
设线性链表的存储结构如下: struct node {ELEMTP data; /*数据域*/ struct node *next; /*指针域*/ } 试完成下列在链表中值为x的结点前插入一个值为y的新结点。如果x值不存在,则把新结点插在表尾的算法。 void inserty(struct node *head,ELEMTP x,ELEMTP y) {s=(struct node *)malloc(sizeof(struct node)); (); if(){s->nexr=head;head=s;}
题目
设线性链表的存储结构如下: struct node {ELEMTP data; /*数据域*/ struct node *next; /*指针域*/ } 试完成下列在链表中值为x的结点前插入一个值为y的新结点。如果x值不存在,则把新结点插在表尾的算法。 void inserty(struct node *head,ELEMTP x,ELEMTP y) {s=(struct node *)malloc(sizeof(struct node)); (); if(){s->nexr=head;head=s;} else { q=head;p=q->next; while(p->dqta!=x&&p->next!=NULL){q=p;()} if(p->data= = x){q->next=s;s->next=p;} else{p->next=s;s->next=NULL;} } }
相似考题
参考答案和解析
更多“设线性链表的存储结构如下: struct node {ELEM”相关问题
-
第1题:
下面函数的功能是将指针t2所指向的线性链表,链接到t1所指向的链表的末端。假定t1所指向的链表非空
struct node{ float x;struct node *next;};
connect(struct node *t1, struct node *t2)
{ if(t1->next==NULL)t1->next=t2;
else connect(______ ,t2); }
要实现此功能则应该添入的选项是
A.t1.next
B.++t1.next
C.t1->next
D.++t1->next
正确答案:C
-
第2题:
在C语言中,可以用typedef声明新的类型名来代替已有的类型名,比如有学生链表结点: typedef struct node{ int data; struct node * link; }NODE, * LinkList; 下述说法正确的是______。
A.NODE是结构体struct node的别名
B.* LinkList也是结构体struct node的别名
C.LinkList也是结构体struct node的别名
D.LinkList等价于node*
正确答案:A
解析:其实题中的定义相当于下述两个定义:typedefstructnode{intdata;structnode*link;}NODE;typedefstructnode{intdata;structnode*link;)*LinkList;前者给structnode取了个新名字NODE,即structnode和NODE是等价的;后者把structnode*命名为LinkList。 -
第3题:
阅读下列说明和C函数,将应填入(n)处的字句写在对应栏内。
【说明】
已知集合A和B的元素分别用不含头结点的单链表存储,函数Difference()用于求解集合A与B的差集,并将结果保存在集合A的单链表中。例如,若集合A={5,10, 20,15,25,30},集合B={5,15,35,25},如图(a)所示,运算完成后的结果如图(b)所示。

链表结点的结构类型定义如下:
typedef struct Node{
ElemType elem;
struct Node *next;
}NodeType;
【C函数】
void Difference(NodeType **LA,NodeType *LB)
{
NodeType *pa, *pb, *pre, *q;
pre=NULL;
(1);
while (pa) {
pb=LB;
while((2))
pb=pb->next;
if((3)) {
if(!pre)
*LA=(4);
else
(5)=pa->next;
q = pa;
pa=pa->next;
free(q);
}
else {
(6);
pa=pa->next;
}
}
}
正确答案:(1)pa=*LA (2)pb && pb->elem!=pa->elem或其等价表示 (3)pb或pb!=NULL (4)pa->next或(*pa).next或其等价表示 (5)pre->next或(*pre).next (6)pre=pa
(1)pa=*LA (2)pb && pb->elem!=pa->elem,或其等价表示 (3)pb或pb!=NULL (4)pa->next,或(*pa).next,或其等价表示 (5)pre->next,或(*pre).next (6)pre=pa 解析:本题考查链表结构上的基本运算。
集合A与B的差是指在集合A中而不在集合B中的元素。本题用链表表示集合并将运算结果用表示集合A的链表存储,因此涉及到链表上的查找、删除基本运算。
基本思路为:对于集合A中的每个元素,在集合B中进行查找,若找到,则应将该元素从集合A中去掉;否则保留,用两层循环实现,外层循环用于遍历集合A,内层循环遍历集合B。
代码中的指针pa用于指向集合A的元素;pb指向集合B的元素;临时指针q指向需要被删除的元素;pre用于实现删除时结点的链接,与pa保持所指结点的前后继关系。
显然,pa需要一个初始值,即指向集合A的第一个元素结点。由于参数LA是指向集合A第一个结点的指针的指针,因此空(1)处应填入pa=*LA。
在内层循环中遍历集合B时,初始时令pb指向B的第一个元素(pb=LB),此后应在链表中查找与A中当前元素相同者,因此空(2)处应填入pb && pb->elem != pa->elem。
此后,应判断在B中是否找到指定元素。显然,若找到(即pb->elem=pa->elem),则指针pb不为空,否则,pb为空。因此,空(3)处填入pb或pb!=NULL,空(6)处则填入pre=pa。
由于链表不带头结点,因此,当需要删除集合A的第一个元素时,表示该集合的链表头指针会被修改。pre初始值为NULL,可标志删除的是否为A的第一个元素。因此查找成功时,pre为空(!pre成立)表示需要删除A的第一个元素(pa指针所指),使得 A的头指针指向第二个元素,即应将*LA更新为pa->next,空(4)处填入pa->next。如果删除的不是第一个元素,则由于pa指向被删除的元素,而且pre与pa所指元素保持前后继关系,因此空(5)处应填入pre->next。 -
第4题:
已知形成链表的存储结构如下图所示,则下述类型描述中的空白处应填______。 struct link { char data; ______; }node;

A.struct link next
B.link * next
C.struct next link
D.struct link *next
正确答案:D
解析:在单向链表中,由于每个结点需要存储下一个结点的地址,且下一个结点的数据类型与前一个结点的数据类型完全相同,故应为structlink*next。 -
第5题:
阅读以下说明和程序流程图,将应填入(n)处的字句写在对应栏内。
[说明]
当一元多项式
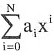 中有许多系数为零时,可用一个单链表来存储,每个节点存储一个非零项的指受和对应系数。
中有许多系数为零时,可用一个单链表来存储,每个节点存储一个非零项的指受和对应系数。为了便于进行运算,用带头节点的单链表存储,头节点中存储多项式中的非零项数,且各节点按指数递减顺序存储。例如:多项式8x5-2x2+7的存储结构为:

流程图图3-1用于将pC(Node结构体指针)节点按指数降序插入到多项式C(多项式POLY指针)中。
流程图中使用的符号说明如下:
(1)数据结构定义如下:
define EPSI 1e-6
struct Node{ /*多项式中的一项*/
double c; /*系数*/
int e; /*指数*/
Struct Node *next;
};
typedef struct{ /*多项式头节点*/
int n; /*多项式不为零的项数*/
struct Node *head;
}POLY;
(2)Del(POLY *C,struct Node *p)函数,若p是空指针则删除头节点,否则删除p节点的后继。
(3)fabs(double c)函数返回实数C的绝对值。
[图3-1]
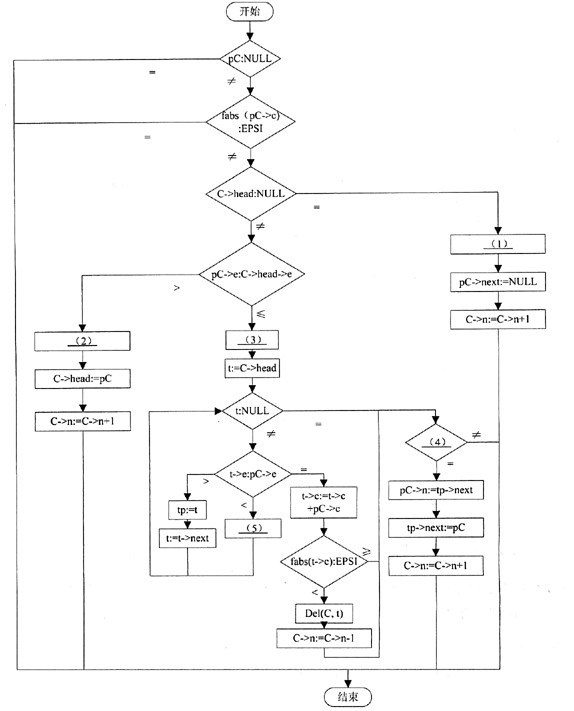
(1)
正确答案:C->head:=Pc
C->head:=Pc -
第6题:
已知形成链表的存储结构如下图所示,则下述类型描述中的空白处应填______。 struct 1ink { char data; }node;
A.struct link next
B.link*next
C.sluct next link
D.struct link*next
正确答案:D
解析:在单向链表中,由于每个结点需要存储下—个结点的地址,且下—个结点的数据类型与前—个结点的数据类型完全相同,故应为strect link*next。 -
第7题:
下列叙述不属于线性链表较之线性表顺序存储结构的优点的是( )。
A.线性链表存储方式简单
B.线性链表运算效率高
C.线性链表的存储空间易于扩展
D.线性链表便于存储空间的动态分配
正确答案:A
解析:线性链表存储方式要求每个数据节点由两个部分组成,比线性表的顺序存储结构复杂,选项A是错误的。在平均情况下,线性表的顺序存储结构插入和删除元素需要移动线性表中约一半的元素,效率低下。而线性链表只需改变有关节点的指针,效率较高,选项B是正确的。线性表的顺序存储存储空间必须是连续的,不利于存储空间扩展;而线性链表不需要连续的存储空间,存储空间易于扩展,选项C是正确的。为保证线性表的存储空间连续且顺序分配,会导致在对某个线性表进行动态分配存储空间时,必须.要移动其他线性表中的数据元素,不便于存储空间的动态分配,选项D是正确的。 -
第8题:
[说明]
已知包含头节点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的节点。
图8-29(a)、(b)是经函数compress( )处理前后的链表结构示例图。

链表的节点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
}NODE;
[C语言函数]
void compress(NODE *head)
{
NODE *ptr, *q;
ptr= (1) ; /*取得第一个元素节点的指针*/
while( (2) && ptr->next) {
q=ptr ->next;
while(q && (3) ){/*处理重复元素*/
(4) =q ->next;
free(q);
q=ptr->next;
}
(5) =ptr->next;
} /*end of while*/
} /*end of compress*/
正确答案:head>next ptr ptr->data==q->data或其等价形式 ptr->next ptr
head>next ptr ptr->data==q->data或其等价形式 ptr->next ptr 解析:本题考查的是对链表的查找、插入和删除等运算。要找到重复的元素并将其删除而使各元素互不相同。我们可以顺序遍历链表,比较逻辑上相邻的两个元素是否相同,如果相同则删除后一个元素,以此类推。代码如下:
VOid Compress(NODE *head)
{
NODE *ptr, *q;
ptr=head->next; /*取得第一个元素节点的指针*/
while(ptr && ptr->next){
q=ptr->next;
while(q && ptr->data==q>data){/*处理重复元素*/
ptr->next=q->next;
free(q);
q=ptr->next;
}
ptr=ptr->next;
}/*end of while*/
}/*end of compress*/ -
第9题:
下面正确定义了仅包含一个数据成员info的单链表的结点类型。struct node { int info;struct node next;} ()此题为判断题(对,错)。
正确答案:错误
-
第10题:
链表与线性表的关系是()。
- A、链表是线性表采用链式存储结构。
- B、链表是线性表采用顺序存储结构。
- C、链表等价于线性表
- D、链表和顺序表都不是线性表
正确答案:A -
第11题:
问答题设某带头结头的单链表的结点结构说明如下:typedef struct nodel{int data struct nodel*next;}node;试设计一个算法:void copy(node*headl,node*head2),将以head1为头指针的单链表复制到一个不带有头结点且以head2为头指针的单链表中。正确答案: 一边遍历,一边申请新结点,链接到head2序列中。解析: 暂无解析 -
第12题:
填空题设线性链表的存储结构如下: struct node {ELEMTP data; /*数据域*/ struct node *next; /*指针域*/ } 试完成下列在链表中值为x的结点前插入一个值为y的新结点。如果x值不存在,则把新结点插在表尾的算法。 void inserty(struct node *head,ELEMTP x,ELEMTP y) {s=(struct node *)malloc(sizeof(struct node)); (); if(){s->nexr=head;head=s;} else { q=head;p=q->next; while(p->dqta!=x&&p->next!=NULL){q=p;()} if(p->data= = x){q->next=s;s->next=p;} else{p->next=s;s->next=NULL;} } }正确答案: s->data=y,head->data= =x,p=p->next解析: 暂无解析 -
第13题:
以下程序中函数fun的功能是:构成一个如图所示的带头结点的单词链表,在结点的数据域中放入了具有两个字符的字符串。函数disp的功能是显示输出该单链表中所有结点中的字符串。请填空完成函数disp。[*]
include<stdio.h>
typedef struct node /*链表结点结构*/
{char sub[3];
struct node *next;
}Node;
Node fun(char s) /*建立链表*/
{ … }
void disp(Node *h)
{ Node *
正确答案:
-
第14题:
函数min()的功能是:在带头结点的单链表中查找数据域中值最小的结点。请填空includestruc 函数min()的功能是:在带头结点的单链表中查找数据域中值最小的结点。请填空
include <stdio.h>
struct node
{ int data;
struct node *next;
};
int min(struct node *first)/*指针first为链表头指针*/
{ struct node *p; int m;
p=first->next; re=p->data; p=p->next;
for( ;p!=NULL;p=【 】)
if(p->data<m ) re=p->data;
return m;
}
正确答案:p->next
p->next 解析:本题考查的知识点是:链表的筛选。题目要求筛选出链表中最小的值,所以需要先定义一个临时变量,并将第1个值赋给该变量,就好像本题程序中定义的变量 m。然后遍历整个链表,拿链表中的每一个值跟m比较,如果找到比m小的值,就让m等于该值,这样遍历结束后,m中就是该链表的最小值了。题目中的空位于for循环的第3个表达式处,这里的for循环就是用来遍历整个链表的,所以该表达式需要完成的任务是:将循环变量p指向当前结点的下一个结点。故不难得知应填p->next。 -
第15题:
以下程序的功能是:建立一个带有头结点的甲—向链表,并将存储在数组中的字符依次转存到链表的各个结点中,请从与下划线处号码对应的一组选项中选择出正确的选项。
#include <stdlib.h>
struct node
{ char data; struct node *next: };
(1) CreatList(char *s)
{
struct node *h,*p,*q;
h = (struct node *)malloc sizeof(struct node));
p=q=h;
while(*s! ='\0')
{
p = (struct node *)malloc(sizeof (struct node));
p->data = (2) ;
q->next = p;
q - (3) ;
S++;
}
p->next='\0';
return h;
}
main()
{
char str[]="link list";
struct node *head;
head = CreatList(str);
}
(1)
A.char*
B.struct node
C.struct node*
D.char
正确答案:C
-
第16题:
以下程序的功能是:建立一个带有头结点的单向链表,并将存储在数组中的字符依次转储到链表的各个结点中,请从与下划线处号码对应的一组选若中选择出正确的选项。#include stuct node{ char data; struct node *next;}; (48) CreatLis(char *s){ struct node *h,*p,*q); h=(struct node *)malloc(sizeof(struct node)); p=q=h; while(*s!='\0') { p=(struct node *)malloc(sizeof(struct node)); p->data= (49) ; q->next=p; q= (50) ; s++; } p->next='\0'; return h;}main(){ char str[]="link list"; struct node *head; head=CreatLis(str); ...}
A.char *
B.struct node
C.struct node*
D.char
正确答案:C
解析:CreateList( )函数在最后返回h,而h是structn。node*类型的变量。 -
第17题:
阅读以下说明和C语言函数,将应填入(n)。
【说明】
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
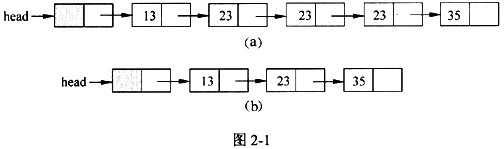
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}NODE;
【C语言函数】
void compress(NODE *head)
{ NODE *ptr,*q;
ptr= (1); /*取得第一个元素结点的指针*/
while( (2)&& ptr->next) {
q=ptr->next;
while(q&&(3)) { /*处理重复元素*/
(4)q->next;
free(q);
q=ptr->next;
}
(5) ptr->next;
}/*end of while */
}/*end of compress*/
正确答案:(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data或其等价表示 (4)ptr->next (5)ptr
(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data,或其等价表示 (4)ptr->next (5)ptr 解析:本题考查基本程序设计能力。
链表上的查找、插入和删除运算是常见的考点。本题要求去掉链表中的重复元素,使得链表中的元素互不相同,显然是对链表进行查找和删除操作。
对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以采用两种思路。
1.顺序地遍历链表,对于逻辑上相邻的两个元素,比较它们是否相同,若相同,则删除后一个元素的结点,直到表尾。代码如下:
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){ /*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data){/*处理重复元素*/
ptr->next=q->next;/*将结点从链表中删除*/
free(q);
q=ptr->next; /*继续扫描后继元素*/
}
ptr=ptr->next;
}
2.对于每一组重复元素,先找到其中的第一个结点,然后向后查找,直到出现一个相异元素时为止,此时保留重复元素的第一个结点,其余结点则从链表中删除。
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){/*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data) /*查找重复元素*/
q=q->next;
s=ptr->next; /*需要删除的第一个结点*/
ptr->next=q; /*保留重复序列的第一个结点,将其余结点从链表中删除*/
while(s && s!=q}{/*逐个释放被删除结点的空间*/
t = s->next;free(s);s = t;
}
ptr=ptr->next;
}
题目中采用的是第一种思路。 -
第18题:
链表题:一个链表的结点结构
struct Node
{
int data ;
Node *next ;
};
typedef struct Node Node ;
(1)已知链表的头结点head,写一个函数把这个链表
逆序( Intel)
正确答案:
Node * ReverseList(Node *head) //链表逆序
{
if ( head == NULL || head->next == NULL )
return head;
Node *p1 = head ;
Node *p2 = p1->next ;
Node *p3 = p2->next ;
p1->next = NULL ;
while ( p3 != NULL )
{
p2->next = p1 ;
p1 = p2 ;
p2 = p3 ;
p3 = p3->next ;
}
p2->next = p1 ;
head = p2 ;
return head ;
} -
第19题:
以下程序中函数fun的功能是:构成—个如图所示的带头结点的单向链表,在结点的数据域中放入了具有两个字符的字符串。函数disp的功能是显示输出该单向链表中所有结点中的字符串。请填空完成函数disp。

include<stdio.h>
typedef struct node /*链表结点结构*/
{ char sub[3];
struct node *next;
}Node;
Node fun(char s) /* 建立链表*/
{ ...... }
void disp(Node *h)
{ Node *p;
p=h->next;
while([ ])
{printf("%s\n",p->sub);p=[ ];}
}
main()
{ Node *hd;
hd=fun(); disp(hd);printf("\n");
}
正确答案:p!=NULL 或 p 或 p!=0 或 p!='0' p->next 或 (*P).next
p!=NULL 或 p 或 p!=0 或 p!='0' p->next 或 (*P).next 解析:此题主要考核的是用指针处理链表。自定义结构体类型名为Node,并定义一个指向结点类型的指针next。用Node来定义头结点指针变量h,并定义另—个指针变量p指向了第—个结点,在满足p未指向最后—个结点的空指针时,输出p所指向结点的字符串,所以第—个空填p!=NULL或p或p!=0或p!='\0',然后将p指向下一个非空结点,所以第二个空填p->next或与其等效的形式,反复执行直到所有的结点都输出,即遇到p的值为NULL。 -
第20题:
已知形成链表的存储结构如下图所示,则下述类型描述中的空白处应填______。 struct link { char data; ______, }node;
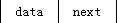
A.struct link next
B.link *next
C.stuct next link
D.struct link *next
正确答案:D
解析:在单向链表中,由于每个结点需要存储下一个结点的地址,且下—个结点的数据类型与前—个结点的数据类型完全相同,故应为structlink*next。 -
第21题:
以下程序的功能是:建立一个带有头结点的单向链表,并将存储在数组中的字符依次转存到链表的各个结点中,请填空。 #include <stdlib.h> stuct node { char data; struet node * next; }; stntct node * CreatList(char * s) { struet node *h,*p,*q; h = (struct node * ) malloc(sizeof(struct node) ); p=q=h; while( * s! ='\0') { p = (struct node *) malloc ( sizeof(struct node) ); p - > data = ( ) q- >next=p; q=p; a++; p- > next ='\0'; return h; } main( ) { char str[ ]= "link list"; struet node * head; head = CreatList(str);
A.*s
B.s
C.*s++
D.(*s)++
正确答案:A
解析:本题要求建立一个stmctnode类型的数据链表,函数CreatList将字符串"linklist"的首地址传给指针变量s,可以推断建立的链表一定与"linklist",有关,由CreatList(char*s)函数中所定义的变量及其他语句可知,h,p,q用于建立的链表,h表示头指针,p用于记录开辟的新结点,而q用作将新结点与已建立的链表相连的中间变量,所建立链表各个结点的data依次存放的是”linklist",中的各个字符,所以应填空*s。 -
第22题:
填空题设顺序存储的线性表存储结构定义为: struct sequnce {ELEMTP elem[MAXSIZE]; int len; /*线性表长度域*/ } 将下列简单插入算法补充完整。 void insert(struct sequnce *p,int i,ELEMTP x) {v=*p; if(iv.len+1)printf(“Overflow“); else { for(j=v.len;();j- -)(); v.elem[i]= () ;v.len=(); } }正确答案: j>=i,v.elem[j+1]=v.elem[j],x,v.len+1解析: 暂无解析 -
第23题:
单选题链表与线性表的关系是()。A链表是线性表采用链式存储结构。
B链表是线性表采用顺序存储结构。
C链表等价于线性表
D链表和顺序表都不是线性表
正确答案: C解析: 暂无解析 -
第24题:
填空题设线性链表的存储结构如下: struct node {ELEMTP data; /*数据域*/ struct node *next; /*指针域*/ } 试完成下列建立单链表的算法。 creat() {char var; head=(struct node *)malloc(sizeof(struct node)); head->next= () ; while((var=getchar())!=‘/n’){ ptr=( struct node *)malloc(sizeof(struct node)); ptr->data= var ;ptr->next=head->next; head->next= ptr ; } }正确答案: NULL解析: 暂无解析