位置指示器,其初值为low,j用于从后往前扫描的位置指示器,其初值为high。当i<j时进行循环:1)从后向前扫描数组A,在i<j的情况下,如果被扫描的元素A[j]>pivot,就继续向前扫描(j--);如果被扫描的元素A[i]<pivot就停止扫描,并将此元素的值赋给目前空闲着的A[i]。2)这时,再从前向后扫描,在i<j的情况下,如果被扫描的元素A[j]<pivot,就继续向后扫描(i++);如果被扫描的元素A[j]>pivot就停止扫描,并将此元素的值赋给目前空闲着的A[j]。3)这时又接第(1)步,直到i>j时退出循环。退出循环时,将pivot赋给当前的A[i](A[i]←pivot)。递归函数的目的是执行一系列调用,直到到达某一点时递归终止。为了保证递归函数正常执行,应该遵守下面的规则:1)每当一个递归函数被调用时,程序首先应该检查基本的条件是否满足,例如,某个参数的值等于0,如果是这种情形,函数应停止递归。2)每次当函数被递归调用时,传递给函数一个或多个参数,应该以某种方式变得"更简单",即这些参数应该逐渐靠近上述基本条件。例如,一个正整数在每次递归调用时会逐渐变小,以至最终其值到达0。本题中,递归函数sort(intA[],intL,intH)有3个参数,分别表示数组A及其下界和上界。根据流程图可知,这里的L相当于流程图中的i,这里的H相当于流程图中的j。因为P()返回基准数所在数组A中的下标,也就是流程图中最后的"A[i]←pivot"中的i。根据快速排序算法,在第一趟排序后找出了基准数所在数组A中的下标,然后以该基准数为界(基准数在数组中的下标为k),把数组A分成2组,分别是A[L,…,k-1]和A[k+l,…,H],最后对这2组中的元素再使用同样的方法进行快速排序。 -
第5题:
快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于等于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了( )算法设计策略。已知确定基准元素操作的时间复杂度为Θ(n),则快速排序算法的最好和最坏情况下的时间复杂度为(请作答此空)。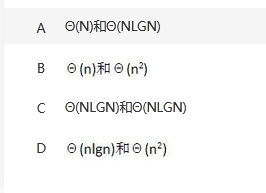 答案:D解析:快速排序采用分治法的思想。快速排序最好情况的时间复杂度是O(nlog2n)。最坏情况下,即初始序列按关键字有序或者基本有序时,快速排序的时间复杂度为O(n2)。
答案:D解析:快速排序采用分治法的思想。快速排序最好情况的时间复杂度是O(nlog2n)。最坏情况下,即初始序列按关键字有序或者基本有序时,快速排序的时间复杂度为O(n2)。 -
第6题:
若某线性表长度为n且采用顺序存储方式,则运算速度最快的操作是(37)。A.查找与给定值相匹配的元素的位置
B.查找并返回第i个元素的值(1≤i≤n)
C. 删除第i个元素(1≤i≤n)
D.在第i个元素(1≤i≤n)之前插入一个新元素答案:B解析:本题考查数据结构基础知识。
线性表(a1,a2,…,an)采用顺序存储时占用一段地址连续的存储单元,元素之间没有空闲单元,如下图所示。在这种存储方式下,插入和删除元素都需要移动一部分元素,这是比较耗时的操作。按照序号来查找元素,实际上是直接计算出元素的存储位置,例如,第i个元素ai的存储位置为LOC(ai)=LOC(a1)+(i-1)×L,其中L是每个元素所占用的存储单元数。按照值来查找元素时,需要与表中的部分元素进行比对,相对于按照序号来查找元素,需要更多的时间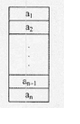
-
第7题:
若某线性表长度为n且采用顺序存储方式,则运算速度最快的操作是
( )。A.查找与给定值相匹配的元素的位置
B.查找并返回第i个元素的值(1≤i≤n)
C.删除第i个元素(1≤iD.在第i个元素(1≤i≤n)之前插入一个新元素 答案:B解析:在线性表中插入和删除元素都需要修改前驱和后继的指针。查找并返回第i个元素的值,这个只要找到该位置读取即可。查找与给定值相匹配的元素的位置,先读取第一个元素再比较,依次类推直到找到该元素。 -
第8题:
阅读下列说明和C代码,回答问题1至问题3
【说明】
??? 某应用中需要对100000个整数元素进行排序,每个元素的取值在0~5之间。排序算法的基本思想是:对每一个元素x,确定小于等于x的元素个数(记为m),将x放在输出元素序列的第m个位置。对于元素值重复的情况,依次放入第m-l、m-2、…个位置。例如,如果元素值小于等于4的元素个数有10个,其中元素值等于4的元素个数有3个,则4应该在输出元素序列的第10个位置、第9个位置和第8个位置上。算法具体的步骤为:
步骤1:统计每个元素值的个数。
步骤2:统计小于等于每个元素值的个数。
步骤3:将输入元素序列中的每个元素放入有序的输出元素序列。
【C代码】
下面是该排序算法的C语言实现。
(1)常量和变量说明
R: 常量,定义元素取值范围中的取值个数,如上述应用中R值应取6
i:循环变量
n:待排序元素个数
a:输入数组,长度为n
b:输出数组,长度为n
c:辅助数组,长度为R,其中每个元素表示小于等于下标所对应的元素值的个数。
(2)函数sort
1??? void sort(int n,int a[],int b[]){
2??? ???int c[R],i;
3?? for (i=0;i< ???(1)? :i++){
4?? ??c[i]=0;
5??? ???}
6??? ???for(i=0;i
8??? ???}
9 ??for(i=1;i
11??? ??}
12 ?for(i=0;i
14??? c[a[i]]=c[a[i]]-1;
15??? ??}
16??? }
【问题1】
? 根据说明和C代码,填充C代码中的空缺(1)~(4)。
【问题2】
根据C代码,函数的时间复杂度和空间复杂度分别为 (5) 和 (6) (用O符号表示)。
【问题3】?
? 根据以上C代码,分析该排序算法是否稳定。若稳定,请简要说明(不超过100字);若不稳定,请修改其中代码使其稳定(给出要修改的行号和修改后的代码)。答案:解析:试题答案 【问题1】
(1)R
(2)c[a[i]]+1
(3)c[i]+c[i -1]
(4)a[i]
【问题2】
(5)O(n+R)或者O(n)或n或线性
(6)O(n+R)或者O(n)或n或线性
【问题3】
不稳定。修改第12行的for循环为:for(i=n-1;i>=0;i--){ 即可。 -
第9题:
在n个数的数组中确定其第i(1≤i≤n)小的数时,可以采用快速排序算法中的划分思想,对n个元素划分,先确定第k小的数,根据i和k的大小关系,进一步处理,最终得到第i小的数。划分过程中,最佳的基准元素选择的方法是选择待划分数组的(64)元素。此时,算法在最坏情况下的时间复杂度为(不考虑所有元素均相等的情况)(65)。A.第一个
B.最后一个
C.中位数
D.随机一个答案:C解析:本题考查数据结构基础知识。快速排序一种分治的排序方法,其思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。快速排序的每一趟结果都是找到一个基准元素放置于线性表中部位置,将原来的线性表划分为前后两部分,前部分元素都小于基准元素,后部分元素都大于基准元素。快速排序总的关键字比较次数为Θ(nlog2n),最坏情况下时间复杂度为Θ(n2),最好情况下的时间复杂度为Θ(nlog2n);快速排序是不稳定的排序。最坏情况下需要的栈空间为Θ(n),其他需要Θ(nlog2n)。根据以上描述,本题依次选C、D选项。 -
第10题:
在有n个无序无重复元素值的数组中查找第i小的数的算法描述如下:任意取一个元素r,用划分操作确定其在数组中的位置,假设元素r为第k小的数。若i等于k,则返回该元素值;若i小于k,则在划分的前半部分递归进行划分操作找第i小的数;否则在划分的后半部分递归进行划分操作找第k-i小的数。该算法是一种基于()策略的算法。
- A、分治
- B、动态规划
- C、贪心
- D、回溯
正确答案:A -
第11题:
在寻找n个元素中第k小元素问题中,若使用快速排序算法思想,运用分治算法对n个元素进行划分,应如何选择划分基准?下面()答案解释最合理。
- A、随机选择一个元素作为划分基准
- B、取子序列的第一个元素作为划分基准
- C、用中位数的中位数方法寻找划分基准
- D、以上皆可行。但不同方法,算法复杂度上界可能不同
正确答案:D -
第12题:
单选题在寻找n个元素中第k小元素问题中,如使用快速排序算法思想,运用分治算法对n个元素进行划分,应如何选择划分基准?下面()答案解释最合理。A随机选择一个元素作为划分基准
B取子序列的第一个元素作为划分基准
C用中位数的中位数方法寻找划分基准
D以上皆可行。但不同方法,算法复杂度上界可能不同
正确答案: B解析: 暂无解析 -
第13题:
试题四(共15 分)
阅读下列说明和C代码,回答问题 1 至问题3,将解答写在答题纸的对应栏内。
【说明】
某应用中需要对100000 个整数元素进行排序,每个元素的取值在 0~5 之间。排序算法的基本思想是:对每一个元素 x,确定小于等于 x的元素个数(记为m),将 x放在输出元素序列的第m 个位置。对于元素值重复的情况,依次放入第 m-l、m-2、…个位置。例如,如果元素值小于等于4 的元素个数有 10 个,其中元素值等于 4 的元素个数有3个,则 4 应该在输出元素序列的第10 个位置、第 9 个位置和第8 个位置上。
算法具体的步骤为:
步骤1:统计每个元素值的个数。
步骤2:统计小于等于每个元素值的个数。
步骤3:将输入元素序列中的每个元素放入有序的输出元素序列。
【C代码】
下面是该排序算法的C语言实现。
(1)常量和变量说明
R:常量,定义元素取值范围中的取值个数,如上述应用中 R值应取6i:循环变量
n:待排序元素个数
a:输入数组,长度为n
b:输出数组,长度为n
c:辅助数组,长度为R,其中每个元素表示小于等于下标所对应的元素值的个数。
(2)函数sort
1 void sort(int n,int a[ ],intb[ ]){
2 int c[R],i;
3 for (i=0;i< (1) ;i++){
4 c[i]=0;
5 }
6 for(i=0;i<n;i++){
7 c[a[i]] = (2) ;
8 }
9 for(i=1;i<R;i++){
10 c[i]= (3) ;
11 }
12 for(i=0;i<n;i++){
13 b[c[a[i]]-1]= (4) ;
14 c[a[i]]=c[a[i] ]-1;
15 }
16 }
【问题1】(8 分)
根据说明和C代码,填充 C代码中的空缺(1)~(4)。
【问题2】(4 分)
根据C代码,函数的时间复杂度和空间复杂度分别为 (5) 和 (6) (用 O符号
表示)。
【问题3】(3 分)
根据以上C代码,分析该排序算法是否稳定。若稳定,请简要说明(不超过 100 字);
若不稳定,请修改其中代码使其稳定(给出要修改的行号和修改后的代码)。
从下列的2 道试题(试题五和试题六)中任选 1 道解答。
如果解答的试题数超过 道,则题号小的 道解答有效。
正确答案:
试题四参考答案(共15分)
【问题1】(8分)
(1)R
(2)c[a[i]]+l
(3)c[i]+c[i -1]
(4)a[i]
【问题2】(4分)
(5)O(n+R)或者O(n)或n或线性
(6)O(n+R)或者O(n)或n或线性
【问题3】(3分)
不稳定。修改第12行的for循环为:for(i=n-1;i>=0;i--){即可。 -
第14题:
若某线性表长度为n且采用顺序存储方式,则运算速度最快的操作是( )。
A.查找与给定值相匹配的元素的位置B.查找并返回第i个元素的值(1≤i≤n)C.删除第i个元素(1≤i≤n)D.在第i个元素(1≤i≤n )之前插入一个新元素
正确答案:B
-
第15题:
快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于等于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了 (61) 算法设计策略。已知确定基准元素操作的时间复杂度为
 ,则快速排序算法的最好和最坏情况下的时间复杂度为 (62) 。
,则快速排序算法的最好和最坏情况下的时间复杂度为 (62) 。A.分治
B.动态规划
C.贪心
D.回溯
正确答案:A
本题考查快速排序算法。快速排序算法是应用最为广泛的排序算法之一。其基本思想是将n个元素划分为两个部分:一部分元素值小于某个数;另一部分元素值大于某个数,该数的位置确定;然后进一步划分前面部分和后面部分。根据该叙述,可以知道,这里采用的是分治算法设计策略。由于已知划分操作的时间复杂度为,不需要合并子问题的答案。对于最好的情况,应该是每次划分都把n个元素划分为大约2个n/2个元素的子数组,此时T(n)=2T(n/2)+解该递归式,可得时间复杂度为。若刚好划分的极度不均衡,即每个划分刚好把n个元素划分为一边0个元素,一边n-l个元素,此时T(n)=T(n/1)+解该递归式,可得时间复杂度为。 -
第16题:
快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于等于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了(请作答此空)算法设计策略。已知确定基准元素操作的时间复杂度为Θ(n),则快速排序算法的最好和最坏情况下的时间复杂度为( )。A.分治
B.动态规划
C.贪心
D.回溯答案:A解析:快速排序采用分治法的思想。快速排序最好情况的时间复杂度是O(nlog2n)。最坏情况下,即初始序列按关键字有序或者基本有序时,快速排序的时间复杂度为O(n2)。 -
第17题:
阅读以下说明和代码,填补代码中的空缺,将解答填入答题纸的对应栏内。【说明】下面的程序利用快速排序中划分的思想在整数序列中找出第 k 小的元素(即 将元素从小到大排序后,取第 k 个元素)。对一个整数序列进行快速排序的方法是:在待排序的整数序列中取第一个数 作为基准值,然后根据基准值进行划分,从而将待排序的序列划分为不大于基准 值者(称为左子序列)和大于基准值者(称为右子序列),然后再对左子序列和 右子序列分别进行快速排序,最终得到非递减的有序序列。例如,整数序列“19, 12, 30, 11,7,53, 78, 25"的第 3 小元素为 12。整数序列“19, 12,7,30, 11, 11,7,53. 78, 25, 7"的第 3 小元素为 7。函数 partition(int a[], int low,int high)以 a[low]的值为基准,对 a[low]、 a[low+l]、…、a[high]进行划分,最后将该基准值放入 a[i] (low≤i≤high),并 使得 a[low]、a[low+l]、,..、A[i-1]都小于或等于 a[i],而 a[i+l]、a[i+2]、..、 a[high]都大于 a[i]。函 教 findkthElem(int a[],int startIdx,int endIdx,inr k) 在 a[startIdx] 、 a[startIdx+1]、...、a[endIdx]中找出第 k 小的元素。【代码】#include#include
Int partition(int a [],int low, int high){//对 a[low..high]进行划分,使得 a[low..i]中的元素都不大于 a[i+1..high]中的 元素。int pivot=a[low]; //pivot 表示基准元素 Int i=low,j=high;while(( 1) ){While(i答案:解析:1) CountStr
2) p[i]
3) p[i]
4) num 3、
1、!i=j
2、a[i]=pivot
3、a[loc]
4、stratIdx,Loc-1
5、Loc+1,endIdx -
第18题:
快速排序算法是,在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了 (请作答此空) 算法设计策略。已知确定着基准元素操作的时间复杂度为O(n),则快速排序算法的最好和最坏情况下的时间复杂度为 ( ) 。A.分治
B.动态规划
C.贪心
D.回溯答案:A解析:将数据分成若干份,每份单独处理后再合并,其思想为分治。
理想情况下,快速排序每次将数据划分为规模相近的两部分,并递归至不可再划分,因此其时间复杂度为O(nlgn)。在最坏情况下,每次划分都极不均匀,如一个类别中仅有一个元素,另一个类别中包含剩余所有元素。这时划分的复杂度为O(n),次操作的总复杂度为O(n2)。 -
第19题:
快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了(61)算法设计策略。已知确定着基准元素操作的时间复杂度为O(n),则快速排序算法的最好和最坏情况下的时间复杂度为(62)。A.分治
B.动态规划
C.贪心
D.回溯答案:A解析:将数据分成若干份,每份单独处理后再合并,其思想为分治。理想情况下,快速排序每次将数据划分为规模相近的两部分,并递归至不可再划分,因此其时间复杂度为O(nlgn)。在最坏情况下,每次划分都极不均匀,如一个类别中仅有一个元素,另一个类别中包含剩余所有元素。这时划分的复杂度为O(n),”次操作的总复杂度为O(n2)。 -
第20题:
在n个数的数组中确定其第i(1≤i≤n)小的数时,可以采用快速排序算法中的划分思想,对n个元素划分,先确定第k小的数,根据i和k的大小关系,进一步处理,最终得到第i小的数。划分过程中,最佳的基准元素选择的方法是选择待划分数组的(64)元素。此时,算法在最坏情况下的时间复杂度为(不考虑所有元素均相等的情况)(65)。A.Θ(n)
B.Θ(lgn)
C.Θ(nlgn)
D.Θ(n2)答案:D解析:本题考查数据结构基础知识。快速排序一种分治的排序方法,其思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。快速排序的每一趟结果都是找到一个基准元素放置于线性表中部位置,将原来的线性表划分为前后两部分,前部分元素都小于基准元素,后部分元素都大于基准元素。快速排序总的关键字比较次数为Θ(nlog2n),最坏情况下时间复杂度为Θ(n2),最好情况下的时间复杂度为Θ(nlog2n);快速排序是不稳定的排序。最坏情况下需要的栈空间为Θ(n),其他需要Θ(nlog2n)。根据以上描述,本题依次选C、D选项。 -
第21题:
快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于等于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了()算法设计策略。
- A、分治
- B、动态规划
- C、贪心
- D、回溯
正确答案:A -
第22题:
在寻找n个元素中第k小元素问题中,如快速排序算法思想,运用分治算法对n个元素进行划分,如何选择划分基准?下面()答案解释最合理。
- A、随机选择一个元素作为划分基准
- B、取子序列的第一个元素作为划分基准
- C、用中位数的中位数方法寻找划分基准
- D、以上皆可行。但不同方法,算法复杂度上界可能不同
正确答案:D -
第23题:
单选题在有n个无序无重复元素值的数组中查找第i小的数的算法描述如下:任意取一个元素r,用划分操作确定其在数组中的位置,假设元素r为第k小的数。若i等于k,则返回该元素值;若i小于k,则在划分的前半部分递归进行划分操作找第i小的数;否则在划分的后半部分递归进行划分操作找第k-i小的数。该算法是一种基于()策略的算法。A分治
B动态规划
C贪心
D回溯
正确答案: A解析: 分治算法的基本思想是将一个难以直接解决的大问题分解成一些规模较小的小问题以便各个击破,分而治之。分治算法的每一层都有3个步骤:分解、求解和合并。本题的查找算法,不断划分数组,缩小查找范围,可见该算法是基于分治策略的算法。 -
第24题:
单选题快速排序算法在排序过程中,在待排序数组中确定一个元素为基准元素,根据基准元素把待排序数组划分成两个部分,前面一部分元素值小于等于基准元素,而后面一部分元素值大于基准元素。然后再分别对前后两个部分进一步进行划分。根据上述描述,快速排序算法采用了()算法设计策略。A分治
B动态规划
C贪心
D回溯
正确答案: A解析: 暂无解析